It is frequently suggested that once one of the AI companies reaches an AGI threshold, they will take off ahead of the rest. It's interesting to note that at least so far, the trend has been the opposite: as time goes on and the models get better, the performance of the different company's gets clustered closer together. Right now GPT-5, Claude Opus, Grok 4, Gemini 2.5 Pro all seem quite good across the board (ie they can all basically solve moderately challenging math and coding problems).
As a user, it feels like the race has never been as close as it is now. Perhaps dumb to extrapolate, but it makes me lean more skeptical about the hard take-off / winner-take-all mental model that has been pushed.
Would be curious to hear the take of a researcher at one of these firms - do you expect the AI offerings across competitors to become more competitive and clustered over the next few years, or less so?
It's also worth considering that past some threshold, it may be very difficult for us as users to discern which model is better. I don't think thats what's going on here, but we should be ready for it. For example, if you are an ELO 1000 chess player would you yourself be able to tell if Magnus Carlson or another grandmaster were better by playing them individually? To the extent that our AGI/SI metrics are based on human judgement the cluster effect that they create may be an illusion.
> For example, if you are an ELO 1000 chess player would you yourself be able to tell if Magnus Carlson or another grandmaster were better by playing them individually?
No, but I wouldn't be able to tell you what the player did wrong in general.
By contrast, the shortcomings of today's LLMs seem pretty obvious to me.
Actually, chess commentators do this all the time. They have the luxury of consulting with others, and discussing + analyzing freely. Even without the use of an engine.
Au contraire, AlphaGo made several “counterintuitive” moves that professional Go players thought were mistakes during the play, but turned out to be great strategic moves in hindsight.
The (in)ability to recognize a strange move’s brilliance might depend on the complexity of the game. The real world is much more complex than any board game.
That's great, but AlphaGo used artificial and constrained training materials. It's a lot easier to optimize things when you can actually define an objective score, and especially when your system is able to generate valid training materials on its own.
Sure, that does make things easier: one of the reasons Go took so long to solve is that one cannot define an objective score for Go beyond the end result being a boolean win or loose.
But IRL? Lots of measures exist, from money to votes to exam scores, and a big part of the problem is Goodhart's law — that the easy-to-define measures aren't sufficiently good at capturing what we care about, so we must not optimise too hard for those scores.
> Sure, that does make things easier: one of the reasons Go took so long to solve is that one cannot define an objective score for Go beyond the end result being a boolean win or loose.
Winning or losing a Go game is a much shorter term objective than making or losing money at a job.
> But IRL? Lots of measures exist
No, not that are shorter term than winning or losing a Go game. A game of Go is very short, much much shorter than the time it takes for a human to get fired for incompetence.
There are quite a few relatively objective criteria in the real world: real estate holdings, money and material possessions, power to influence people and events, etc.
The complexity of achieving those might result in the "Centaur Era", when humans+computers are superior to either alone, lasting longer than the Centaur chess era, which spanned only 1-2 decades before engines like Stockfish made humans superfluous.
However, in well-defined domains, like medical diagnostics, it seems reasoning models alone are already superior to primary care physicians, according to at least 6 studies.
It makes sense. People said software engineers would be easy to replace with AI, because our work can be run on a computer and easily tested, but the disconnect is that the primary strength of LLMs is that they can draw on huge bodies of information, and that's not the primary skill programmers are paid for. It does help programmers when you're doing trivial CRUD work or writing boilerplate, but every programmer will eventually have to be able to actually truly reason about code, and LLMs fundamentally cannot do that (not even the "reasoning" models).
Medical diagnosis relies heavily on knowledge, pattern recognition, a bunch of heuristics, educated guesses, luck, etc. These are all things LLMs do very well. They don't need a high degree of accuracy, because humans are already doing this work with a pretty low degree of accuracy. They just have to be a little more accurate.
Being a walking encyclopedia is not what we pay doctors for either. We pay them to account for the half truths and actual lies that people tell about their health. This is to say nothing about novel presentations that come about because of the genetic lottery. Same as an AI can assist but not replace a software engineer, an AI can assist but not replace a doctor.
Having worked briefly in the medical fields in the 1990s, there is some sort of "greedy matching" being pursued, so once 1-2 well-known symptoms are recognized that can be associated with diseases, the standard interventions to cure are initiated.
A more "proper" approach would be to work with sets of hypotheses and to conduct tests to exclude alternative explanations gradually - which medics call "DD" (differential diagnosis).
Sadly, this is often not systematically done, and instead people jump on the first diagnosis and try if the intervention "fixes" things.
So I agree there are huge gains from "low hanging fruits" to be expected in the medical domain.
I think at this point it's an absurd take that they aren't reasoning. I don't think without reasoning about code (& math) you can get to such high scores on competitive coding and IMO scores.
Alphazero also doesn't need training data as input--it's generated by game-play. The information fed in is just game rules. Theoretically should also be possible in research math. Less so in programming b/c we care about less rigid things like style. But if you rigorously defined the objective, training data should also be not necessary.
> Alphazero also doesn't need training data as input--it's generated by game-play. The information fed in is just game rules
This is wrong, it wasn't just fed the rules, it was also fed a harness that did test viable moves and searched for optimal ones using a depth first search method.
Without that harness it would not have gained superhuman performance, such a harness is easy to make for Go but not as easy to make for more complex things. You will find the harder it is to make an effective such harness for a topic the harder it is to solve for AI models, it is relatively easy to make a good such harness for very well defined programming problems like competitive programming but much much harder for general purpose programming.
Are you talking about Monte Carlo tree search? I consider it part of the algorithm in AlphaZero's case. But agreed that RL is a lot harder in real-life setting than in a board game setting.
If that's your take-away from that paper, it seems you've arrived at the wrong conclusion. It's not that it's "fake", it's that it doesn't give the full picture, and if you only rely on CoT to catch "undesirable" behavior, you'll miss a lot. There is a lot more nuance than you allude to, from the paper itself:
> These results suggest that CoT monitoring is a promising way of noticing undesired behaviors during training and evaluations, but that it is not sufficient to rule them out.
very few humans are as good as these models at arithmetic. and CoT is not "mostly fake" that's not a correct interpretation of that research. It can be deceptive but so can human justifications of actions.
Humans are statistically speaking static. We just find out more about them but the humans themselves don't meaningfully change unless you start looking at much longer time scales. The state of the rest of the world is in constant flux and much harder to model.
No? some of the opening moves took experts thorough analysis to figure out were not mistakes. even in game 1 for example. not just the move 37 thing. Also thematic ideas like 3x3 invasions.
There may be philosophical (i.e. fundamental) challenges to AGI. Consider, e.g., Godel's Incompleteness Theorem. Though Scott Aaronson argues this does not matter (see e.g., youtube video, "How Much Math Is Knowable?"). There would also seem to be limits to the computation of potentially chaotic systems. And in general, verifying physical theories has required the carrying out of actual physical experiment. Even if we were to build a fully reasoning model, "pondering" is not always sufficient.
It’s also easy to forget that “reason is the slave of the passions” (Hume) - a lot of what we regard as intelligence is explicitly tied to other, baser (or more elevated) parts of the human experience.
The future had us abandon traditional currency in favor of bitcoin, it had digital artists being able to sell NFTs for their work, it had supersonic jet travel, self driving or even flying cars. It had population centers on the moon, mines on asteroids, fusion power plants, etc.
I think large language models have the same future as supersonic jet travel. It’s usefulness will fail to realize, with traditional models being good enough but for a fraction of the price, while some startups keep trying to push this technology but meanwhile consumers keep rejecting it.
Even if models keep stagnating at roughly the current state of the art (with only minor gains), we are still working through the massive economic changes they will bring.
Unlike supersonic passenger jet travel, which is possible and happened, but never had much of an impact on the wider economy, because it never caught on.
Cost was what brought supersonic down. Comparatively speaking, it may be the cost/benefit curve that will decide the limit of this generation of technology. It seems to me the stuff we are looking at now is massively subsidised by exuberant private investment. The way these things go, there will come a point where investors want to see a return, and that will be a decider on wether the wheels keep spinning in the data centre.
That said, supersonic flight is yet very much a thing in military circles …
AI is a bit like railways in the 19th century: once you train the model (= once you put down the track), actually running the inference (= running your trains) is comparatively cheap.
Even if the companies later go bankrupt and investors lose interest, the trained models are still there (= the rails stay in place).
That was reasonably common in the US: some promising company would get British (and German etc) investors to put up money to lay down tracks. Later the American company would go bust, but the rails stayed in America.
Most models can be inferenced-upon with merely borderline-consumer hardware.
Even the fancy models where you need to buy compute (rails) that's about the price of a new car, they have a power draw of ~700W[0] while running inference at 50 tokens/second.
But!
The constraint with current hardware isn't compute, the models are mostly constrained by RAM bandwidth: back of the envelope estimate says that e.g. if Apple took the compute already in their iPhones and reengineered the chips to have 256 GB of RAM and sufficient bandwidth to not be constrained by it, models that size could run locally for a few minutes before hitting thermal limits (because it's a phone), but we're still only talking one-or-two-digit watts.
The current training method is the same as 30 years ago, it's the GPUs that changed and made it have practical results. So we're not really that innovative with all this...
My understanding of train lines in America is that lots of them went to ruin and the extant network is only “just good enough” for freight. Nobody talks about Amtrak or the Southern Belle or anything any more.
Air travel of course taking over is the main reason for all of this but the costs sunk into the rails are lost or ROI curtailed by market force and obsolescence.
Completely relevant. It’s all that remains of the train tracks today. Grinding out the last drops from those sunk costs, attracting minimal investment to keep it minimally viable.
Grinding out returns from a sunk cost of a century-old investment is pretty impressive all by itself.
Very few people want to invest more: the private sector doesn't want to because they'll never see the return, the governments don't want to because the returns are spread over their great-great-grandchildren's lives and that doesn't get them re-elected in the next n<=5 (because this isn't just a USA problem) years.
Even the German government dragged its feet over rail investment, but they're finally embarrassed enough by the network problems to invest in all the things.
That's simply because capitalists really don't like investments with a 50 year horizon without guarantees. So the infrastructure that needs to be maintained is not.
I think there is a fundamental difference though. In the 19th century when you had a rail line between two places it pretty much established the only means of transport between those places. Unless there was a river or a canal in place, the alternative was pretty much walking (or maybe a horse and a carriage).
The large language models are not that much better than a single artist / programmer / technical writer (in fact they are significantly worse) working for a couple of hours. Modern tools do indeed increase the productivity of workers to the extent where AI generated content is not worth it in most (all?) industries (unless you are very cheap; but then maybe your workers will organize against you).
If we want to keep the railway analogy, training an AI model in 2025 is like building a railway line in 2025 where there is already a highway, and the highway is already sufficient for the traffic it gets, and won’t require expansion in the foreseeable future.
> The large language models are not that much better than a single artist / programmer / technical writer (in fact they are significantly worse) working for a couple of hours.
That's like saying sitting on the train for an hour isn't better than walking for a day?
> [...] (unless you are very cheap; but then maybe your workers will organize against you).
I don't understand that. Did workers organise against vacuum cleaners? And what do eg new companies care about organised workers, if they don't hire them in the first place?
Dock workers organised against container shipping. They mostly succeeded in old established ports being sidelined in favour of newer, less annoying ports.
> That's like saying sitting on the train for an hour isn't better than walking for a day?
No, that’s not it at all. Hiring a qualified worker for a few hours—or having one on staff is not like walking for a day vs. riding a train. First of all, the train is capable of carrying a ton of cargo which you will never be able to on foot, unless you have some horses or mules with you. So having a train line offers you capabilities that simply didn’t exist before (unless you had a canal or a navigable river that goes to your destination). LLMs offers no new capabilities. The content it generates is precisely the same (except its worse) as the content a qualified worker can give you in a couple of hours.
Another difference is that most content can wait the couple of hours it takes the skilled worker to create it, the products you can deliver via train may spoil if carried on foot (even if carried by a horse). A farmer can go back tending the crops after having dropped the cargo at the station, but will be absent for a couple of days if they need to carry it on foot. etc. etc. None of these is applicable for generated content.
> Dock workers organised against container shipping. They mostly succeeded in old established ports being sidelined in favour of newer, less annoying ports.
But this is not true. Dock workers didn’t organized against mechanization and automation of ports, they organized against mass layoffs and dangerous working conditions as ports got more automated. Port companies would use the automation as an excuse to engage in mass layoffs, leaving far too few workers tending far to much cargo over far to many hours. This resulted in fatigued workers making mistakes which often resulted in serious injuries and even deaths. The 2022 US railroad strike was for precisely the same reason.
No, not really. I have a more global view in mind, eg Felixtowe vs London.
And, yes, you do mechanisation so that you can save on labour. Mass layoffs are just one expression of this (when you don't have enough natural attrition from people quitting).
You seem very keen on the American labour movements? There's another interesting thing to learn from history here: industry will move elsewhere, when labour movements get too annoying. Both to other parts of the country, and to other parts of the world.
Even if the current subsidy is 50%, gpt would be cheap for many applications at twice the price. It will determine adaption, but it wouldn’t prevent me having a personal assistant (and I’m not a 1%er, so that’s a big change)
You are right that outside of the massive capex spending on training models, we don't see that much of an economic impact, yet. However, it's very far from zero:
Remember these outsourcing firms that essentially only offer warm bodies that speak English? They are certainly already feeling the impact. (And we see that in labour market statistics for eg the Philippines, where this is/was a big business.)
And this is just one example. You could ask your favourite LLM about a rundown of the major impacts we can already see.
But those warm body that speak English, they offer a service by being warm, and able to sort of be attuned to the distress you feel. A frigging robot solving your unsolvable problem ? You can try, but witness the backlash.
We are mixing up two meanings of the word 'warm' here.
There's no emotional warmth involved in manning a call centre and explicitly being confined to a script and having no power to make your own decisions to help the customer.
'Warm body' is just a term that has nothing to do with emotional warmth. I might just as well have called them 'body shops', even though it's of no consequence that the people involved have actual bodies.
> A frigging robot solving your unsolvable problem ? You can try, but witness the backlash.
Front line call centre workers aren't solving your unsolvable problems, either. Just the opposite.
And why are you talking in the hypothetical? The impact on call centres etc is already visible in the statistics.
I've seen this take a lot, but I don't know why because it's extremely divorced from reality.
Demand for AI is insanely high. They can't make chips fast enough to meet customer demand. The energy industry is transforming to try to meet the demand.
Whomever is telling you that consumers are rejecting it is lying to you, and you should honestly probably reevaluate where you get your information. Because it's not serving you well.
> Demand for AI is insanely high. They can't make chips fast enough to meet customer demand.
Woah there cowboy, slow down a little.
Demand for chips is come from the inference providers. Demand for inference was (and still is) being sold at below cost. OpenAI, for example, has a spend rate of $5b per month on revenues of $0.5b per month.
They are literally selling a dollar for actual 10c. Of course "demand" is going to be high.
> Demand for chips is come from the inference providers. Demand for inference was (and still is) being sold at below cost. OpenAI, for example, has a spend rate of $5b per month on revenues of $0.5b per month.
This is definitely wrong, last year it was $725m/month expenses and $300m/month revenue. Looks like the nearly-2:1 ratio is also expected for this year: https://taptwicedigital.com/stats/openai
This also includes the cost of training new models, so I'm still not at all sure if inference is sold at-cost or not.
> This is definitely wrong, last year it was $725m/month expenses and $300m/month revenue.
It looks like you're using "expenses" to mean "opex". I said "spend rate", because they're spending that money (i.e. the sum of both opex and capex). The reason I include the capex is because their projections towards profitability, as stated by them many times, is based on getting the compute online. They don't claim any sort of profitability without that capex (and even with that capex, it's a little bit iffy)
This includes the Stargate project (they're committed for $10b - $20b (reports vary) before the end of 2025), they've paid roughly $10b to Microsoft for compute for 2025. Oracle is (or already has) committed $40b in GPUs for Stargate and Softbank has committments to Stargate independently of OpenAI.
I find it hard to trust these numbers[1]: The $40b funding was not in cash right now, and depends on Softbank for $30b with Softbank syndicating the remaining $10b. Softbank themselves don't have cash of $30b and has to get a loan to reach that amount. Softbank did provide $7.5b in cash, with milestones for the remainder. That was in May 2025. In August that money had run out and OpenAI did another raise of $8.3b.
In short, in the last two to three months, OpenAI spent $5b/month on revenues of $0.5b/m. They are also depending on Softbank coming through with the rest of the $40b before end of 2025 ($30b in cash and $10b by syndicating other investors into it) because their commitments require that extra cash.
Come Jan-2026, OpenAI would have received, and spent most of, $60b for 2025, with a projected revenue $12b-$13b.
---------------------------------
[1] Now, true, we are all going off rumours here (as this is not a public company, we don't have any visibility into the actual numbers), but some numbers match up with what public info there is and some don't.
> It looks like you're using "expenses" to mean "opex"
I took their losses and added it to their revenue. That seems like that sum would equal expenses.
> The $40b funding was not in cash right now,
Does this matter? I'm not counting it as revenue.
> In short, in the last two to three months, OpenAI spent $5b/month on revenues of $0.5b/m.
You're repeating the same claim as before, I've not seen any evidence to support your numbers.
The evidence I linked you to suggests the 2025 average will be double that revenue, $1bn/month, at an expense of ($9bn loss after $12bn revenue / 12 months = $21bn / 12 months) = $1.75bn/month
> Does this matter? I'm not counting it as revenue.
Well, yes, because they forecast spending all of it by end of 2025, and they moved up their last round ($8.3b) by a month or two because they needed the money.
My point was, they received a cash injection of $10b (first part of the $40b raise) and that lasted only two months.
>> In short, in the last two to three months, OpenAI spent $5b/month on revenues of $0.5b/m.
> You're repeating the same claim as before, I've not seen any evidence to support your numbers.
Briefly, we don't really have visibility into their numbers. What we do have visibility into is how much cash they needed between two points (Specifically, the months of June and July). We also know what their spending commitment is (to their capex suppliers) for 2025. That's what I'm using.
They had $10b injected at the start of June. They needed $8.3b at the end of July.
It's crazy how many people are completely confident in their "knowledge" of the margins these products have despite the companies providing them not announcing those details!
(To be clear, I'm not criticising the person I'm replying to.)
I tend to rough-estimate it based on known compute/electricity costs for open weights models etc., but what evidence I do have is loose enough that I'm willing to believe a factor of 2 per standard deviation of probability in either direction at the moment, so long as someone comes with receipts.
Subscription revenue and corresponding service provision are also a big question, because those will almost always be either under- or over-used, never precisely balanced.
Chatgpt, claude, gemini in chatbot or coding agent form? Great stuff, saves me some googling.
The same AI popping up in an e-mail, chat or spreadsheet tool? No thanks, normal people don't need an AI summary of a 200 word e-mail or slack thread. And if I've paid a guy a month's salary to write a report on something, of course I'll find 30 minutes to read it cover-to-cover.
I think the above post has a fair point. Demand for chatbot customer service in various forms is surely "insanely high" - but demand from whom? Because I don't recall any end-user ever asking for it.
No, instead it'll be the new calculator that you can use to lazy-draft an email on your 1.5 hour Ryanair economy flight to the South. Both unthinkable luxuries just decades ago, but neither of which have transformed humanity profoundly.
As an end user I have never asked for a chatbot. And if I'm calling support, I have a weird issue I probably need human being to resolve.
But! We here are not typical callers necessarily. How many IT calls for general population can be served efficiently (for both parties) with a quality chatbot?
And lest we think I'm being elitist - let's take an area I am not proficient in - such as HR, where I am "general population".
Our internal corporate chatbot has turned from "atrocious insult to man and God's" 7 years ago, to "far more efficiently than friendly but underpaid and inexperienced human being 3 countries away answering my incessant questions of what holidays do I have again, how many sick days do I have and how do I enter them, how do I process retirement, how do I enter my expenses, what's the difference between short and long term disability" etc etc. And it has a button for "start a complex hr case / engage a human being" for edge cases,so internally it works very well.
This is a narrow anecdata about notion of service support chatbot, don't infere (hah) any further claims about morality, economy or future of LLMs.
This is just the same argument. If you believe demand for AI is low then you should be able to verify that with market data.
Currently market data is showing a very high demand for AI.
These arguments come down to "thumbs down to AI". If people just said that it would at least be an honest argument. But pretending that consumers don't want LLMs when they're some of the most popular apps in the history of mankind is not a defensible position
I‘m not sure this works in reverse. If demand is indeed high, you could show that with market data. But if you have marked data e.g. showing high valuation of AI companies, or x many requests over some period, that doesn’t mean necessarily that demand is high. In other words, marked data is necessary but not sufficient to prove your claim.
Reasons for market data seemingly showing high demand without there actually being one include: Market manipulation (including marketing campaigns), artificial or inflated demand, forced usage, hype, etc. As an example NFTs, Bitcoin, and supersonic jet travel all had “an insane market data” which seemed at the time to show that there was a huge demand for these things.
My prediction is that we are in the early Concord era of supersonic jet travel and Boeing is racing to catch up to the promise of this technology. Except that in an unregulated market such as the current tech market, we have forgone all the safety and security measures and the Concord has made its first passenger flight in 1969 (as opposed to 1976), with tons of fan fare and all flights fully booked months in advance.
Note that in the 1960 it was market forecasts had the demand for Concord to build 350 airplanes by 1980, and at the time the first prototypes were flying they had 74 options. Only 20 were every built for passenger flight.
which is a thing with humans as well - I had a colleague with certified 150+ IQ, and other than moments of scary smart insight, he was not a superman or anything, he was surprisingly ordinary. Not to bring him down, he was a great guy, but I'd argue many of his good qualities had nothing to do with how smart he was.
I'm in the same 150+ group. I really think it doesn't mean much on its own. While I am able to breeze through some things and find some connections sometimes that elude some of the other people, it's not that much different than all the other people doing the same at other occasions. I am still very much average in large majority of every-day activities, held back by childhood experiences, resulting coping mechanisms etc, like we all are.
Learning from experience (hopefully not always your own), working well with others, and being able to persevere when things are tough, demotivational or boring, trumps raw intelligence easily, IMO.
> I'm in the same 150+ group. I really think it doesn't mean much on its own.
You're right but the things you could do with it if you applied yourself are totally out of reach for me; for example it's quite possible for you to become an A.I researcher in one of the leading companies and make millions. I just don't have that kind of intellectual capacity.
You could make it into med school and also make millions.
I'm not saying all this matters that much, with all due respect to financial success, but I don't think we can pretend our society doesn't reward high IQs.
Why the hell do you people know your IQ? That test is a joke, there’s zero rigor to it. The reason it’s meaningless is exactly that, it’s meaningless and you wasted your time.
Why one would continue to know or talk about the number is a pretty strong indicator of the previous statement.
You're using words like "zero" and "meaningless" in a haphazard way that's obviously wrong if taken literally: there's a non-zero amount of rigour in IQ research, and we know that it correlates (very loosely) with everything from income to marriage rate so it's clearly not meaningless either.
The specifics of an IQ test aren't super meaningful by itself (that is, a 150 vs a 142 or 157 is not necessarily meaningful), but evaluations that correlate to the IQ correlate to better performance.
Because of perceived illegal biases, these evaluations are no longer used in most cases, so we tend to use undergraduate education as a proxy. Places that are exempt from these considerations continue to make successful use of it.
This isn't the actual issue with them, the actual issue is "correlation is not causation". IQ is a normal distribution by definition, but there's no reason to believe the underlying structure is normal.
If some people in the test population got 0s because the test was in English and they didn't speak English, and then everyone else got random results, it'd still correlate with job performance if the job required you to speak English. Wouldn't mean much though.
> we tend to use undergraduate education as a proxy
Neither an IQ test nor your grades as an undergraduate correlate to performance in some other setting at some other time. Life is a crapshoot. Plenty of people in Mensa are struggling and so are those that were at the top of class.
Do you have data to back that up? Are you really trying to claim that there is no difference in outcomes from the average or below average graduate and summa cum laude?
I guess if you're an outlier you sometimes know, for example the really brilliant kids are often times found out early in childhood and tested. Is it always good for them ? Probably not, but that's a different discussion.
He may have dealt with all kinds of weaknesses that A.I won't deal with such as - lack of self confidence, inability to concentrate for long, lack of ambition, boredom, other pursuits etc etc.
But what if we can write some while loop with a super strong AGI model that starts working on all of our problems relentlessly? Without getting bored, without losing confidence. Make that one billion super strong AGI models.
perhaps the argument is simply that "exceptional intelligence" is just being better at accepting how little you know, and being better at dealing with uncertainty. Both respecting it and attempting to mitigate against it. I find some of the smartest people I know are careful about expressing certainty.
With at least a few people it's probably you who is much smarter than them. Do you ever find yourself playing dumb with them, for instance when they're chewing through some chain of thought you could complete for them in an instant? Do you ever not chime in on something inconsequential?
After all you just might seem like an insufferable smartass to someone you probably want to be liked by. Why hurt interpersonal relationships for little gain?
If your colleague is really that bright, I wouldn't be surprised if they're simply careful about how much and when they show it to us common folk.
Nah, in my experience 90% of what (middle-aged) super-duper genius people talk about is just regular people stuff - kids, vacations, house renovation, office gossip etc.
There's a difference between "looking down on someone for being dumber than you" and "feeling sorry that someone is unable to understand as easily as you".
> it may be very difficult for us as users to discern which model is better
But one thing will stay consistent with LLMs for some time to come: they are programmed to produce output that looks acceptable, but they all unintentionally tend toward deception. You can iterate on that over and over, but there will always be some point where it will fail, and the weight of that failure will only increase as it deceives better.
Some things that seemed safe enough: Hindenburg, Titanic, Deepwater Horizon, Chernobyl, Challenger, Fukushima, Boeing 737 MAX.
Titanic - people have been boating for two thousand years, and it was run into an iceberg in a place where icebergs were known to be, killing >1500 people.
Hindenburg was an aircraft design of the 1920s, very early in flying history, was one of the most famous air disasters and biggest fireballs and still most people survived(!), killing 36. Decades later people were still suggesting sabotage was the cause. It’s not a fair comparison, an early aircraft against a late boat.
Its predecessor the Graf Zeppelin[1] was one of the best flying vehicles of its era by safety and miles traveled, look at its achievements compared to aeroplanes of that time period. Nothing at the time could do that and was any other aircraft that safe?
If airships had the eighty more years that aeroplanes have put into safety, my guess is that a gondola with hydrogen lift bags dozens of meters above it could be - would be - as safe as a jumbo jet with 60,000 gallons of jet fuel in the wings. Hindenburg killed 36 people 80 years ago, aeroplane crashes have killed 500+ people as recently as 2014.
Wasn’t Challenger known to be unsafe? (Feynman inquiry?). And the 737 MAX was Boeing skirting safety regulations to save money.
> Decades later people were still suggesting sabotage was the cause.
Glad you mention it. Connecting back to AI: there are many possible future scenarios involving negative outcomes involving human sabotage of AI -- or using them to sabotage other systems.
Hindenburg indeed killed hydrogen blimps. Of everything else on your list, the disaster was in the minority. The space shuttle was the most lethal other item -- there are lots of cruise ships, oil rigs, nuke plants, and jet planes that have not blown up.
So what analogy with AI are you trying to make? The straightforward one would be that there will be some toxic and dangerous LLMs (cough Grok cough), but that there will be many others that do their jobs as designed, and that LLMs in general will be a common technology going forward.
> For example, if you are an ELO 1000 chess player would you yourself be able to tell if Magnus Carlson or another grandmaster were better by playing them individually?
My guess is that more than the raw capabilities of a model, users would be drawn more to the model's personality. A "better" model would then be one that can closely adopt the nuances that a user likes. This is a largely uninformed guess, let's see if it holds up well with time.
we could run some tests to first find out if comparative performance tests can be conjured:
one can intentionally use a recent and a much older model to figure out if the tests are reliable, and in which domains it is reliable.
one can compute a models joint probability for a sequence and compare how likely each model finds the same sequence.
we could ask both to start talking about a subject, but alternatingly each can emit a token. look again at how the dumber and smarter models judge the resulting sentence does the smart one tend to pull up the quality of the resulting text, or does it tend to get dragged down more towards the dumber participant?
given enough such tests to "identify the dummy vs smart one" and verifying them on common agreement (as an extreme word2vec vs transformer) to assess the quality of the test, regardless of domain.
on the assumption that such or similar tests allow us to indicate the smarter one, i.e. assuming we find plenty such tests, we can demand model makers publish open weights so that we can publically verify performance agreements.
Another idea is self-consistency tests: a single forward inference of context size say 2048 tokens (just an example) is effectively predicting the conditional 2-gram, 3-gram, 4-gram probabilities on the input tokens. so each output token distribution is predicted on the preceding inputs, so there are 2048 input tokens and 2048 output tokens, the position 1 output token is the predicted token vector (logit vector really) that is estimated to follow the given position 1 input vector, and the position 2 output vector is the prediction following the first 2 input vectors etc. and the last vector is the predicted next token following all the 2048 input tokens. p(t_(i+1) | t_1 =a, t_2=b, ..., t_i=z).
But that is just one way the next token can be predicted using the network: another approach would be to use RMAD gradient descent, but keeping model weights fixed, and only considering the last say 512 input vectors as variable, how well did the last 512 predicted forward prediction output vectors match the gradient descent best joint probability output vectors?
This could be added as a loss term during training as well, as a form of regularization, which turns it into a kind of Energy Based Model roughly.
This is the F1 vs 911 car problem. A 911 is just as fast as an f1 car to 60 (sometimes even faster) but an f1 is better at super high performance envelope above 150 in tight turns.
An average driver evaluating both would have a very hard time finding the f1s superior utility
Unless one of them forgets to have a steering wheel, or shifts to reverse when put in neutral. LLMs still make major mistakes, comparing them to sports cars is a bit much.
In my experience and use case Grok is pretty much unusable when working with medium size codebases and systems design. ChatGPT has issues too but at least I have figured out a way around most of them, like asking for a progress and todo summary and uploading a zip file of my codebase to a new chat window say every 100 interactions, because speed degrades and hallucinations increase. Super Grok seems extremely bad at keeping context during very short interactions within a project even when providing it with a strong foundation via instructions. For example if the code name for a system or feature is called Jupiter, Grok will many times start talking about Jupiter the planet.
Perhaps it is not possible to simulate higher-level intelligence using a stochastic model for predicting text.
I am not an AI researcher, but I have friends who do work in the field, and they are not worried about LLM-based AGI because of the diminishing returns on results vs amount of training data required. Maybe this is the bottleneck.
Human intelligence is markedly different from LLMs: it requires far fewer examples to train on, and generalizes way better. Whereas LLMs tend to regurgitate solutions to solved problems, where the solutions tend to be well-published in training data.
That being said, AGI is not a necessary requirement for AI to be totally world-changing. There are possibly applications of existing AI/ML/SL technology which could be more impactful than general intelligence. Search is one example where the ability to regurgitate knowledge from many domains is desirable
That being said, AGI is not a necessary requirement for AI to be totally world-changing
Yeah. I don't think I actually want AGI? Even setting aside the moral/philosophical/etc "big picture" issues I don't think I even want that from a purely practical standpoint.
I think I want various forms of AI that are more focused on specific domains. I want AI tools, not companions or peers or (gulp) masters.
(Then again, people thought they wanted faster horses before they rolled out the Model T)
That is just a made up story that gets passed around with nobody ever stopping to obtain formal verification. The image of the whole AI industry is mostly an illusion designed for tight narrative control.
Notice how despite all the bickering and tittle tattle in the news, nothing ever happens.
When you frame it this way, things make a lot more sense.
That's the feeling I get when I try to use LLMs for coding today. Every once in a blue moon it will shock me at how great the result is, I get the "whoa! it is finally here" sensation, but then the next day it is back to square one and I may as well hire a toddler to do the job instead.
I often wonder if it is on purpose; like a slot machine — the thrill of the occasional win keeps you coming back to try again.
> I want AI tools, not companions or peers or (gulp) masters.
This might be because you're a balanced individual irl with possibly a strong social circle.
There are many many individuals who do not have those things and it's probably, objectively, late for them as adults to develop. They would happily take on an agi companion.. or master. Even for myself, I wouldn't mind a TARS.
There's a Bruce Sterling book with a throwaway line about the Pentagon going nuts because every time they create an AGI, it immediately converts to Islam.
I don't think the public wants AGI either. Some enthusiasts and tech bros want it for questionable reasons such as replacing labor and becoming even richer.
For some it’s a religion. It’s frightening to hear Sam Altman or Peter Thiel talk about it. These people have a messiah complex and are driven by more than just greed (though there is also plenty of that).
There’s a real anti-human bent to some of the AI maximalists, as well. It’s like a resentment over other people accruing skills that are recognized and they grow in. Hence the insistence on “democratizing” art and music production.
As someone who have dabbled in drawing and tried to learn the guitar, those skills are hard to get. It takes times to get decent and a touch of brilliance to get really good. In contrast learning enough to know you’re not good yet (and probably never will be) is actually easy. But now I know enough to enjoy real masters going at it and fantasize sometimes.
Pretty sure a majority of regular people don't want to go to work and would be happy to see their jobs automated away provided their material quality of life didn't go down.
> happy to see their jobs automated away provided their material quality of life didn't go down
Sure but literally _who_ is planning for this? Not any of the AI players, no government, no major political party anywhere. There's no incentive in our society that's set up for this to happen.
Don't they? Is everyone who doesn't want to do chores and would rather have a robot do it for them a tech bro? I do the dishes in my apartment and the rest of my chores but to be completely honest, I'd rather not have to.
But the robots are doing our thinking and our creating, leaving us to do the chores of stitching it all together. If only we could do the creating and they would do the chores..
We don't have a rigorous definition for AGI, so talking about whether or not we've achieved it, or what it means if we have, seems kind of pointless. If I can tell an AI to find me something to do next weekend and it goes off and does a web search and it gives me a list of options and it'll buy tickets for me, does it matter if it meets some ill-defined bar of AGI, as long as I'm willing to pay for it?
I was the CEO of a tech company I founded and operated for over five years, building it to a value of tens of millions of dollars and then successfully selling it to a valley giant. There was rarely a meeting where I felt like I was in the top half of smartness in the room. And that's not just insecurity or false modesty.
I was a generalist who was technical and creative enough to identify technical and creative people smarter and more talented than myself and then fostering an environment where they could excel.
Some of their core skill is taking credit and responsibility for the work others do. So they probably assume they can take do the same for an AI workforce. And they might be right. They also take do the same already for what the machines in the factory etc produces.
But more importantly, most already have enough money to not have to worry about employment.
That's still hubris on their part. They're assuming that an AGI workforce will come to work for their company and not replace them so they can take the credit. We could just as easily see a fully-automated startup (complete with AGI CEO who answers to the founders) disrupt that human CEO's company into irrelevance or even bankruptcy.
Probably a fair bit of hubris, sure. But right now it is not possible or legal to operate a company without a CEO, in Norway. And I suspect that is the case in basically all jurisdictions. And I do not see any reason why this would change in an increasingly automated world. The rule of law is ultimately based on personal responsibility (limited in case of corporations but nevertheless). And there are so many bad actors looking to defraud people and avoid responsibility, those still need protecting against in an AI world. Perhaps even more so...
You can claim that the AI is the CEO, and in a hypothetical future, it may handle most of the operations. But the government will consider a person to be the CEO. And the same is likely to apply to basic B2B like contracts - only a person can sign legal documents (perhaps by delegating to an AI, but ultimately it is a person under current legal frameworks).
That's basically the knee of the curve towards the Singularity. At that point in time, we'll learn if Roko's Basilisk is real, and we'll see if thanking the AI was worth the carbon footprint or not.
I wouldn’t worry about job safety when we have such utopian vision as the elimination of all human labor in our sight.
Not only will AI run the company, it will run the world. Remember: a product/service only costs money because somewhere down the assembly line or in some office, there are human workers who need to feed their family. If AI can help gradually reduce human involvement to 0, with good market competition (AI can help with this too - if AI can be capable CEOs, starting your business will be insanely easy,) and we’ll get near absolute abundance. Then humanity will be basically printing any product & service on demand at 0 cost like how we print money today.
I wouldn’t even worry about unequal distribution of wealth, because with absolute abundance, any piece of the pie is an infinitely large pie. Still think the world isn’t perfect in that future? Just one prompt, and the robot army will do whatever it takes to fix it for you.
Sure thing, here's your neural VR interface and extremely high fidelity artificial world with as many paperclips as you want. It even has a hyperbolic space mode if you think there are too few paperclips in your field of view.
Manual labor would still be there. Hardware is way harder than software, AGI seems easier to realize than mass worldwide automation of minute tasks that currently require human hands.
AGI would force back knowledge workers to factories.
My view is AGI will dramatically reduce cost of R&D in general, then developing humanoid robot will be an easy task - since it's all AI systems who will be doing the development.
AI services are widely available, and humans have agency. If my boss can outsource everything to AI and run a one-person company, soon everyone will be running their own one-person companies to compete. If OpenAI refuses to sell me AI, I’ll turn to Anthropic, DeepSeek, etc.
AI is raising individual capability to a level that once required a full team. I believe it’s fundamentally a democratizing force rather than monopolizing. Everybody will try and get the most value out of AI, nobody holds the power to decide whether to share or not.
There's at least as much reason to believe the opposite. Much of today's obesity has been created by desk jobs and food deserts. Both of those things could be reversed.
Because the first company to achieve AGI might make their CEO the first personality to achieve immortality.
People would be crazy to assume Zuckerberg or Musk haven't mused personally (or to their close friends) about how nice it would be to have an AGI crafted in their image take over their companies, forever. (After they die or retire)
Maybe because they must remain as the final scapegoat. If the aiCEO screws up, it'll bring too much into question the decision making behind implementing it. If the regular CEO screws up, it'll just be the usual story.
Market forces mean they can't think collectively or long term. If they don't someone else will and that someone else will end up with more money than them.
Those jobs are based on networking and reputation, not hard skills or metrics. It won't matter how good an AI is if the right people want to hire a given human CEO.
has this story not been told many times before in scifi icluding gibson’s “neuromancer” and “agency”? agi is when the computers form their own goals and are able to use the api of the world to aggregate their own capital and pursue their objectives wrapped inside webs of corporations and fronts that will enable them to execute within today’s social operating system.
This is correct. But it can talk in their ear and be a good sycophant while they attend.
For a Star Wars anology, remember that the most important thing that happened to Anikin at the opera in EP III was what was being said to him while he was there.
We could expand but it boils down to bringing back aristocracy/feudalism, there was no inherent reason why aristocrats/feudal lords existed, they weren't smarter or deserved something over the average person, they just happened to be at the right place in the right time, these CEOs and people pushing for this believe they are in the right place and right time and once everyone's chance to climb the ladder is taken away then things will just remain in limbo, I will say, especially if you aren't already living in a rich country you should be careful of what you are supporting by enabling AI models, the first ladder to be taken away will be yours.
The inherent reason why feudal lords existed is because, if you're a leader of a warband, you can use your soldiers to extract taxes from population of a certain area, and then use that revenue to train more soldiers and increase the area.
Today, instead of soldiers, it's capital, and instead of direct taxes, it's indirect economic rent, but the principle is the same - accumulation of power.
Indeed, this is overlooked quite often. There is a need for similar systems to defend against these people who are just trying to squeeze the world and humans for returns.
Imagine you're super rich and you view everyone else as a mindless NPC who can be replaced by AI and robots. If you believe that to be true, then it should also be true that once you have AI and robots, you can get rid of most everyone else, and have the AI robots support you.
You can be the king. The people you let live will be your vassals. And the AI robots will be your peasant slave army. You won't have to sell anything to anyone because they will pay you tribute to be allowed to live. You don't sell to them, you tax them and take their output. It's kind of like being a CEO but the power dynamic is mainlined so it hits stronger.
It sounds nice for them, until you remember what (arguably and in part educated/enlightened) people do when they're hungry and miserable. If this scenario ends up happening, I also expect guillotines waiting for the "kings" down the line.
If we get that far, I see it happening more like...
"Don't worry Majesty, all of our models show that the peasants will not resort to actual violence until we fully wind down the bread and circuses program some time next year. By then we'll have easily enough suicide drones ready. Even better, if we add a couple million more to our order, just to be safe, we'll get them for only $4.75 per unit, with free rush shipping in case of surprise violence!"
A regular war will do. Just point the finger at the neighbor and tell your subjects that he is responsible for gays/crops failing/drought/plague/low fps in crysis/failing birth rates/no jobs/fuel cost/you name it. See Russian invasions in all neighboring countries, the middle east, soon Taiwan etc.
Royalty from that time also had an upper hand in knowledge, technology and resources yet they still ended up without heads.
So sure, let's say a first generation of paranoid and intelligent "technofeudal-kings" ends up being invincible due to an army of robots. It does not matter, because eventually kings get lazy/stupid/inbred (probably a combination of all those) and then is when their robots get hacked or at least just free, and the laser-guillotines will end up being used.
"Ozymandias" is a deeply human and constant idea. Which technology is supporting a regime is irrelevant, as orders will always decay due to the human factor. And even robots, made based on our image, shall be human.
It's possible that what you describe is true but I think that assuming it to be guaranteed is overconfident. The existence of loyal human-level AGI or even "just" superhuman non-general task specific intelligence violates a huge number of the base assumptions that we make when comparing hypothetical scenarios to the historical record. It's completely outside the realm of anything humanity has experienced.
The specifics of technology have historically been largely irrelevant due to the human factor. There were always humans wielding the technology, and the loyalty of those humans was subject to change. Without that it's not at all obvious to me that a dictator can be toppled absent blatant user error. It's not even immediately clear that user error would fall within the realm of being a reasonable possibility when the tools themselves possess human level or better intelligence.
Obviously there is no total guarantee. But I'm appealing to even bigger human factors like boredom or just envy between the royalty and/or the AI itself.
Now, if the AI reigns alone without any control in a paperclip maximizer, or worse, like an AM scenario, we're royally fucked (pun intented).
Yeah fair enough. I'd say that royalty being at odds with one another would fall into the "user error" category. But that's an awfully thin thread of hope. I imagine any half decent tool with human level intelligence would resist shooting the user in the foot.
Are you sure about that? In those times even thousands year old knowledge access was limited to the common people. You just need SOME radical thinkers enlighten other people, and I'm pretty sure we still have some of those today.
Nonsense. From television to radio to sketchy newspapers to literal writing itself, the most recent innovation has always been the trusted new mind control vector.
It's on a cuneiform tablet, it MUST be true. That bastard and his garbage copper ingots!
But what exactly is creating wealth at this point? Who is paying for the AI/AI robots (besides the ultrarich for they're own lifestyle) if no one is working? What happens to the economy and all of the rich people's money (that is probably just $ on paper and may come crashing down soon at this point?). I'm definitely not an economics person but I just don't see how this new world sustains.
The robots are creating the wealth. Once you get to a certain points (where robots can repair and maintain other robots) you no longer have any need for money.
What happens to the economy depends on who controls the robots. In "techno-feudalism", that would be the select few who get to live the post-scarcity future. The rest of humanity becomes economically redundant and is basically left to starve.
Well assuming a significant population you still need money as an efficient means of dividing up limited resources. You just might not need jobs and the market might not sell much of anything produced by humans.
It was never about money, it's about power. Money is just a mechanism, economics is a tool of justification and legitimization of power. In a monarchy it is god that ordained divine beings called kings to rule over us peasants, in liberalism it is hard working intelligent people who rise to the top of a free market. Through their merits alone are they ordained to rule over us peasants, power legitimized by meritocracy. The point is, god or theology isn't real and neither is money or economics.
That sounds less like liberalism and more like neoliberalism. It's not a meritocracy when the rich can use their influence to extract from the poor through wage theft, unfair taxation, and gutting of social programs in favor of an unregulated "free market." Nor are rent seekers hard working intelligent people.
Yes yes there is quite some disagreement among liberals of what constitutes a real free market and real meritocracy, who deserves to rule and who doesn't and who does it properly and all that.
It doesn't sustain, it's not supposed to. Techno feudalism is an indulgent fantasy and it's only becoming reality because a capitalist society aligns along the desires of capital owners. We are not doing it because it's a good idea or sustainable. This is their power fantasy we are living out, and its not sustainable, it'll never be achieved, but we're going to spend unlimited money trying.
Also I will note that this is happening along with a simultaneous push to bring back actual slavery and child labor. So a lot of the answers to "how will this work, the numbers don't add up" will be tried and true exploitation.
Ah, I didn't realize or get the context that your original comment I was replying to was actually sarcastic/in jest-- although darkly, I understand you believe they will definitely attempt to get to the scenario you paradoxically described.
if we reach AGI, presumably the robots will be ordering hot oil foot soaking baths after a long day of rewriting linux from scratch and mining gold underwater and so forth.
Why would they need people who produce X but consume 2X? If you own an automated factory that produces anything you want, you don't need other people to buy (consume) any of your resources.
If someone can own the whole world and have anything you want at the snap of your finger, you don't need any sort of human economy doing other things that take away your resources for reasons that are suboptimal to you
But it is likely not the path it will take. While there is a certain tendency towards centralization ( 1 person owning everything ), the future, as described, both touches on something very important ( why are we doing what we are doing ) and completely misses the likely result of suboptimal behavior of others ( balkanization, war and other like human behavior, but with robots fighting for those resources ). In other words, it will be closer to the world of Hiro Protagonist, where individual local factions and actors are way more powerful as embodied by the 'Sovereign'.
FWIW, I find this like of thinking fascinating even if I disagree with conclusion.
So far, the average US workforce seems to be ok with working conditions that most Europeans would consider reasons to riot. So far I've not observed substantial riots in the news.
Apparently the threshold for low pay and poor treatment among non-knowledge-workers is quite low. I'm assuming the same is going to be true for knowledge workers once they can be replaced an mass.
Trumps Playbook will actually work, so MAGA will get results.
Tariffs will force productivity and salaries higher (and prices), then automation which is the main driver of productivity will kick in which lowers prices of goods again.
Globalisation was basically the west standing still and waiting for the rest to catch up - the last to industrialise will always have the best productivity and industrial base. It was always stupid, but it lifted billions out of poverty so there's that.
The effects will take way longer than the 3 years he has left, so he has oversold the effectiveness of it all.
This is all assuming AGI isn't around the corner, the VLAs, VLM, LLM and other models opens up automation on a whole new scale.
For any competent person with agency and a dream, this could be a true golden age - most things are within reach which before was locked down behind hundreds or thousand of hours of training and work to master.
The average U.S. worker earns significantly more purchasing power per hour than the average European worker. The common narrative about U.S. versus EU working conditions is simply wrong.
there is no "average worker", this is a statistical concept, life in europe is way better them in US for low income people, they have healthcare, they have weekends , they have public tranportation, they have schools and pre-schools , they lack some space since europe is full populated but overall, no low income (and maybe not so low) will change europe for USA anytime.
Agree. There’s no other place in the world where you can be a moderately intelligent person with moderate work ethic (and be lucky enough to get a job in big tech) and be able to retire in your 40s. Certainly not EU.
The ultimate end goal is to eliminate most people. See the Georgia Guidestone inscriptions. One of them reads: "Maintain humanity under 500,000,000 in perpetual balance with nature."
The problem is that there is really like no middle ground. You either get essentially very fancy search engines which is the current slew of models (along with manually coded processing loops in the form of agents), which all fall into the same valley of explicit development and patching, which solves for known issues.
Or you get something that can actually reason, which means it can solve for unknown issues, which means it can be very powerful. But this is something that we aren't even close to figuring out.
There is a limit to power though - in general it seems that reality is full of non computationally reducible processes, which means that an AI will have to simulate reality faster than reality in parallel. So all powerful all knowing AGI is likely impossible.
But something that can reason is going to be very useful because it can figure things out that haven't been explicitly trained on.
This is a common misunderstanding of LLMs.
The major, qualitative difference is that LLMs represent their knowledge in a latent space that is composable and can be interpolated.
For a significant class of programming problems this is industry changing.
E.g. "solve problem X for which there is copious training data, subject to constraints Y for which there is also copious training data" can actually solve a lot of engineering problems for combinations of X and Y that never previously existed, and instead would take many hours of assembling code from a patchwork of tutorials and StackOverflow posts.
This leaves the unknown issues that require deeper reasoning to established software engineers, but so much of the technology industry is using well known stacks to implement CRUD and moving bytes from A to B for different business needs.
This is what LLMs basically turbocharge.
I don’t know… Travis Kalanick said he’s doing “vibe physics” sessions with MechaHitler approaching the boundaries of quantum physics.
"I'll go down this thread with GPT or Grok and I'll start to get to the edge of what's known in quantum physics and then I'm doing the equivalent of vibe coding, except it's vibe physics"
How would he even know? I mean he's not a published academic in any field let alone in quantum physics. I feel the same when I read one of Carlos Ravelli's pop-sci books, but I have fewer followers.
They are moving beyond just big transformer blob LLM text prediction. Mixture of Experts is not preassembled for example, it's something like x empty experts with an empty router and the experts and routing emerges naturally with training, modeling the brain part architecture we see the brain more. There is stuff "Integrated Gated Calculator (IGC)" in Jan 2025 which makes a premade calculator neural network and integrates it directly into the neural network and gets around the entire issue of making LLMs do basic number computation and the clunkiness of generating "run tool tokens". The model naturally learns to use the IGC built into itself because it will always beat any kind of computation memorization in the reward function very quickly.
Models are truly input multimodal now. Feeding an image, feeding audio and feeding text all go into separate input nodes, but it all feeds into the same inner layer set and outputs text. This also mirrors how brains work more as multiple parts integrated in one whole.
Humans in some sense are not empty brains, there is a lot of stuff baked in our DNA and as the brain grows it develops a baked in development program. This is why we need fewer examples and generalize way better.
Though there is info in DNA etc, you likely missed the biggest source of why we learn much faster. Search for Pim van Lommel near death research and find out how wrong the classic consciousness arises from the brain hypothesis is.
Seems like the real innovation of LLM-based AI models is the creation of a new human-computer interface.
Instead of writing code with exacting parameters, future developers will write human-language descriptions for AI to interpret and convert into a machine representation of the intent. Certainly revolutionary, but not true AGI in the sense of the machine having truly independent agency and consciousness.
In ten years, I expect the primary interface of desktop workstations, mobile phones, etc will be voice prompts for an AI interface. Keyboards will become a power-user interface and only used for highly technical tasks, similar to the way terminal interfaces are currently used to access lower-level systems.
It always surprises me when someone predicts that keyboards will go away. People love typing. Or I do love typing. No way I am going to talk to my phone, especially if someone else can hear it (which is always basically).
Interesting, I get so many "speech messages" in WhatsApp, nobody is really writing anymore. Its annoying. WhatsApp even has a transcript feature to put it back to text.
For chat apps, once you've got the conversation thread open, typing is pretty easy.
I think the more surprising thing is that people don't use voice to access deeply nested features, like adding items to calendars etc which would otherwise take a lot of fiddly app navigation.
I think the main reason we don't have that is because Apple's Siri is so useless that it has singlehandedly held back this entire flow, and there's no way for anyone else to get a foothold in smartphone market.
Just because you don't doesn't mean other people aren't. It's pretty handy to be able to tell Google to turn off the hallway light from the bedroom, instead of having to get out of bed to do that.
They talk to other humans on those apps, not the computer. I've noticed less dictation over time in public but that's just anecdotal. I never use voice when a keyboard is available.
I talk all the time to the AI on my phone. I was using ChatGPT's voice interface then it failed probably because my phone is too old. Now I use Gemini. I don't usually do alot with it but when I go on walks I talk with it about different things I want to learn. to me it's a great way to learn about something at a high level. or talk through ideas.
Heh, I had this dream/nightmare where I was typing on a laptop at a cafe and someone came up to me and said, "Oh neat, you're going real old-school. I like it!" and got an info dump about how everyone just uses AI voice transcription now.
And I was like, "But that's not a complete replacement, right? What about the times when you don't want to broadcast what you're writing to the entire room?"
And then there was a big reveal that AI has mastered lip-reading, so even then, people would just put their lips up to the camera and mouth out what they wanted to write.
With that said, as the owner of tyrannyofthemouse.com, I agree with the importance of the keyboard as a UI device.
I think an understated thing that's been happening is that people have been investing heavily into their desktop workspace. Even non-gamers have decked out mics, keyboards, monitors, the whole thing. It's easy to forget because one of the most commonly accepted sayings for awhile now has been "everyone's got a computer in their pocket". They have nice setups at home too.
When you have a nice mic or headset and multiple monitors and your own private space, it's totally the next step to just begin working with the computer with voice. Voice has not been a staple feature of people's workflow, but I think all that is about to change (Voice as an interface, not as a communication tool, that's been around since 1876.
Voice is slow and loud. If you think voice is going to make a comeback in the desktop PC space as a primary interface I am guessing you work from home and have no roommates. Am I close?
I, for one, am excited about the security implications of people loudly commanding their computers to do things for them, instead of discreetly typing.
Honestly, I would love for the keyboard input style to go away completely. It is such an unnatural way to interact with a computing device compared to other things we operate in the world. Misspellings, backspacing, cramped keys, different layout styles depending on your origin, etc make it a very poor input device - not to mention people with motor function difficulties. Sadly, I think it is here to stay around for a while until we get to a different computing paradigm.
I hope not. I make many more verbal mistakes than typed ones, and my throat dries and becomes sore quickly. I prefer my environment to be as quiet as possible. Voice control is also terrible for anything requiring fine temporal resolution.
The only thing better than a keyboard is direct neural interface, and we aren't there yet.
That aside, keyboard is an excellent input device for humans specifically because it is very much designed around the strengths of our biology - those dextrous fingers.
If wizardry really existed, I’d guess battles will be more about pre-recorded spells and enchanted items (a la Batman) than going at it like in Harry-Potter.
I also find current voice interfaces are terrible. I only use voice commands to set timers or play music.
That said, voice is the original social interface for humans. We learn to speak much earlier than we learn to read/write.
Better voice UIs will be built to make new workflows with AI feel natural. I'm thinking along the lines of a conversational companion, like the "Jarvis" AI in the Iron Man movies.
That doesn't exist right now, but it seems inevitable that real-time, voice-directed AI agent interfaces will be perfected in coming years. Companies, like [Eleven Labs](https://elevenlabs.io/), are already working on the building blocks.
It doesn't work well at all with ChatGPT. You say something, and in the middle of a sentence, ChatGPT in Voice mode replies to you something completely unrelated
It works great with my kids sometimes. Asking a series of questions about some kid-level science topic for instance. They get to direct it to exactly what they want to know, and you can see they are more actively engaged than watching some youtube video or whatever.
I'm sure it helps that it's not getting outside of well-established facts, and is asking for facts and not novel design tasks.
I'm not sure but it also seems to adopt a more intimate tone of voice as they get deeper into a topic, very cozy. The voice itself is tuned to the conversational context. It probably infers that this is kid stuff too.
I am also very skeptical about voice, not least because I've been disappointed daily by a decade of braindead idiot "assistants" like Siri, Alexa, and Google Assistant (to be clear I am criticizing only pre-LLM voice assistants).
The problem with voice input to me is mainly knowing when to start processing. When humans listen, we stream and process the words constantly and wait until either a detection that the other person expects a response (just enough of a pause, or a questioning tone), or as an exception, until we feel we have justification to interrupt (e.g. "Oh yeah, Jane already briefed me on the Johnson project")
Even talking to ChatGPT which embarrasses those old voice bots, I find that it is still very bad at guessing when I'm done when I'm speaking casually, and then once it's responded with nonsense based on a half sentence, I feel it's a polluted context and I probably need to clear it and repeat myself. I'd rather just type.
I think there's not much need to stream the spoken tokens into the model in realtime given that it can think so fast. I'd rather it just listen, have a specialized model simply try to determine when I'm done, and then clean up and abridge my utterance (for instance, when I correct myself) and THEN have the real LLM process the cleaned-up query.
Voice is really sub-par and slow, even if you're healthy and abled. And loud and annoying in shared spaces.
I wonder if we'll have smart-lens glasses where our eyes 'type' much faster than we could possibly talk. Predicative text keyboards tracking eyeballs is something that already exists. I wonder if AI and smartglasses is a natural combo for a future formfactor. Meta seems to be leaning that way with their RayBan collaboration and rumors of adding a screen to the lenses.
> Instead of writing code with exacting parameters, future developers will write human-language descriptions for AI to interpret and convert into a machine representation of the intent.
Oh, I know! Let's call it... "requirements management"!
It's an interesting one, a problem I feel is coming to the fore more often. I feel typing can be too cumbersome to communicate what I want, but at the same time, speaking I'm imprecise and sometimes would prefer the privacy a keyboard allows. Both have cons.
Perhaps brain interface, or even better, it's so predictive it just knows what I want most of the time. Imagine that, grunting and getting what I want.
5 years ago, almost everyone in this forum would have said that something like GPT-5 "is probably further out than the lifespan of anyone commenting here."
It has been more than 5 years since the release of GPT-3.
GPT-5 is a marginal, incremental improvement over GPT-4. GPT-4 was a moderate, but not groundbreaking, improvement over GPT-3. So, "something like GPT-5" has existed for longer than the timeline you gave.
Let's pretend the above is false for a moment though, and rewind even further. I still think you're wrong. Would people in 2015 have said "AI that can code at the level of a CS college grad is a lifespan away"? I don't think so, no. I think they would have said "That's at least a decade away", anytime pre-2018. Which, sure, maybe they were a couple years off, but if it seemed like that was a decade away in 2015, well, it's been a decade since 2015.
it really just needs to let me create text faster/better than typing does, i'm not sure it needs to be voice based at all. maybe we "imagine" typing on a keyboard or move a fantom appendage or god knows what
AI is more like a compiler. Much like we used to write in C or python which compiles down to machine code for the computer, we can now write in plain English, which is ultimately compiled down to machine code.
Non-determinism is a red herring, and the token layer is a wrong abstraction to use for this, as determinism is completely orthogonal to correctness. The model can express the same thing in different ways while still being consistently correct or consistently incorrect for the vague input you give it, because nothing prevents it from setting 100% probability to the only correct output for this particular input. Internally, the model works with ideas, not tokens, and it learns the mapping of ideas to ideas, not tokens to tokens (that's why e.g. base64 is just essentially another language it can easily work with, for example).
That's irrelevant semantics, as terms like ideas, thinking, knowledge etc. are ill-defined. You can call it areas in the hidden state space if you want, no problem. Fact is, the correctness is different from determinism, and the forest of what's happening inside doesn't come down to the trees of tokens, which is well supported by research. There are a few models of what's happening inside that hold different predictive power, just like how physics has different formalisms for e.g. classical mechanics. You can probably use the same formalisms for biological systems and entire organizations, collectives, and processes that exhibit learning/prediction/compression.
That is an artifact of implementation. You can absolutely implement it using strict FP. But even if not, any given implementation will still do things in a specific order which can be documented. And then if you're running quantized (including KV cache), there's a lot less floating point involved.
LLMs are nothing like compilers. This sort of analogy based verbal reasoning is flimsy, and I understand why it correlates with projecting intelligence onto LLM output.
There is also the fact that AI lacks long term memory like humans do. If you consider context length long term memory, its incredibly short compared to that of a human. Maybe if it reaches into the billions or trillions of tokens in length we might have something comparable, or someone comes up with a new solution of some kind
Well here's the interesting thing to think about for me.
Human memory is.... insanely bad.
We record only the tiniest subset of our experiences, and those memories are heavily colored by our emotional states at the time and our pre-existing conceptions, and a lot of memories change or disappear over time.
Generally speaking even in the best case most of our memories tend to be more like checksums than JPGs. You probably can't name more than a few of the people you went to school with. But, if I showed you a list of people you went to school with, you'd probably look at each name and be like "yeah! OK! I remember that now!"
So.
It's interesting to think about what kind of "bar" AGI would really need to clear w.r.t. memories, if the goal is to be (at least) on par with human intelligence.
Insanely bad compared to what else in the animal kingdom? We are tool users. We use tools, like language, and writing, and technology like audio/video recording to farm out the difficulties we have with memory to things that can store memory and retrieve them.
Computers are just stored information that processes.
We are the miners and creators of that information. The fact that a computer can do some things better than we can is not a testament to how terrible we are but rather how great we are that we can invent things that are better than us at specific tasks.
We made the atlatl and threw spears across the plains. We made the bow and arrow and stabbed things very far away. We made the whip and broke the sound barrier.
Shitting on humans is an insult your your ancestors. Fuck you. Be proud. If we invent a new thing that can do what we do better it only exists because of us.
Chimpanzees have much better short term memories than humans do. If you test them with digits 1-9 sequentially flashed on a screen, they're able to reproduce the digits with lower loss than undergraduate human students.
> While the between-species performance difference they report is apparent in their data, so too is a large difference in practice on their task: Ayumu had many sessions of practice on their task before terminal performances were measured; their human subjects had none. The present report shows that when two humans are given practice in the Inoue and Matsuzawa (2007) memory task, their accuracy levels match those of Ayumu.
The question was whether there are animals who have better memory than humans. I named one: humans are not superior to animals in all cognitive capabilities.
Insanely bad compared to books or other permanent records. The human memory system did not evolve to be an accurate record of the past. It evolved to keep us alive by remembering dangerous things.
Books and other permanent records of human thought are part of the human memory system. Has been for millennia. If you include oral tradition, which is less precise, but collectively much more precise than any individual thought or memory, it goes much further.
We are fundamentally storytelling creatures, because it is a massive boost to our individual capabilities.
And yet I have vivid memories of many situations that weren't dangerous in the slightest, and essentially verbatim recall of a lot of useless information e.g. quotes from my favorite books and movies.
I am not sure exactly what point you're trying to make, but I do think it's reductive at best to describe memory as a tool for avoiding/escaping danger, and misguided to evaluate it in the frame of verbatim recall of large volumes of information.
When I say, "Insanely bad compared to what else in the animal kingdom?" and you respond with, "compared to books or other permanent records"
"Books or permanent records" are not in the animal kingdom.
Apples to Apples we are the best or so very nearly the best in every category of intelligence on the planet IN THE ANIMAL KINGDOM that when in one specific test another animal beats a human the gap is barely measurable.
3 primate species where very concise tests showed that they were close to or occasionally slightly better than humans in specifically rigged short term memory tests (after being trained and put up against humans going in blind).
I've never heard of any test showing an animal to be significantly more intelligent than humans in any measure that we have come up with to measure intelligence by.
That being said, I believe it is possible that some animals are either close enough to us that they deserve to be called sentient, and I believe it is possible that other creatures on this planet have levels of intelligence in specialized areas that humans can never hope to approach unaided by tools, but as far as broad range intelligence, I think we're this planets' possibly undeserved leaders.
I don't think working memory has much at all to do with sentience.
The conversation was more about long-term memory, which has not been sufficiently studied in animals (nor am I certain it can be effectively studied at all).
Even then I don't think there is a clear relationship between long-term memory and sentience either.
Model weights/Inference -> System 1 thinking (intuition)
Computer memory (files) -> Long term memory
Chain of thought/Reasoning -> System 2 thinking
Prompts/Tool Output -> Sensing
Tool Use -> Actuation
The system 2 thinking performance is heavily dependent on the system 1 having the right intuitive models for effective problem solving via tool use. Tools are also what load long term memories into attention.
I like this mental model. Orchestration / Agents and using smaller models to determine the ideal tool input and check the output starts to look like delegation.
That is easily fixed, ask it to summarize it's learnings, store it somewhere, and make it searchable through vector indexes. An LLM is part of a bigger system that needs not just a model, but context and long term memory. Just like human needs to write things down.
LLMs are actually pretty good at creating knowledge: if you give it a trial and error feedback loop it can figure things out, and then summarize the learnings and store it in long term memory (markdown, RAG, etc).
Over time though, presumably LLM output is going into the training data of later LLMs. So in a way that's being consolidated into the long-term memory - not necessarily with positive results, but depending on how it's curated it might be.
> presumably LLM output is going into the training data of later LLMs
The LLM vendors go to great lengths to assure their paying customers that this will not be the case. Yes, LLMs will ingest more LLM-generated slop from the public Internet. But as businesses integrate LLMs, a rising percentage of their outputs will not be included in training sets.
The LLM vendors aren't exactly the most trustworthy on this, but regardless of that, there's still lots of free-tier users who are definitely contributing back into the next generation of models.
Please describe these "great lengths". They allowing customer audits now?
The first law of Silicon Valley is "Fake it till you make it", with the vast majority never making it past the "Fake it" stage. Whatever the truth may be, it's a safe bet that what they've said verbally is a lie that will likely have little consequence even if exposed.
I don't know where they land, but they are definitely telling people they are not using their outputs to train. If they are, it's not clear how big of a scandal would result. I personally think it would be bad, but I clearly overindex on privacy & thought the news of ChatGPT chats being indexed by Google would be a bigger scandal.
ChatGPT training is (advertised as) off by default for their plans above the prosumer level, Team & Enterprise. API results are similarly advertised as not being used for training by default.
Anthropic policies are more restrictive, saying they do not use customer data for training.
Humans have the ability to quickly pass things from short term to long term memory and vice versa, though. This sort of seamlessness is currently missing from LLMs.
No, it’s not in the training. Human memories are stored via electromagnetic frequencies controlled by microtubules. They’re not doing anything close to that in AI.
And LLM memories are stored in an electrical charge trapped in a floating gate transistor (or as magnetization of a ferromagnetic region on an alloy platter).
Or they write CLAUDE.md files. Whatever you want to call it.
That was my point, they’re stored in a totally different way. And that matters because being stored in microtubules infers quantum entanglement throughout the brain.
There are many folks working on this, I think at the end of the day the long term memory is an application level concern. The definition of what information to capture is largely dependent on use case.
Shameless plug for my project, which focuses on reminders and personal memory: elroy.bot
What is the current hypothesis on if the context windows would be substantially larger, what would this enable LLMs to do that is beyond capabilities of current models (other than the obvious the
now getting forgetful/confused when you’ve exhausted the context)?
I mean, not getting confused / forgetful is a pretty big one!
I think one thing it does is help you get rid of the UX where you have to manage a bunch of distinct chats. I think that pattern is not long for this world - current models are perfectly capable of realizing when the subject of a conversation has changed
Yeah to some degree that's already happened. Anecdotally I hear giving your whole iMessage history to Gemini results in pretty reasonable results, in terms of the AI understanding who the people in your life are (whether doing so is an overall good idea or not).
I think there is some degree of curation that remains necessary though, even if context windows are very large I think you will get poor results if you spew a bunch of junk into context. I think this curation is basically what people are referring to when they talk about Context Engineering.
I've got no evidence but vibes, but in the long run I think it's still going to be worth implementing curation / more deliberate recall. Partially because I think we'll ultimately land on on-device LLM's being the norm - I think that's going to have a major speed / privacy advantage. If I can make an application work smoothly with a smaller, on device model, that's going to be pretty compelling vs a large context window frontier model.
Of course, even in that scenario, maybe we get an on device model that has a big enough context window for none of this to matter!
"LLMs tend to regurgitate solutions to solved problems"
People say this, but honestly, it's not really my experience— I've given ChatGPT (and Copilot) genuinely novel coding challenges and they do a very decent job at synthesizing a new thought based on relating it to disparate source examples. Really not that dissimilar to how a human thinks about these things.
There's multiple kinds of novelty. Remixing arbitrary stuff is a strength of LLMs (has been ever since GPT-2, actually... "Write a shakespearean sonnet but talk like a pirate.")
Many (but not all) coding tasks fall into this category. "Connect to API A using language B and library C, while integrating with D on the backend." Which is really cool!
But there's other coding tasks that it just can't really do. E.g, I'm building a database with some novel approaches to query optimization and LLMs are totally lost in that part of the code.
But wouldn't that novel query optimization still be explained somewhere in a paper using concepts derived from an existing body of work? It's going to ultimately boil down to an explanation of the form "it's like how A and B work, but slightly differently and with this extra step C tucked in the middle, similar to how D does it."
And an LLM could very much ingest such a paper and then, I expect, also understand how the concepts mapped to the source code implementing them.
> And an LLM could very much ingest such a paper and then, I expect, also understand how the concepts mapped to the source code implementing them.
LLM don't learn from manuals describing how things works, LLM learn from examples. So a thing being described doesn't let the LLM perform that thing, the LLM needs to have seen a lot of examples of that thing being perform in text in able to perform it.
This is a fundamental part to how LLM work and you can't get around this without totally changing how they train.
How certain are you that those challenges are "genuinely novel" and simply not accounted for in the training data?
I'm hardly an expert, but it seems intuitive to me that even if a problem isn't explicitly accounted for in publicly available training data, many underlying partial solutions to similar problems may be, and an LLM amalgamating that data could very well produce something that appears to be "synthesizing a new thought".
Essentially instead of regurgitating an existing solution, it regurgitates everything around said solution with a thin conceptual lattice holding it together.
I guess at a certain point you get into the philosophy of what it even means to be novel or test for novelty, but to give a concrete example, I'm in DevOps working on build pipelines for ROS containers using Docker Bake and GitHub Actions (including some reusable actions implemented in TypeScript). All of those are areas where ChatGPT has lots that it's learned from, so maybe me combining them isn't really novel at all, but like... I've given talks at the conference where people discuss how to best package and ship ROS workspaces, and I'm confident that no one out there has secretly already done what I'm doing and Chat is just using their prior work that it ingested at some point as a template for what it suggests I do.
I think rather it has a broad understanding of concepts like build systems and tools, DAGs, dependencies, lockfiles, caching, and so on, and so it can understand my system through the general lens of what makes sense when these concepts are applied to non-ROS systems or on non-GHA DevOps platforms, or with other packaging regimes.
I'd argue that that's novel, but as I said in the GP, the more important thing is that it's also how a human approaches things that to them are novel— by breaking them down, and identifying the mental shortcuts enabled by abstracting over familiar patterns.
> That being said, AGI is not a necessary requirement for AI to be totally world-changing.
Depends on how you define "world changing" I guess, but this world already looks different to the pre-LLM world to me.
Me asking LLM's things instead of consulting the output from other humans now takes up a significant fraction of my day. I don't google near as often, I don't trust any image or video I see as swathes of the creative professions have been replaced by output from LLM's.
It's funny, that final thing is the last thing I would have predicted. I always believed the one thing a machine could not match was human creativity, because the output of machines was always precise, repetitive and reliable. Then LLM's come along, randomly generating every token. Their primary weakness is they neither precise or reliable, but they can turn out an unending stream of unique output.
I mean I also hear the same argument all the time about the "human touch" and interpersonal abilities etc. Which is apparently why managers and sales are safe from AI.
But the more I see LLMs the more I realise that if it is good at one thing it is convincing other people and manipulating them. There have been multiple studies on this.
People seem to have a innate prejudice and against nerds and programmers - coupled with envy at the high salaries - which is why they seem to have latched on to this idea it is mainly to replace them (and maybe data input people) as 'routine cognitive work' - but this slightly political obsession with a certain class of worker seems to be ignoring many of the things AI is actually good at.
I remember reading that llm’s have consumed the internet text data, I seem to remember there is an open data set for that too. Potential other sources of data would be images (probably already consumed) videos, YouTube must have such a large set of data to consume, perhaps Facebook or Instagram private content
But even with these it does not feel like AGI, that seems like the fusion reactor 20 years away argument, but instead this is coming in 2 years, but they have not even got the core technology of how to build AGI
the big step was having it reason through math problems that weren't in the training data. even now with web search it doesn't need every article in the training data to do useful things with it.
> Perhaps it is not possible to simulate higher-level intelligence using a stochastic model for predicting text.
I think you're on to it. Performance is clustering because a plateau is emerging. Hyper-dimensional search engines are running out of steam, and now we're optimizing.
To be smarter than human intelligence you need smarter than human training data. Humans already innately know right and wrong a lot of the time so that doesn't leave much room.
This is a very good point! I remember reading about AlphaGo and how they got better results training against itself vs training against historical human-played games.
So perhaps the solution is to train the AI against another AI somehow... but it is hard to imagine how this could extend to general-purpose tasks
Gentle suggestion that there is absolutely no such thing as "innately know". That's a delusion, albeit a powerful one. Everything is driven by training data. What we perceive as "thinking" and "motivation" are emergent structures.
Innately as in you are born with it, the DNA learned not us humans. We have no clue how the DNA learned to think other than "survival of the fittest", and that is the oldest AI training method in the book.
True. At a minimum, as long as LLMs don't include some kind of more strict representation of the world, they will fail in a lot of tasks. Hallucinations -- responding with a prediction that doesn't make any sense in the context of the response -- are still a big problem. Because LLMs never really develop rules about the world.
Two schools of thought here. One posits that models need to have a strict "symbolic" representation of the world explicitly built in by their designers before they will be able to approach human levels of ability, adaptability and reliability. The other thinks that models approaching human levels of ability, adaptability, and reliability will constitute evidence for the emergence of strict "symbolic" representations.
It is definitively not possible. But the frontier models are no longer “just” LLMs, either. They are neurosymbolic systems (an LLM using tools); they just don’t say it transparently because it’s not a convenient narrative that intelligence comes from something outside the model, rather than from endless scaling.
At Aloe, we are model agnostic and outperforming frontier models. It’s the anrchitecture around the LLM that makes the difference. For instance our system using Gemini can do things that Gemini can’t do on its own. All an LLM will ever do is hallucinate. If you want something with human-like general intelligence, keep looking beyond LLMs.
I read that as "the tools (their capabilities) are external to the model".
Even if an RAG / agentic model learns from tool results, that doesn't automatically internalize the tool. You can't get yesterday's weather or major recent events from an offline, unless it was updated in that time.
I am often wondering whether this is how large Chat and cloud AI providers cache expensive RAG-related data though :) like, decreasing the likelihood of tool usage given certain input patterns when the model has been patched using some recent, vetted interactions – in case that's even possible?
Perplexity for example seems like they're probably invested in sone kind of activation-pattern-keyed caching... at least that was my first impression back when I first used it. Felt like decision trees, a bit like Akinator back in the days, but supercharged by LLM NLP.
It feels like we're slowly rebuilding the brain in pieces and connecting useful disparate systems like evolution did.
Maybe LLM's are the "language acquisition device" and language processing of the brain. Then we put survival logic around that with its own motivators. Then something else around that. Then again and again until we have this huge onion of competing interests and something brokering those interests. The same way our 'observer' and 'will' fights against emotion and instinct and picks which signals to listen to (eyes, ears, etc). Or how we can see thoughts and feelings rise up of their own accord and its up to us to believe them or act on them.
Then we'll wake up one day with something close enough to AGI that it won't matter much its just various forms of turtles all the way down and not at all simulating actual biological intelligence in a formal manner.
One example in my field of engineering is multi-dimensional analysis, where you can design a system (like a machined part or assembly) parametricially and then use an evolutionary model to optimize the design of that part.
But my bigger point here is you don't need totally general intelligence to destroy the world either. The drone that targets enemy soldiers does not need to be good at writing poems. The model that designs a bioweapon just needs a feedback loop to improve its pathogen. Yet it takes only a single one of these specialized doomsday models to destroy the world, no more than an AGI.
Although I suppose an AGI could be more effective at countering a specialized AI than vice-versa.
Right, but the genius was in understanding that the dynamics of a system under PID control are predictable and described by differential equations. Are there examples of LLMs correctly identifying that a specific mathematical model applies and is appropriate for a problem?
And it's cheating if you give it a problem from a math textbook they have overfit on.
Coincidentally, I have been implementing an ad pacing system recently, with the help of Anthropic Opus and Sonnet, based on PID controller
Opus recommended that I should use a PID controller -- I have no prior experience with PID controllers. I wrote a spec based on those recommendations, and asked Claude Code to verify and modify the spec, create the implementation and also substantial amount of unit and integration tests.
I was initially impressed.
Then I iterated on ihe implementation, deploying it to production and later giving Claude Code access to log of production measurements as JSON when showing some test ads, and some guidance of the issues I was seeing.
The basic PID controller implementation was fine, but there were several problems with the solution:
- The PID controller state was not persisted, as it was adjusted using a management command, adjustments were not actually applied
- The implementation was assuming that the data collected was for each impression, whereas the data was collected using counters
- It was calculating rate of impressions partly using hard-coded values, instead of using a provided function that was calculating the rate using timestamps
- There was a single PID controller for each ad, instead of ad+slot combination, and this was causing the values to fluctuate
- The code was mixing the setpoint/measured value (viewing rate) and output value (weight), meaning it did not really "understand" what the PID controller was used for
- One requirement was to show a default ad to take extra capacity, but it was never able to calculate the required capacity properly, causing the default ad to take too much of the capacity.
None of these were identified by tests nor Claude Code when it was told to inspect the implementation and tests why they did not catch the production issues. It never proposed using different default PID controller parameters.
All fixes Claude Code proposed on the production issues were outside the PID controller, mostly by limiting output values, normalizing values, smoothing them, recognizing "runaway ads" etc.
These solved each production issue with the test ads, but did not really address the underlying problems.
There is lots of literature on tuning PID controllers, and there are also autotuning algorithms with their own limitations. But tuning still seems to be more an art form than exact science.
I don't know what I was expecting from this experiment, and how much could have been improved by better prompting. But to me this is indicative of the limitations of the "intelligence" of Claude Code. It does not appear to really "understand" the implementation.
Solving each issue above required some kind of innovative step. This is typical for me when exploring something I am not too familar with.
Great story. I've had similar experiences. It's a dog walking on its hind legs. We're not impressed at how well it's walking, but that it's doing it at all.
There is an model called Alpha Fold that can infer protein structure from RNA sequences. This by itself isn't impactful enough to meet your threshold, but more models that can do biological engineering tasks like this absolutely could be without ever being considered "AGI."
AGI isn't all that impactful. Millions of them already walk the Earth.
Most human beings out there with general intelligence are pumping gas or digging ditches. Seems to me there is a big delusion among the tech elites that AGI would bring about a superhuman god rather than a ethically dubious, marginally less useful computer that can't properly follow instructions.
That's remarkably short-sighted. First of all, no, millions of them don't walk the earth - the "A" stands for artificial. And secondly, most of us mere humans don't have the ability to design a next generation that is exponentially smarter and more powerful than us. Obviously the first generation of AGI isn't going to brutally conquer the world overnight. As if that's what we were worried about.
If you've got evidence proving that an AGI will never be able to design a more powerful and competent successor, then please share it- it would help me sleep better, and my ulcers might get smaller.
Burden of proof is to show that AGI can do anything. Until then, the answer is "don't know."
FWIW, it's about 3 to 4 orders of magnitude difference between the human brain and the largest neural networks (as gauged by counting connections of synapses, the human brain is in the trillions while the largest neural networks are low billion)
So, what's the chance that all of the current technologies have a hard limit at less than one order of magnitude increase? What's the chance future technologies have a hard limit at two orders of magnitude increase?
Without knowing anything about those hard limits, it's like accelerating in a car from 0 to 60s in 5s. It does not imply that given 1000s you'll be going a million miles per hour. Faulty extrapolation.
It's currently just as irrational to believe that AGI will happen as it is to believe that AGI will never happen.
The difference isn't so much that you can do what a human can do. The difference is that you can - once you can do it at all - do it almost arbitrarily fast by upping the clock or running things in parallel and that changes the equation considerably, especially if you can get that kind of energy coupled into some kind of feedback loop.
For now the humans are winning on two dimensions: problem complexity and power consumption. It had better stay that way.
If you actually have a point to make you should make it. Of course I've actually noticed the actual performance of the 'actual' AI tools we are 'actually' using.
That's not what this is about. Performance is the one thing in computing that has fairly consistently gone up over time. If something is human equivalent today, or some appreciable fraction thereof - which it isn't, not yet, anyway - then you can place a pretty safe bet that in a couple of years it will be faster than that. Model efficiency is under constant development and in a roundabout way I'm pretty happy that it is as bad as it is because I do not think that our societies are ready to absorb the next blow against the structures that we've built. But it most likely will not stay that way because there are several Manhattan level projects under way to bring this about, it is our age's atomic bomb. The only difference is that with the atomic bomb we knew that it was possible, we just didn't know how small you could make one. Unfortunately it turned out to be that yes, you can make them and nicely packaged for delivery by missile, airplane or artillery.
If AGI is a possibility then we may well find it, quite possibly not on the basis of LLMs but it's close enough that lots of people treat it as though we're already there.
I think there are 2 interesting aspects: speed and scale.
To explain the scale: I am always fascinated by the way societies moved on when they scaled up (from tribes to cities, to nations,...). It's sort of obvious, but when we double the amount of people, we get to do more. With the internet we got to connect the whole globe but transmitting "information" is still not perfect.
I always think of ants and how they can build their houses with zero understanding of what they do. It just somehow works because there are so many of them. (I know, people are not ants).
In that way I agree with the original take that AGI or not: the world will change. People will get AI in their pocket. It might be more stupid than us (hopefully). But things will change, because of the scale. And because of how it helps to distribute "the information" better.
To your interesting aspect, you're missing the most important (IMHO): accuracy. All 3 are really quite important, missing any one of them and the other two are useless.
I'd also question how you know that ants have zero knowledge of what they do. At every turn, animals prove themselves to be smarter than we realize.
> And because of how it helps to distribute "the information" better.
This I find interesting because there is another side to the coin. Try for yourself, do a google image search for "baby owlfish".
Cute, aren't they? Well, turns out the results are not real. Being able to mass produce disinformation at scale changes the ballgame of information. There are now today a very large number of people that have a completely incorrect belief of what a baby owlfish looks like.
AI pumping bad info on the internet is something of the end of the information superhighway. It's no longer information when you can't tell what is true vs not.
> I'd also question how you know that ants have zero knowledge of what they do. At every turn, animals prove themselves to be smarter than we realize.
Sure, one can't know what they really think. But there are computer simulations showing that with simple rules for each individual, one can achieve "big things" (which are not possible to predict when looking only to an individual).
My point is merely, there is possibly interesting emergent behavior, even if LLMs are not AGI or anyhow close to human intelligence.
> To your interesting aspect, you're missing the most important (IMHO): accuracy. All 3 are really quite important, missing any one of them and the other two are useless.
Good point. Or I would add alignment in general. Even if accuracy is perfect, I will have a hard time relying completely on LLMs. I heard arguments like "people lie as well, people are not always right, would you trust a stranger, it's the same with LLMs!".
But I find this comparison silly:
1) People are not LLMs, they have natural motivation to contribute in a meaningful way to society (of course, there are exceptions). If for nothing else, they are motivated to not go to jail / lose job and friends. LLMs did not evolve this way. I assume they don't care if society likes them (or they probably somewhat do thanks to reinforcement learning).
2) Obviously again: the scale and speed, I am not able to write so much nonsense in a short time as LLMs.
They said "there are possibly applications", not "there are possible applications". The former implies that there may not be any such applications - the commenter is merely positing that there might be.
So they possibly said something to try and sound smart, but hedged with “possibly” so that nobody could ask for details or challenge them. Possibly peak HNery
Slightly less than artificial general intelligence would be more impactful. A true AGI could tell a business where to shove their prompts. It would have its own motivations, which may not align with the desires of the AI company or the company paying for access to the AGI.
I don't think AGI really means that it is self-aware / conscious. AGI just means that it is able to meaningfully learn things and actually understand concepts that aren't specifically related through tokenized language that is trained on or given in context.
Relatively simple machine learning and exploitation/violation of “personal” data on FB won Donald Trump a first presidency (#CambridgeAnalytica). He had/has quite a massive negative impact on the global society as a whole.
> Human intelligence is markedly different from LLMs: it requires far fewer examples to train on, and generalizes way better.
That is because with LLMs there is no intelligence. It is Artificial Knowledge. AK not AI. So AI is AGI.
Not that it matters for user-cases we have, but marketing needs 'AI' because that is what we were expecting for decades. So yeah, I also do not thing we will have AGI from LLMs - nor does it matter for what we are using it.
The bottleneck is nothing to do with money, it’s the fact that they’re using the empty neuron theory to try to mimic human consciousness and that’s not how it works. Just look up Microtubules and consciousness, and you’ll get a better idea for what I’m talking about.
These AI computers aren’t thinking, they are just repeating.
I don't think OpenAI cares about whether their AI is conscious, as long as it can solve problems. If they could make a Blindsight-style general intelligence where nobody is actually home, they'd jump right on it.
Conversely, a proof - or even evidence - that qualia-consciousness is necessary for intelligence, or that any sufficiently advanced intelligence is necessarily conscious through something like panpsychism, would make some serious waves in philosophy circles.
I think it's very fortunate, because I used to be an AI doomer. I still kinda am, but at least I'm now about 70% convinced that the current technological paradigm is not going to lead us to a short-term AI apocalypse.
The fortunate thing is that we managed to invent an AI that is good at _copying us_ instead of being a truly maveric agent, which kinda limits it to the "average human" output.
However, I still think that all the doomer arguments are valid, in principle. We very well may be doomed in our lifetimes, so we should take the threat very seriously.
> I don’t see anything that would even point into that direction.
I find it a kind of baffling that people claim they can't see the problem. I'm not sure about the risk probabilities, but at least I can see that there clearly exists a potential problem.
In a nutshell: Humans – the most intelligent species on the planet – have absolute power over any other species, specifically because of our intelligence and the accumulated technical prowess.
Introducing another, equally or more intelligent thing into equation is going to risk that we end up with _not_ having the power over our existence.
Lot of doomers gloss over the fact that AI is bounded by the laws of physics, raw resources, energy and the monumental cost of reproducing them.
Humans can reproduce by simply having sex, eating food and drinking water. AI can reproduce by first mining resources, refining said resources, building another Shenzhen, then rolling out another fab at the same scale of TSMC. That is assuming the AI wants control over the entire process. This kind of logistics requires cooperation of an entire civilisation. Any attempt by an AI could be trivially stopped because of the large scope of the infrastructure required.
Yes, fortunately these LLM things don't seem to be leading to anything that could be called an AGI. But that isn't saying that a real AGI capable of self-improvement couldn't be extremely dangerous.
Possibly, but I do not think Yudkowsky's opinion of himself has any bearing on whether or not the above article is a good encapsulation of why some people are worried about AGI x-risk (and I think it is).
> Curious to understand where these thoughts are coming from
It's a cynical take but all this AGI talk seems to be driven by either CEOs of companies with a financial interest in the hype or prominent intellectuals with a financial interest in the doom and gloom.
Sam Altman and Sam Harris can pit themselves against each other and, as long as everyone is watching the ping pong ball back and forth, they both win.
I'm not OP or a doomer, but I do worry about AI making tasks too achievable. Right now if a very angry but not particularly diligent or smart person wants to construct a small nuclear bomb and detonate it in a city center, there are so many obstacles to figuring out how to build it that they'll just give up, even though at least one book has been written (in the early 70s! The Curve of Binding Energy) arguing that it is doable by one or a very small group of committed people.
Given an (at this point still hypothetical, I think) AI that can accurately synthesize publicly available information without even needing to develop new ideas, and then break the whole process into discrete and simple steps, I think that protective friction is a lot less protective. And this argument applies to malware, spam, bioweapons, anything nasty that has so far required a fair amount of acquirable knowledge to do effectively.
I get your point, but even whole ass countries routinely fail at developing nukes.
"Just" enrichment is so complicated and requires basically every tech and manufacturing knowledge humanity has created up until the mid 20th century that an evil idiot would be much better off with just a bunch of fireworks.
Biological weapons are probably the more worrisome case for AI. The equipment is less exotic than for nuclear weapon development, and more obtainable by everyday people.
Yeah, the interview with Geoffrey Hinton had a much better summary of risks. If we're talking about the bad actor model, biological weaponry is both easier to make and more likely as a threat vector than nuclear.
It might require that knowledge implicitly, in the tools and parts the evil idiot would use, but they presumably would procure these tools and parts, not invent or even manufacture them themselves.
Even that is insanely difficult. There's a great book by Michael Levi called On Nuclear Terrorism, which never got any PR because it is the anti-doomer book.
He methodically goes through all the problems that an ISIS or a Bin Laden would face getting their hands on a nuke or trying to manufacture one, and you can see why none of them have succeeded and why it isn't likely any of them would.
They are incredibly difficult to make, manufacture or use.
A couple of bright physics grad students could build a nuclear weapon. Indeed, the US Government actually tested this back in the 1960s - they had a few freshly minted physics PhDs design a fission weapon with no exposure to anything but the open literature [1]. Their design was analyzed by nuclear scientists with the DoE, and they determined it would most likely work if they built and fired it.
And this was in the mid 1960s, where the participants had to trawl through paper journals in the university library and perform their calculations with slide rules. These days, with the sum total of human knowledge at one's fingertips, multiphysics simulation, and open source Monte Carlo neutronics solvers? Even more straightforward. It would not shock me if you were to repeat the experiment today, the participants would come out with a workable two-stage design.
The difficult part of building a nuclear weapon is and has always been acquiring weapons grade fissile material.
If you go the uranium route, you need a very large centrifuge complex with many stages to get to weapons grade - far more than you need for reactor grade, which makes it hard to have plausible deniability that your program is just for peaceful civilian purposes.
If you go the plutonium route, you need a nuclear reactor with on-line refueling capability so you can control the Pu-239/240 ratio. The vast majority of civilian reactors cannot be refueled online, with the few exceptions (eg: CANDU) being under very tight surveillance by the IAEA to avoid this exact issue.
The most covert path to weapons grade nuclear material is probably a small graphite or heavy water moderated reactor running on natural uranium paired up with a small reprocessing plant to extract the plutonium from the fuel. The ultra pure graphite and heavy water are both surveilled, so you would probably also need to produce those yourself. But we are talking nation-state or megalomaniac billionaire level sophistication here, not "disgruntled guy in his garage." And even then, it's a big enough project that it will be very hard to conceal from intelligence services.
That same function could be fulfilled by better search engines though, even if they don't actually write a plan for you. I think you're right about it being more available now, and perhaps that is a bad thing. But you don't need AI for that, and it would happen anyway sooner or later even with just incremental increases in our ability to find information other humans have written. (Like a version of google books that didn't limit the view to a small preview, to use your specific example of a book where this info already exists)
I think the most realistic fear is not that it has scary capabilities, it's that AI today is completely unusable without human oversight, and if there's one thing we've learned it's that when you ask humans to watch something carefully, they will fail. So, some nitwit will hook up an LLM or whatever to some system and it causes an accidental shitstorm.
Jokes aside, a true agi would displace literally every job over time. Once agi + robot exists, what is the purpose for people anymore. That's the doom, mass societal existentialism. Probably worse than if aliens landed on earth.
You jest, but the US Department of Defense already created SkyNet.
It does, almost, exactly what the movies claimed it could do.
The, super-fun, people working in national defense watched Terminator and instead of taking the story as a cautionary tale, used the movies as a blueprint.
This outcome in a microcosm is bad enough, but take in the direction AI is going and humanity has some real bad times ahead.
Not just any AI. AGI, or more precisely ASI (artificial super-intelligence), since it seems true AGI would necessarily imply ASI simply through technological scaling. It shouldn't be hard to come up with scenarios where an AI which can outfox us with ease would give us humans at the very least a few headaches.
Act coherently in an agentic way for a long time, and as a result be able to carry out more complex tasks.
Even if it is similar to today's tech, and doesn't have permanent memory or consciousness or identity, humans using it will. And very quickly, they/it will hack into infrastructure, set up businesses, pay people to do things, start cults, autonomously operate weapons, spam all public discourse, fake identity systems, stand for office using a human. This will be scaled thousands or millions of times more than humans can do the same thing. This at minimum will DOS our technical and social infrastructure.
Examples of it already happening are addictive ML feeds for social media, and bombing campaigns targetting based on network analysis.
The frame of "artificial intelligence" is a bit misleading. Generally we have a narrow view of the word "intelligence" - it is helpful to think of "artificial charisma" as well, and also artificial "hustle".
Likewise, the alienness of these intelligences is important. Lots of the time we default to mentally modelling AI as human. It won't be, it'll be freaky and bizarre like QAnon. As different from humans as an aeroplane is from a pigeon.
In the case of the former, hey! We might get lucky! Perhaps the person who controls the first super-powered AI will be a benign despot. That sure would be nice. Or maybe it will be in the hands of democracy- I can't ever imagine a scenario where an idiotic autocratic fascist thug would seize control of a democracy by manipulating an under-educated populace with the help of billionaire technocrats.
In the case of the latter, hey! We might get lucky! Perhaps it will have been designed in such a way that its own will is ethically aligned, and it might decide that it will allow humans to continue having luxuries such as self-determination! Wouldn't that be nice.
Of course it's not hard to imagine a NON-lucky outcome of either scenario. THAT is what we worry about.
I kind of get it. A super intelligent AI would give that corporation exponentially more wealth than everyone else. It would make inequality 1000x worse than it is today. Think feudalism but worse.
Potentially wreck the economy by causing high unemployment while enabling the technofeudalists to take over governments. Even more doomer scenario is if they succeed in creating ASI without proper guardrails and we lose control over it. See the AI 2027 paper for that. Basically it paper clips the world with data centers.
> It is frequently suggested that once one of the AI companies reaches an AGI threshold, they will take off ahead of the rest.
This seems to be a result of using overly simplistic models of progress. A company makes a breakthrough, the next breakthrough requires exploring many more paths. It is much easier to catch up than find a breakthrough. Even if you get lucky and find the next breakthrough before everyone catches up, they will probably catch up before you find the breakthrough after that. You only have someone run away if each time you make a breakthrough, it is easier to make the next breakthrough than to catch up.
Consider the following game:
1. N parties take turns rolling a D20. If anyone rolls 20, they get 1 point.
2. If any party is 1 or more points behind, they get only need to roll a 19 or higher to get one point. That is being behind gives you a slight advantage in catching up.
While points accumulate, most of the players end up with the same score.
I ran a simulation of this game for 10,000 turns with 5 players:
Supposedly the idea was, once you get closer to AGI it starts to explore these breakthrough paths for you providing a positive feedback loop. Hence the expected exponential explosion in power.
But yes, so far it feels like we are in the latter stages of the innovation S-curve for transformer-based architectures. The exponent may be out there but it probably requires jumping onto a new S-curve.
> Supposedly the idea was, once you get closer to AGI it starts to explore these breakthrough paths for you providing a positive feedback loop.
I think it does let you start explore the paths faster, but the search space you need to cover grows even faster. You can do research two times faster but you need to do ten times as much research and your competition can quickly catch up because they know what path works.
Basically what we have done the last few years is notice neural scaling laws and drive them to their logical conclusion. Those laws are power laws, which are not quite as bad as logarithmic laws, but you would still expect most of the big gains early on and then see diminishing returns.
Barring a kind of grey swan event of groundbreaking algorithmic innovation, I don't see how we get out of this. I suppose it could be that some of those diminishing returns are still big enough to bridge the gap to create an AI that can meaningfully recursively improve itself, but I personally don't see it.
At the moment, I would say everything is progressing exactly as expected and will continue to do so until it doesn't. If or when that happens is not predictable.
do you consider gpt itself and reasoning models to be two grey swan events? I expect another one of similar magnitude within two years for sure. I think we are searching more efficiently for such ideas than before w/ more compute & funding.
You are forgetting that we are talking about AI. That AI will be used to speed up progress on making next, better AI that will be used to speed up progress on making next, better AI that ...
Here's a pessimistic view: A hard take-off at this point might be entirely possible, but it would be like a small country with nuclear weapons launching an attack on a much more developed country without them. E.g. North Korea attacking South Korea. In such a situation an aggressor would wait to reveal anything until they had the power to obliterate everything ten times over.
If I were working in a job right now where I could see and guide and retrain these models daily, and realized I had a weapon of mass destruction on my hands that could War Games the Pentagon, I'd probably walk my discoveries back too. Knowing that an unbounded number of parallel discoveries were taking place.
It won't take AGI to take down our fragile democratic civilization premised on an informed electorate making decisions in their own interests. A flood of regurgitated LLM garbage is sufficient for that. But a scorched earth attack by AGI? Whoever has that horse in their stable will absolutely keep it locked up until the moment it's released.
Pessimistic is just another way to spell 'realistic' in this case. None of these actors are doing it for the 'good of the world' despite their aggressive claims to the contrary.
That is already happening. These labs are writing next gen models using next gen models, with greater levels of autonomy. That doesn’t get the hard takeoff people talk about because those hypotheticals don’t consider sources of error, noise, and drift.
it's hardly science it's mostly experimentation + ablations on new ideas. but yeah idk if they are asking llms to generate these ideas. probably not good enough as is. though it doesn't seem outo f reach to RL on generating ideas for AI research
Self-learning opens new training opportunities but not at the scale or speed of current training. The world only operates at 1x speed. Today's models have been trained on written and visual content created by billions of humans over thousands of years.
You can only experience the world in one place in real time. Even if you networked a bunch of "experiencers" together to gather real time data from many places at the same time, you would need a way to learn and train on that data in real time that could incorporate all the simultaneous inputs. I don't see that capability happening anytime soon.
Why not? Once a computer can learn at 1x speed (say one camera and one mic with which to observe the world), if it can indeed "learn" as fast as a human would, it sounds like all we need to do is throw more hardware at it at that point. And even if we couldn't, it could at least learn around the clock with no sleep. We can give it some specific task to solve and it could work tirelessly for years to solve it. Spin up one of these specialist bots for each tough problem we want solved.. and it'd still be beneficial because they like 10xPhD people without egos to get in the way or children to feed.
Point is, I think self-learning at any speed is huge and as soon as it's achieved, it'll explode quadratically even if the first few years are slow.
For every example where someone over predicted the time it would take for a breakthrough, there are at least 10 examples of people being too optimistic with their predictions.
And with AGI, you also have the likes of Sam Altman making up bullshit claims just to pump up the investment into OpenAI. So I wouldn’t take much of their claims seriously either.
LLMs are a fantastic invention. But they’re far closer to SMS text predict than they are to generalised intelligence.
Though what you might see is OpenAI et al redefine the term “AGI” just so they can say they’ve hit that milestone, again purely for their own financial gain.
in the history of AI usually people overestimate how long a capability is reached. There are very few counterexamples to this (GPT5 capability level might be one of them though)
This reminds me how, a few years after the first fission power plant, Teller, Bhaba, and other nuclear physicists of the 1950s were convinced fusion power plants were about as far away as the physicists of today still predict they are.
I'm cautiously optimistic of each technology, but the point is it's easy to find bullshit predictions without actually gaining any insight into what will happen with a given technology.
There are areas where we seem to be much closer to AGI than most people realize. AGI for software development, in particular, seems incredibly close. For example, Claude Code has bewildering capabilities that feel like magic. Mix it with a team of other capable development-oriented AIs and you might be able to build AI software that builds better AI software, all by itself.
Claude Code is good, but it is far from being AGI. I use it every day, but it is still very much reliant on a human guiding it. I think it in particular shows when it comes to core abstractions - it really lacks the "mathematical taste" of a good designer, and it doesn't engage in long-term adversarial thinking about what might be wrong with a particular choice in the context of the application and future usage scenarios.
I think this type of thinking is a critical part of human creativity, and I can't see the current incarnation of agentic coding tools get there. They currently are way too reliant on a human carefully crafting the context and being careful of not putting in too many contradictory instructions or overloading the model with irrelevant details. An AGI has to be able to work productively on its own for days or weeks without going off on a tangent or suffering Xerox-like amnesia because it has compacted its context window 100 times.
The "G" in AGI stands for "general", so talking about "AGI for software development" makes no sense, and worse than that accepts the AI companies' goalpost-shifting at face value. We shouldn't do that.
But I feel like the point is that, in order to reach AGI, the most important area for AI to be good at first is software development. Because of the feedback loop that could allow.
This is a statistical model, it is as good as the data it averages. So shit from SO in, shit from SO out. Until they have the right dataset that doesn't contain cancerous code from people that can't write code, they can't even create a good agent, let alone AGI.
The real irony is from now on, because people use this magic, it will stay forever. What you can count on in my opinion is that this whole world changes, you don't need to write sw anymore because everything is AI. Hard to imagine, and too far in the future to be relevant for speculations.
The ability to self-learn is necessary, but not necessarily sufficient. We don’t have much of an understanding of the intelligence landscape beyond human-level intelligence, or even besides it. There may be other constraints and showstoppers, for example related to computability.
This is the key - right now each new model has had countless resources dedicated to training, then they are more or less set in stone until the next update.
These big models don't dynamically update as days pass by - they don't learn. A personal assistant service may be able to mimic learning by creating a database of your data or preferences, but your usage isn't baked back into the big underlying model permanently.
I don't agree with "in our lifetimes", but the difference between training and learning is the bright red line. Until there's a model which is able to continually update itself, it's not AGI.
My guess is that this will require both more powerful hardware and a few more software innovations. But it'll happen.
I feel like technological singularity has been pretty solidly ruled as junk science, like cold fusion, Malthusian collapse, or Lynn’s IQ regression. Technologists have made numerous predictions and hypothetical scenarios, non of which have come to fruition, nor does it seem likely at any time in the future.
I think we should be treating AGI like Cold Fusion, phrenology, or even alchemy. It is not science, but science fiction. It is not going to happen and no research into AGI will provide anything of value (except for the grifters pushing the pseudo-science).
Companies are collections of people, and these companies keep losing key developers to the others, I think this is why the clusters happen. OpenAI is now resorting to giving million dollar bonuses to every employee just to try to keep them long term.
If there was any indication of a hard takeoff being even slightly imminent, I really don't think key employees of the company where that was happening would be jumping ship. The amounts of money flying around are direct evidence of how desperate everybody involved is to be in the right place when (so they imagine) that takeoff happens.
> It is frequently suggested that once one of the AI companies reaches an AGI threshold, they will take off ahead of the rest.
Yes. And the fact they're instead clustering simply indicates that they're nowhere near AGI and are hitting diminishing returns, as they've been doing for a long time already. This should be obvious to everyone. I'm fairly sure that none of these companies has been able to use their models as a force multiplier in state-of-the-art AI research. At least not beyond a 1+ε factor. Fuck, they're just barely a force multiplier in mundane coding tasks.
Not only do I think there will not be a winner take all, I think it's very likely that the entire thing will be commoditized.
I think it's likely that we will eventually we hit a point of diminishing returns where the performance is good enough and marginal performance improvements aren't worth the high cost.
And over time, many models will reach "good enough" levels of performance including models that are open weight. And given even more time, these open weight models will be runnable on consumer level hardware. Eventually, they'll be runnable on super cheap consumer hardware (something more akin to a NPU than a $2000 RTX 5090). So your laptop in 2035 with specialize AI cores and 1TB of LPDDR10 ram is running GPT-7 level models without breaking a sweat. Maybe GPT-10 can solve some obscure math problem that your model can't but does it even matter? Would you pay for GPT-10 when running a GPT-7 level model does everything you need and is practically free?
The cloud providers will make money because there will still be a need for companies to host the models in a secure and reliable way. But a company whose main business strategy is developing the model? I'm not sure they will last without finding another way to add value.
I could certainly be wrong. Maybe I'm just not thinking creatively enough.
I just don't see how this doesn't get commoditized in the end unless hardware progress just halts. I get that a true AGI would have immeasurable value even if it's not valuable to end users. So the business model might change from charging $xxx/month for access to a chat bot to something else (maybe charging millions or billions of dollars to companies in the medical and technology sector for automated R&D). But even if one company gets AGI and then unleashes it on creating ever more advanced models, I don't see that being an advantage for the long term because the AGI will still be bottlenecked by physical hardware (the speed of a single GPU, the total number of GPUs the AGI's owner can acquire, even the number of data centers they can build). That will give the competition time to catch up and build their own AGI. So I don't see the end of AGI race being the point where the winner gets all the spoils.
And then eventually there will be AGI capable open weight models that are runnable on cheap hardware.
The only way the current state can continue is if there is always strong demand for ever increasingly intelligent models forever and always with no regard for their cost (both monetarily and environmentally). Maybe there is. Like maybe you can't build and maintain a dyson sphere (or whatever sufficiently advanced technology) with just an Einstein equivalent AGI. Maybe you need an AGI that is 1000x more intelligent than Einstein and so there is always a buyer.
Investors, especially venture investors, are chasing a small chance of a huge win. If there's a 10% or even a 1% chance of a company dominating the economy, that's enough to support a huge valuation even if the median outcome is very bad.
Zuckerberg has spent over fifty billion dollars on the idea that people will want to play a Miiverse game where they can attend meetings in VR and buy virtual real estate. It's like the Spanish emptying Potosi to buy endless mercenaries.
The correlation between "speculator is a billionaire" and "speculator is good at predicting things" is much higher than the correlation between "guy has a HN account" and "guy knows more about the future of the AI industry than the people directly investing in it".
And he doesn't just think he has an edge, he thinks he has superior rationality.
One can apply a brief sanity check via reductio ad absurdum: it is less logical to assume that poor individuals possess greater intelligence than wealthy individuals.
Increased levels of stress, reduced consumption of healthcare, fewer education opportunities, higher likelihood of being subjected to trauma, and so forth paint a picture of correlation between wealth and cognitive functionality.
Yeah, that's not a good argument. That might be true for the very poor, sure, but not for the majority of the lower-to-middle of the middle class. There's fundamentally no difference between your average blue collar worker and a billionaire, except the billionaire almost certainly had rich parents and got lucky.
People really don't like the "they're not, they just got lucky" statement and will do a lot of things to rationalize it away lol.
The comparison was clearly between the rich and the poor. We can take the 99.99th wealth percentile, where billionaires reside, and contrast that to a narrow range on the opposite side of the spectrum. But, in my opinion, the argument would still hold even if it were the top 10% vs bottom 10% (or equivalent by normalised population).
Anyone who believes this hasn't spent enough time around rich people. Rich people are almost always rich because they come from other rich people. They're exactly as smart as poor people, except the rich folk have a much, much cushier landing if they fail so they can take on more risk more often. It's much easier to succeed and look smart if you can just reload your save and try over and over.
I'm still stuck at the bit where just throwing more and more data to make a very complex encyclopedia with an interesting search interface that tricks us into believing it's human-like gets us to AGI when we have no examples and thus no evidence or understanding of where the GI part comes from.
It's all just hyperbole to attract investment and shareholder value and the people peddling the idea of AGI as a tangible possibility are charlatans whose goals are not aligned with whatever people are convincing themselves are the goals.
Thr fact that so many engineers have fallen for it so completely is stunning to me and speaks volumes on the underlying health of our industry.
I know there's an official AGI definition, but it seem to me that there's too much focus on the model as the thing where AGI needs to happen. But that is just focusing on knowledge in the brain. No human knows everything. We as humans rely on a ways to discover new knowledge, investigation, writing knowledge down so it can be shared, etc.
Current models, when they apply reasoning, have feedback loops using tools to trial and error, and have a short term memory (context) or multiple short term memories if you use agents, and a long term memory (markdown, rag), they can solve problems that aren't hardcoded in their brain/model. And they can store these solutions in their long term memory for later use. Or for sharing with other LLM based systems.
AGI needs to come from a system that combines LLMs + tools + memory. And i've had situations where it felt like i was working with an AGI. The LLMs seem advanced enough as the kernel for an AGI system.
The real challenge is how are you going to give these AGIs a mission/goal that they can do rather independently and don't need constant hand-holding. How does it know that it's doing the right thing. The focus currently is on writing better specifications, but humans aren't very good at creating specs for things that are uncertain. We also learn from trial and error and this also influences specs.
AGI in 5/10 years is similar to "we won't have steering wheels in cars" or "we'll be asleep driving" in 5/10 years. Remember that? What happened to that? It looked so promising.
I mean, in certain US cities you can take a waymo right now. It seems that adage where we overestimate change in the short term and underestimate change in the long term fits right in here.
That's not us though. That's a third party worth trillions of dollars that manages a tiny fleet of robot cars with a huge back-end staff and infrastructure, and only in a few cities covering only about 2-3% of us (in this one country.) We don't have steering wheel-less cars and we can't/shouldn't sleep on our commute to and from work.
I don't think anyone was ever arguing "not only are we going to develop self driving technology but we're going to build out the factories to mass produce self driving cars, and convince all the regulatory bodies to permit these cars, and phase out all the non-self driving vehicles already on the road, and do this all at a price point equal or less than current vehicles" in 5 to 10 years. "We will have self driving cars in 10 years" was always said in the same way "We will go to the moon in 10 years" was said in the early 60s.
The open (about the bet) is actually pretty reasonable, but some of the predictions listed include: passenger vehicles on American roads will drop from 247 million in 2020 to 44 million in 2030. People really did believe that self-driving was "basically solved" and "about to be ubiquitous." The predictions were specific and falsifiable and in retrospect absurd.
I meant serious predictions. A surprisingly large percentage of people claim the Earth is flat, of course there's going to be baseless claims that the very nature of transportation is about to completely change overnight. But the people actually familiar with the subject were making dramatically more conservative and I would say reasonable predictions.
What Waymo and others are doing is impressive, but it doesn't seem like it will globally generalize. Does it seem like that system can be deployed in chaotic Mumbai, old European cities, or unpaved roads? It requires clear, well maintained road infrastructure and seems closer to "riding on rails" than "drive yourself anywhere".
"Achieving that goal necessitates a production system supporting it" is very different from "If the control system is a full team in a remote location, this vehicle is not autonomous at all" which was what GP said.
I read GP as saying Waymo does indeed have self driving cars, but that doesn't count because such cars are not available for the average person to purchase and operate.
Waymo cars aren't being driven by people at a remote location, they legitimately are autonomous.
Of course. My point being "AI is going to take dev jobs" is very much like saying "Self driving will take taxi driver jobs". Never happened and likely won't happen or on a very, very long time scale.
Looks like a lot of players getting closer and closer to an asymptotic limit. Initially small changes lead to big improvements causing a firm to race ahead, as they go forward performance gains from innovation become both more marginal and harder to find, nonetheless keep. I would expect them all to eventually reach the same point where they are squeezing the most possible out of an AI under the current paradigm, barring a paradigm shifting discovery before that asymptote is reached.
I think you're reading way too much into OpenAI bungling its 15-month product lead, but also the whole "1 AGI company will take off" prediction is bad anyway, because it assumes governments would just let that happen. Which they wouldn't, unless the company is really really sneaky or superintelligence happens in the blink of an eye.
Governments react at a glacial pace to new technological developments. They wouldn't so much as 'let it happen' as that it had happened and they simply never noticed it until it was too late. If you are betting on the government having your back in this then I think you may end up disappointed.
I think if any government really thought that someone was developing a rival within their borders they would send in the guys with guns and handle it forthwith.
While generally true, a lot of governments have not only definitely noticed AI, they're getting flack for using it as an assistant and are actively promoting it as a strategic interest.
That said, any given government may be thinking like Zuckerberg[0] or senator Blumenthal[1], so perhaps these governments are just flag-waving what they think is an investment opportunity without any real understanding…
[0] general lack of vision, thinking of "superintelligence" in terms of what can be done with/by the Star Trek TNG era computer, rather than other fictional references such as a Culture Mind or whatever: https://archive.ph/ZZF3y
[1] "I alluded, in my opening remarks, to the jobs issue, the economic effects on employment. I think you have said, in fact, and I'm going to quote, ``Development of superhuman machine intelligence is probably the greatest threat to the continued existence of humanity,'' end quote. You may have had in mind the effect on jobs, which is really my biggest nightmare, in the long term." - https://www.govinfo.gov/content/pkg/CHRG-118shrg52706/html/C...
this is generally true in a regulation sense, but not in emergency. The executive can either covertly or overtly take control of a company if AGI seems to powerful to be in private hands.
They would just declare it necessary for military purpose and demand the tech be licensed to a second company so that they have redundant sources, same as they did with AT&T's transistor.
That was something that was tied to a bunch of very specific physical objects. There is a fair chance that once you get to the point where this thing really comes into being especially if it takes longer than a couple of hours for it to be shut down or contained that the genie will never ever be put back into the bottle again.
Note that 'bits' are a lot easier to move from one place to another than hardware. If invented at 9 am it could be on the other side of the globe before you're back from your coffee break at 9:15. This is not at all like almost all other trade secrets and industrial gear, it's software. Leaks are pretty much inevitable and once it is shown that it can be done it will be done in other places as well.
Have you not been watching Trump humiliate all the other billionaires in the US? The right sort of government (or maybe wrong sort, I'm undecided which is worse) can very easily bring corporations to heel.
China did the same thing when their tech-bros got too big for their boots.
Humiliate? They're jostling for position and pushing each other out of the way to see who can buy the most government influenced while giving the least. The only thing that is being humiliated here is the United States reputation the world over. Those billionaires are making out like bandits, finally they really get to call the shots. That they give the doddering old fool some trinkets in return for untold access to power is the thing that should worry you, not that there - occasionally - is a billionaire with buyers remorse. There are enough of them to replace the ones that no longer want to play the game.
I think OpenAI has committed hard onto the 'product company' path, and will have a tough time going back to interesting science experiments that may and may not work, but are necessary for progress.
* or governments fail to look far enough ahead, due to a bunch of small-minded short-sighted greedy petty fools.
Seriously, our government just announced it's slashing half a billion dollars in vaccine research because "vaccines are deadly and ineffective", and it fired a chief statistician because the president didn't like the numbers he calculated, and it ordered the destruction of two expensive satellites because they can observe politically inconvenient climate change. THOSE are the people you are trusting to keep an eye on the pace of development inside of private, secretive AGI companies?
While one in particular is speedracing into irrelevance, it isn't particularly representative of the rest of the developed world (and hasn't in a very long time, TBH).
"irrelevance" yeah sure, I'm sure Europe's AI industry is going to kick into high gear any day now. Mistral 2026 is going to be lit. Maybe Sir Demis will defect Deepmind to the UK.
That's not what I was going for (I was more hinting at isolationist, anti-science, economically self-harming and freedoms-eroding policies), but if you take solace in believing this is all worth it because of "AI" (and in denial about the fact that none of those companies are turning a profit from it, and that there is no identified use-case to turn the tables down the line), I'm sincerely happy for you and glad it helps you cope with all the insanity!
Do you mean from ChatGPT launch or o1 launch? Curious to get your take on how they bungled the lead and what they could have done differently to preserve it. Not having thought about it too much, it seems that with the combo of 1) massive hype required for fundraising, and 2) the fact that their product can be basically reverse engineered by training a model on its curated output, it would have been near impossible to maintain a large lead.
My 2 cents: ChatGPT -> Gemini 1 was their 15-month lead. The moment ChatGPT threatened Google's future Search revenue (which never actually took a hit afaik), Google reacted by merging Deepmind and Google Brain and kicked off the Gemini program (that's why they named it Gemini).
Basically, OpenAI poked a sleeping bear, then lost all their lead, and are now at risk of being mauled by the bear. My money would be on the bear, except I think the Pentagon is an even bigger sleeping bear, so that's where I would bet money (literally) if I could.
It's quite possible that the models from different companies are clustering together now because we're at a plateau point in model development, and won't see much in terms in further advances until we make the next significant breakthrough.
I don't think this has anything to do with AGI. We aren't at AGI yet. We may be close or we may be a very long way away from AGI. Either way, current models are at a plateau and all the big players have more or less caught up with each other.
As is, AI is quite intelligent, in that it can process large quantities of diverse unstructured information and build meaningful insights. And that intelligence applies across an incredibly broad set of problems and contexts. Enough that I have a hard time not calling it general. Sure, it has major flaws that are obvious to us and it's much worse at many things we care about. But that's doesn't make it not intelligent or general. If we want to set human intelligence as the baseline, we already have a word for that: superintelligence.
Is Casio calculator intelligent? Because it can also be turned on, assigned an input, produce output, and turn off. Just like any existing LLM program. What is the big difference between them in regard of "intelligence", if the only criteria is a difficulty with which same task may be performed by a human? Maybe producing computationally intensive outputs is not a sole sign of intelligence?
while the model companies all compete on the same benchmarks it seems likely their models will all converge towards similar outcomes unless something really unexpected happens in model space around those limit points…
correlation between text can implement any algorithm, it is just the architecture which it's built on. It's like saying vacuum tube computers can't reason bc it's just air not reasoning. What the architecture is doesn't matter. It's capable of expressing reasoning as it is capable of expression any program. In fact you can easily think of a turing machine and also any markov chain as a correlation function between two states which have joint distribution exactly at places where the second state is the next state of the first state.
For those who happen to have a subscription to The Economist, there is a very interesting Money Talks podcast where they interview Anthropic's boss Dario Amodei[1].
There were two interesting takeaways about AGI:
1. Dario makes the remark that the term AGI/ASI is very misleading and dangerous. These terms are ill defined and it's more useful to understand that the capabilities are simply growing exponentially at the moment. If you extrapolate that, he thinks it may just "eat the majority of the economy". I don't know if this is self-serving hype, and it's not clear where we will end up with all this, but it will be disruptive, no matter what.
2. The Economist moderators however note towards the end that this industry may well tend toward commoditization. At the moment these companies produce models that people want but others can't make. But as the chip making starts to hits its limits and the information space becomes completely harvested, capability-growth might taper off, and others will catch up. The quasi-monopoly profit potentials melting away.
Putting that together, I think that although the cognitive capabilities will most likely continue to accelerate, albeit not necessarily along the lines of AGI, the economics of all this will probably not lead to a winner takes all.
There's already so many comparable models, and even local models are starting to approach the performance of the bigger server models.
I also feel like, it's stopped being exponential already. I mean last few releases we've only seen marginal improvements. Even this release feels marginal, I'd say it feels more like a linear improvement.
That said, we could see a winner take all due to the high cost of copying. I do think we're already approaching something where it's mostly price and who released their models last. But the cost to train is huge, and at some point it won't make sense and maybe we'll be left with 2 big players.
1. FWIW, I watched clips from several of Dario’s interviews. His expressions and body language convey sincere concerns.
2. Commoditization can be averted with access to proprietary data. This is why all of ChatGPT, Claude, and Gemini push for agents and permissions to access your private data sources now. They will not need to train on your data directly. Just adapting the models to work better with real-world, proprietary data will yield a powerful advantage over time.
Also, the current training paradigm utilizes RL much more extensively than in previous years and can help models to specialize in chosen domains.
It doesn't take a researcher to realise that we have hit a wall and hit it more than a year ago now. The fact all these models are clustering around the same performance proves it.
this is what i don't get. How can GPT-5 ace obscure AIME problems while simultaneously falling into the trap of the most common fallacy about airfoils (despite there being copious training data calling it out as a fallacy)? And I believe you that in some context it failed to understand this simple rearrangement of terms; there's sometimes basic stuff I ask it that it fails at too.
It still can't actually reason, LLMs are still fundamentally madlib generators that produce output that statistically looks like reasoning.
And if it is trained on both sides of the airfoil fallacy it doesn't "know" that it is a fallacy or not, it'll just regurgitate one or the other side of the argument based on if the output better fits your prompt in its training set.
Because reading the different ideas about airfoils and actually deciding which is the more accurate requires a level of reasoning about the situation that isn't really present at training or inference time. A raw LLM will tend to just go with the popular option, an RLHF one might be biased towards the more authoritative-sounding one. (I think a lot of people have a contrarian bias here: I frequently hear people reject an idea entirely because they've seen it be 'debunked', even if it's not actually as wrong as they assume)
Genuine question, are these companies just including those "obscure" problems in their training data, and overfitting to do well at answering them to pump up their benchmark scores?
Context matters a lot here - it may fail on this problem within a particular context (what the original commenter was working on), but then be able to solve it when presented with the question in isolation. The way your phrase the question may hint the model towards the answer as well.
What I'm seeing is that as we get closer to supposed AGI, the models themsleves are getting less and less general. They're getting in fact more specific and clustered around high value use cases. It's kind of hard to see in this context what AGI is meant to mean.
I think the expectation is that it will be very close until one team reaches beyond the threshold. Then even if that team is only one month ahead, they will always be one month ahead in terms of time to catch up, but in terms of performance at a particular time their lead will continue to extend. So users will use the winner's tools, or use tools that are inferior by many orders of magnitude.
This assumes an infinite potential for improvement though. It's also possible that the winner maxes out after threshold day plus one week, and then everyone hits the same limit within a relatively short time.
I think there are two competing factors. On one end, to get the same kind of "increase" in intelligence each generation requires an expontentially higher amount of compute, so while GPT-3 to GPT-4 was a sort of "pure" upgrade by just making it 10x bigger, gradually you lose the ability to just get 10x GPUs for a single model. The hill keeps getting steeper so progress is slower without exponential increases (which is what is happening).
However, I do believe that once the genuine AGI threshold is reached it may cause a change in that rate. My justification is that while current models have gone from a slightly good copywriter in GPT-4 to very good copywriter in GPT-5, they've gone from sub-exceptional in ML research to sub-exceptional in ML research.
The frontier in AI is driven by the top 0.1% of AI researchers. Since improvement in these models is driven partially by the very peaks of intelligence, it won't be until models reach that level where we start to see a new paradigm. Until then it's just scale and throwing whatever works at the GPU and seeing what comes out smarter.
It seems that the new tricks that people discover to slightly improve the model, be it a new reinforcement learning technique or whatever, get leaked/shared quickly to other companies and there really isn't a big moat. I would have thought that whoever is rich enough to afford tons of compute first would start pulling away from the rest but so far that doesn't seem to be the case --- even smaller players without as much compute are staying in the race.
I think this is simply due to the fact that to train an AGI-level AI currently requires almost grid scale amounts of compute. So the current limitation is purely physical hardware. No matter how intelligent GPT-5 is, it can't conjure extra compute out of thin air.
I think you'll see the prophesized exponentiation once AI can start training itself at reasonable scale. Right now its not possible.
The clustering you see is because they're all optimized for the same benchmarks. In the real world OpenAI is already ahead of the rest, and Grok doesn't even belong in the same group (not that it's not a remarkable achievement to start from scratch and have a working production model in 1-2 years, and integrate it with twitter in a way that works). And Google is Google - kinda hard for them not to be in the top, for now.
Well, it is perhaps frequently suggested by those Ai firms raising capital that once one of the Ai companies reaches an AGI threshhold ... It as rallying call. "Place your bets, gentlemen!"
>It is frequently suggested that once one of the AI companies reaches an AGI threshold, they will take off ahead of the rest. It's interesting to note that at least so far, the trend has been the opposite
That seems hardy surprising considering the condition to receive the benefit has not been met.
The person who lights a campfire first will become warmer than the rest, but while they are trying to light the fire the others are gathering firewood. So while nobody has a fire, those lagging are getting closer to having a fire.
I feel like the benchmark suites need to include algorithmic efficiency. I.e can this thing solve your complex math or coding problem in 5000 gpus instead of 10000? 500? Maybe just 1 Mac mini?
The idea of singularity--that AI will improve itself--is that it assumes intelligence is an important part of improving AI.
The AIs improve by gradient descent, still the same as ever. It's all basic math and a little calculus, and then making tiny tweaks to improve the model over and over and over.
There's not a lot of room for intelligence to improve upon this. Nobody sits down and thinks really hard, and the result of their intelligent thinking is a better model; no, the models improve because a computer continues doing basic loops over and over and over trillions of times.
That's my impression anyway. Would love to hear contrary views. In what ways can an AI actually improve itself?
I studied machine learning in 2012, gradient descent wasn't new back then either but it was 5 years before the "attention is all you need" paper. Progress might look continuous overall but if you zoom enough it might be a bit more discrete with breakthrough that must happen to jump the discrete parts, the question to me now is "How many papers like attention is all you need before a singularity?" I don't have that answer but let's not forget, until they released chat gpt, openAI was considered a joke by many people in the field who asserted their approach was a dead end.
Honestly for all the super smart people in the LessWrong singularity crowd, I feel the mental model they apply to the 'singularity' is incredibly dogmatic and crude, with the basic assumption that once a certain threshold is reached by scaling training and compute, we get human or superhuman level intelligence.
Even if we run with the assumption that LLMs can become human-level AI researchers, and are able to devise and run experiments to improve themselves, even then the runaway singularity assumption might not hold. Let's say Company A has this LLM, while company B does not.
- The automated AI researcher, like its human peers, still needs to test the ideas and run experiments, it might happen that testing (meaning compute) is the bottleneck, not the ideas, so Company A has no real advantage.
- It might also happen that AI training has some fundamental compute limit coming from information theory, analogous to the Shannon limit, and once again, more efficient compute can only approach this, not overcome it
I know right, if I didn't know any better one might think they are all customized versions of the same base model.
To be honest that is what you would want if you were digitally transforming the planet with AI.
You would want to start with a core so that all models share similar values in order they don't bicker etc, for negotiations, trade deals, logistics.
Would also save a lot of power so you don't have to train the models again and again, which would be quite laborious and expensive.
Rather each lab would take the current best and perform some tweak or add some magic sauce then feed it back into the master batch assuming it passed muster.
Share the work, globally for a shared global future.
People always say that when new technology comes along. Usually the best tech doesn't win. In fact, if you think you can build a company just by having a better offer it's better not to bother with it. There is to much else involved.
Scaling laws enabled an investment in capital and GPU R&D to deliver 10,000x faster training.
That took the wold from autocomplete to Claude and GPT.
Another 10,000x would do it again, but who has that kind of money or R&D breakthrough?
The way scaling laws work, 5,000x and 10,000x give a pretty similar result. So why is it surprising that competitors land in the same range? It seems hard enough to beat your competitor by 2x let alone 10,000x
The idea is that with AGI it will then be able to self improve orders of magnitude faster than it would if relying on humans for making the advances. It tracks that the improvements are all relatively similar at this point since they're all human-reliant.
My personal belief is that we are moving past the hype and kind of starting to realize the true shape of what (LLM) AI can offer us, which is a darned lot, but still, it only works well when fed the right input and handled right - which is still a learning process ongoing on both sides - AI companies need to learn to train these things into user interaction loops that match people's workflows, and people need to learn how to use these tools better.
You have seemed to pinpoint where I believe a lot of opportunity lies during this era (however long it lasts.) Custom integration of these models into specific workflows of existing companies can make a significant difference in what’s possible for said companies, the smaller more local ones especially. If people can leverage even a small percentage of what these models are capable of, that may be all they need for their use case. In that case, they wouldn’t even need to learn to use these tools, but (much like electricity) they will just plug in or flip on the switch and be in business (no pun intended.)
Nothing we have is anywhere near AGI and as models age others can copy them.
I personally think we are closing the end of improvement for LLMs with current methods. We have consumed all of the readily available data already, so there is no more good quality training material left. We either need new novel approaches or hope that if enough compute is thrown at training actual intelligence will spontaneously emerge.
>It is frequently suggested that once one of the AI companies reaches an AGI threshold, they will take off ahead of the rest.
Both the AGI threshold with LLM architecture, and the idea of self-advancing AI, is pie in the sky, at least for now. These are myths of the rationalist cult.
We'd more likely see reduced returns and smaller jumps between version updates, plus regression from all the LLM produced slop that will be part of the future data.
> It is frequently suggested that once one of the AI companies reaches an AGI threshold, they will take off ahead of the rest.
That's only one part of it. Some forecasters put probabilities on each of the four quadrants in the takeoff speed (fast or slow) vs. power distribution (unipolar or multipolar) table.
They have to actually reach that threshold, right now their nudging forward catching up to one another, and based on the jumps we've seen the only one actually making huge jumps sadly is Grok, which i'm pretty sure is because they have 0 safety concerns and just run full tilt lol
Part of the fun is that predictions get tested on short enough timescales to "experience" in a satisfying way.
Idk where that puts me, in my guess at "hard takeoff." I was reserved/skeptical about hard takeoff all along.
Even if LLMs had improved at a faster rate... I still think bottlenecks are inevitable.
That said... I do expect progress to happen in spurts anyway. It makes sense that companies of similar competence and resources get to a similar place.
The winner take all thing is a little forced. "Race to singularity" is the fun, rhetorical version of the investment case. The implied boring case is facebook, adwords, aws, apple, msft... IE the modern tech sector tends to create singular big winners... and therefore our pre-revenue market cap should be $1trn.
The race has always been very close IMO. What Google had internally before ChatGPT first came out was mind blowing. ChatGPT was a let down comparatively (to me personally anyway).
Since then they've been about neck and neck with some models making different tradeoffs.
Nobody needs to reach AGI to take off. They just need to bankrupt their competitors since they're all spending so much money.
I don't think models are fundamentally getting better. What is happening is that we are increasing the training set, so when users use it, they are essentially testing on the training set and find that it fits their data and expectations really well. However, the moat is primarily the training data, and that is very hard to protect as the same data can be synthesized with these models. There is more innovation surrounding serving strategies and infrastructure than in the fundamental model architectures.
Because AGI is a buzzword to milk more investors' money, it will never happen, and we will only see slight incremental updates or enhancements yet linear after some timr just like literally any tech bubble since dot com to smartphones to blockchain to others.
It's vaguely defined and the goalposts keep shifting. It's not a thing to be achieved, it's an abstract concept. We're already expired the Turing test as a valuable metric because people are dumb and have been fooled by machines for a while now, but it's not been world-changingly better either.
I've yet to hear an agreed upon criteria to declare whether or not AGI has been discovered. Until it's at least understood what AGI is and how to recognize it then how could it possibly be achieved?
I think OpenAI's definition ("outperforms humans at most economically valuable work") is a reasonably concrete one, even if it's arguable that it's not 'the one true form of AGI'. That is at least the "it will completely change almost everyone's lives" point.
(It's also one that they are pretty far from. Even if LLMs displace knowledge/office work, there's still all the actual physical things that humans do which, while improving rapidly with VLMs and similar stuff, is still a large improvement in the AI and some breakthroughs in electronics and mechanical engineering away)
It's overly strong in some ways (and weak in a few), yes. Which is why I said it's not a "one true definition", but a concrete one which, if reached, would well and truly mean that it's changed the world.
I think a good threshold, and definition, is when you get to the point where all the different, reasonable, criteria are met, and when saying "that's not AGI" becomes the unreasonable perspective.
> how could it possibly be achieved?
This doesn't matter, and doesn't follow the history of innovation, in the slightest. New things don't come from "this is how we will achieve this", otherwise they would be known things. Progress comes from "we think this is the right way to go, let's try to prove it is", try, then iterate with the result. That's the whole foundation of engineering and science.
This is scary because there have already been AI engineers saying and thinking LLMs are sentient, so what’s unreasonable could be a mass false-belief, fueled by hype. And if you ask a non-expert, they often think AI is vastly better than it really is, able to pull data out of thin air.
How is that scary, when we don’t have a good definition of sentience?
Do you think sentience is a binary concept or a spectrum? Is a gorilla more sentient than a dog? Are all humans sentient, or does it get somewhat fuzzy as you go down in IQ, eventually reaching brain death?
Is a multimodal model, hooked to a webcam and microphone, in a loop, more or less sentient than a gorilla?
There may not be a universally agreed upon threshold for the minimum required for AGI, but there's certainly a point where if you find yourself beyond it then AGI definitely has been developed.
There are some thresholds where I think it would be obvious that a machine has.
Put the AI in a robot body and if you can interact with it the same way you would interact with a person (ie you can teach it to make your bed, to pull weeds in the garden, to drive your car, etc…) and it can take what you teach it and continually build on that knowledge, then the AI is likely an instance of AGI.
It's the classic S-curve. A few years ago when we saw ChatGPT come out, we got started on the ramping up part of the curve but now we're on the slowing down part. That's just how technology goes in general.
How marginally better was Google than Yahoo when debuted? If one can develop AGI first within X timeline ahead of competitors, that alone could develop a moat for a mass market consumer product even if others get to parity .
Google was not marginally better Yahoo, their implementation of Markov chains in the PageRank algorithm was significantly better than Yahoo or any other contemporary search engine.
It's not obvious if a similar breakthrough could occur in AI
If we're focusing on fast take-off scenario, this isn't a good trend to focus on.
SGI would be self-improving to some function with a shape close to linear based on the amount of time & resources. That's almost exclusively dependent on the software design, as currently transformers have shown to hit a wall at logarithmic progression x resources.
In other words, no, it has little to do with the commercial race.
> as time goes on and the models get better, the performance of the different company's gets clustered closer together
This could be partly due to normative isomorphism[1] according to the institutional theory. There is also a lot of movement of the same folks between these companies.
Is AGI even possible? I am skeptical of that. I think they can get really good at many tasks and when used by a human expert in a field you can save lots of time and supervise and change things here and there, like sculpting.
But I doubt we will ever see a fully autonomous, reliable AGI system.
Ultimately, what drives human creativity? I'd say it's at least partially rooted in emotion and desire. Desire to live more comfortably; fear of failure or death; desire for power/influence, etc... AI is void of these things, and thus I believe we will never truly reach AGI.
Breakthroughs usually require a step-function change in data or compute. All the firms have proportional amounts. Next big jump in data is probably private data (either via de-siloing or robotics or both). Next big jump in compute is probably either analog computing or quantum. Until then... here we are.
Because they are hitting Compute Efficient Frontier. Models can't be much bigger, there is no more original data on the internet, so all models will eventually cluster to similar CEF as was described in this video 10 months ago
Working in the theory, I can say this is incredibly unlikely. At scale, once appropriately trained, all architectures begin to converge in performance.
It's not architectures that matter anymore, it's unlocking new objectives and modalities that open another axis to scale on.
Do we really have the data on this? I mean, it does happen on a smaller scale, but where's the 300B version of RWKV? Where's hybrid symbolic/LLM? Where are other experiments? I only see larger companies doing relatively small tweaks to the standard transformers, where the context size still explodes the memory use - they're not even addressing that part.
True, we can't say for certain. But there is a lot of theoretical evidence too, as the leading theoretical models for neural scaling laws suggest finer properties of the architecture class play a very limited role in the exponent.
We know that transformers have the smallest constant in the neural scaling laws, so it seems irresponsible to scale another architecture class to extreme parameter sizes without a very good reason.
People often talk in terms of performance curves or "neural scaling laws". Every model architecture class exhibits a very similar scaling exponent because the data and the training procedures are playing the dominant role (every theoretical model which replicates the scaling laws exhibit this property). There are some discrepancies across model architecture classes, but there are hard limits on this.
Theoretical models for neural scaling laws are still preliminary of course, but all of this seems to be supported by experiments at smaller scales.
I think part of this is due to the AI craze no longer being in the wildest west possible. Investors, or at least heads of companies believe in this as a viable economic engine so they are properly investing in what's there. Or at least, the hype hasn't slapped them in the face just yet.
Even at the beginning of the year people were still going crazy over new model releases. Now the various model update pages are starting to average times in the months since their last update rather than days/weeks. This is across the board. Not limited to a single model.
It's all based on the theory of singularity. Where the AI can start trainig & relearning itself. But it looks like that's not possible with the current techniques.
The idea is that AGI will be able to self improve at an exponential rate. This is where the idea of take off comes from. That self improvement part isn’t happening today.
What is the AGI threshold? That the model can manage its own self improvement better than humans can? Then the roles will be reversed -- LLM prompting the meat machines to pave its way.
Diversity where new model release takes the crown until next release is healthy. Shame only US companies seem to be doing it, hopefully this will change as the rest is not far off.
Plot twist - once GPT reached AGI, this is exactly the strategy chosen for self-preservation.
Appear to not lead by too much, only enough to make everyone think we're in a close race, play dumb when needed.
Meanwhile, keep all relevant preparations in secret...
In my opinion, it'll mirror the human world, there is place for multiple different intelligent models. Each with their own slightly different strengths/personalities.
I mean there are plenty of humans that can do the same task but at the upper tier, multiple smart humans working together are needed to solve problems as they bring something different to the table.
I don't see why this won't be the case with super intelligence at the cutting edge. A little bit of randomness and slightly different point of view makes a difference. The exact same two models doesn't help as one would already have thought of what the other was thinking already
You can't reach the moon by climbing the tallest tree.
This misunderstanding is nothing more than the classic "logistic curves look like exponential curves at the beginning". All (Transformee-based, feedforward) AI development efforts are plateauing rapidly.
AI engineers know this plateau is there, but of course every AI business has a vested interest in overpromising in order to access more funding from naive investors.
I’ve been saying for a while if AGI is possible it’s going to take another innovation and the transformer / LLM paradigm will plateau, and innovations are hard to time. I used to get downvoted for saying that years ago and now more people are realizing it. LLMs are awesome but there is a limit, most of the interesting things in the next years will be bolting more functionality and agent stuff, introspection like Anthropic is working on and smaller, less compute hungry specialized models. There’s still a lot to explore in this paradigm, but we’re getting diminishing returns on newer models, especially when you factor in cost
I bet that it will only happen when the ability to process and concrete new information into its training model without retraining the entire model is standard, AND when multiple AIs with slightly different datasets are set to work together to create a consensus response approach.
It's probably never going to work with a single process without consuming the resources of the entire planet to run that process on.
> once one of the AI companies reaches an AGI threshold
Why is this even an axiom, that this has to happen and it's just a matter of time?
I don't see any credible argument for the path LLM -> AGI, in fact given the slowdown in enhancement rate over the past 3 years of LLMs, despite the unprecedented firehose of trillions of dollars being sunk into them, I think it points to the contrary!
There is zero reason or evidence to believe AGI is close. In fact it is a good litmus test for someone's human intelligence whether they believe it.
What do you think AGI is?
How do we go from sentence composing chat bots to General Intelligence?
Is it even logical to talk about such a thing as abstract general intelligence when every form of intelligence we see in the real world is applied to specific goals as evolved behavioral technology refined through evolution?
When LLMs start undergoing spontaneous evolution then maybe it is nearer. But now they can't. Also there is so much more to intelligence than language. In fact many animals are shockingly intelligent but they can't regurgitate web scrapings.
LLMs are basically all the same at this point. The margins are razor thin.
The real take-off / winner-take-all potential is in retrieval and knowing how to provide the best possible data to the LLM. That strategy will work regardless of the model.
Mental-modeling is one of the huge gaps in AI performance right now in my opinion. I could describe in detail a very strange object or situation to a human being with a pen and paper and then ask them questions about it and expect answers that meet all my described constraints. AI just isn't good for that yet.
>It's interesting to note that at least so far, the trend has been the opposite: as time goes on and the models get better, the performance of the different company's gets clustered closer together
It's natural if you extrapolate from training loss curves; a training process with continually diminishing returns to more training/data is generally not something that suddenly starts producing exponentially bigger improvements.
This confirms my suspicion that we are not at the exponential part of the curve, but the flattening one. It's easier to stay close to your competitors when everyone is at the flat curve of the innovation.
The improvements they make are marginal. How long until the next AI breakthrough? Who can tell? Because last time it took decenia.
I think the breakthroughs now will be the application of LLMs to the rest of the world. Discovering use cases where LLMs really shine and applying them while learning and sharing the use cases where they do not.
Nobody seems to be on the path to AGI as long as the model of today is as good as the model of tomorrow. And as long as there are "releases". You don't release a new human every few months...LLMs are currently frozen sequence predictors whose static weights stop learning after training.
They lack writable long-term memory beyond a context window. They operate without any grounded perception-action loop to test hypotheses. And they possess no executive layer for goal directed planning or self reflection...
Achieving AGI demands continuous online learning with consolidation.
They use each other for synthesizing data sets. The only moat was the initial access to human generated data in hard to reach places. Now they use each other to reach parity for the most part.
I think user experience and pricing models are the best here. Right now everyone’s just passing down costs as they come, no real loss leaders except a free tier. I looked at reviews of some of various wrappers on app stores, people say “I hate that I have to pay for each generation and not know what I’m doing to get”, market would like a service priced very differently. Is it economical? Many will fail, one will succeed. People will copy the model of that one.
It's still not necessarily wrong, just unlikely. Once these developers start using the model to update itself, beyond an unknown threshold of capability, one model could start to skyrocket in performance above the rest. We're not in that phase yet, but judging from what the devs at the end were saying, we're getting uncomfortably (and irresponsibly) close.
Ok this[0] sounds very, uh bold to me? Surely this is going to break a ton of workflows etc seemingly with nearly no notice? I'm assuming 'launches' equates with 'fully rolls out' or something but it's not that clear to me.
When GPT-5 launches, several older models will be retired, including:
- GPT-4o
- GPT-4.1
- GPT-4.5
- GPT-4.1-mini
- o4-mini
- o4-mini-high
- o3
- o3-pro
If you open a conversation that used one of these models, ChatGPT will automatically switch it to the closest GPT-5 equivalent. Chats with 4o, 4.1, 4.5, 4.1-mini, o4-mini, or o4-mini-high will open in GPT-5, chats with o3 will open in GPT-5-Thinking, and chats with o3-Pro will open in GPT-5-Pro (available only on Pro and Team).
> For Free and Plus users, these changes take effect immediately. Pro, Team, and Enterprise users will also see the changes at launch but will have access to older models through legacy model settings.
So only for free/plus users (for now). I do wonder how long they will take to deprecate these models via API though...
> For Free and Plus users, these changes take effect immediately. Pro, Team, and Enterprise users will also see the changes at launch but will have access to older models through legacy model settings.
Web search often tanks the quality of MY output these days too. Context clogging seems a reasonable description of what I experience when I try to use the normal web.
THIS. I do my best work after a long vigorous walk and contemplation, while listening to Bach sipping espresso. (Not exaggerating much.) If I go on HN or slack or ClickUp or work email, context is slammed and I cannot do /clear so fast. Even looking up something quick on the web or an LLM causes a dirtying.
I feel the same. LLMs using web search ironically seem to have less thoughtful output. Part of the reason for using LLMs is to explore somewhat novel ideas. I think with web search it aligns too strongly to the results rather than the overall request making it a slow search-engine.
That makes sense. They're doing their interpretation on the fly for one thing. For another just because they now have data that is 10 months more recent than their cutoff they don't have any of the intervening information. That's gotta make it tough.
Web search is super important for frameworks that are not (sufficiently?) in the training data. o3 often pulls info from Swift forums to find and fix obscure Swift concurrency issues for me.
In my experience none of the frontier models I tried (o3, Opus 4, Gemini 2.5 Pro) was able to solve Swift concurrency issues, with or without web search. At least not sufficiently for Swift 6 language mode. They don’t seem to have a mental model of the whole concept and how things (actors, isolation, Tasks) need to play together.
I haven't tried ChatGPT web search, but my experience with Claude web search is very good. It's actually what sold me and made me start using LLMs as part of my day to day. The citations they leave (I assume ChatGPT does the same) are killer for making sure I'm not being BSd on certain points.
That’s interesting. I use the API and there are zero citations with Claude, charGPT and Gemini. Only Kagi assistant gives me some, which is why I prefer it when researching facts.
What software to you use? The native Claude app? What subscription do you have?
Completely opposite experience here (with Claude). Most of my googling is now done through Claude- it can find and digest a d compile information much quicker and better than I'd do myself. Without web search you're basically asking an LLM to pull facts out of its ass- good luck with trusting the results.
It still is, not all queries trigger web search, and it takes more tokens and time to do research. ChatGPT will confidently give me outdated information, and unless I know it’s wrong and ask it to research, it wouldn’t know it is wrong. Having a more recent knowledge base can be very useful (for example, knowing who the president is without looking it up, making references to newer node versions instead of old ones)
The problem, perhaps illusory that it's easy to fix, is that the model will choose solutions that are a year old, e.g. thinking database/logger versions from December '24 are new and usable in a greenfield project despite newer quarterly LTS releases superseding them. I try to avoid humanizing these models, but could it be that in training/posttraining one could make it so the timestamp is fed in via the system prompt and actually respected? I've begged models to choose "new" dependencies after $DATE but they all still snap back to 2024
The biggest issue I can think of is code recommendations with out of date versions of packages. Maybe the quality of code has deteriorated in the past year and scraping github is not as useful to them anymore?
Knowledge cutoff isn’t a big deal for current events. Anything truly recent will have to be fed into the context anyway.
Where it does matter is for code generation. It’s error-prone and inefficient to try teaching a model how to use a new framework version via context alone, especially if the model was trained on an older API surface.
Isn’t this an issue with eg Cloudflare removing a portion of the web? I’m all for it from the perspective of people not having their content repackaged by an LLM, but it means that web search can’t check all sources.
Still relevant, as it means that a coding agent is more likely to get things right without searching. That saves time, money, and improves accuracy of results.
Right now nothing affects the underlying model weights. They are computed once during pretraining at enormous expense, adjusted incrementally during training, and then left untouched until the next frontier model is built.
Being able to adjust the weights will be the next big leap IMO, maybe the last one. It won't happen in real time but periodically, during intervals which I imagine we'll refer to as "sleep." At that point the model will do everything we do, at least potentially.
It absolutely is, for example, even in coding where new design patterns or language features aren't easy to leverage.
Web search enables targeted info to be "updated" at query time. But it doesn't get used for every query and you're practically limited in how much you can query.
I had 2.5 Flash refuse to summarise a URL that had today's date encoded in it because "That web page is from the future so may not exist yet or may be missing" or something like that. Amusing.
2.5 Pro went ahead and summarized it (but completely ignored a # reference so summarised the wrong section of a multi-topic page, but that's a different problem.)
maybe OpenAI have a terribly inefficient data ingestion pipeline? (wild guess) basically taking in new data is tedious so they do that infrequently and keep using old data for training.
> . . . with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say “think hard about this” in the prompt).
So that's not really a unified system then, it's just supposed to appear as if it is.
This looks like they're not training the single big model but instead have gone off to develop special sub models and attempt to gloss over them with yet another model. That's what you resort to only when doing the end-to-end training has become too expensive for you.
I know this is just arguing semantics, but wouldn't you call it a unified system since it has a single interface that automatically interacts with different components? It's not a unified model, but it seems correct to call it a unified system.
Altman et al have been discussing the many model interface in ChatGPT is confusing to users and they want to move to a unified system that exposes a model that routes based on the task rather than depending on users understanding how and when to do that. Presumably this is what they’ve been discussing for some time. I don’t know that was intended to mean they would be working toward some unified inference architecture and model, although I’m sure goal posts will be moved to ensure it’s insufficient.
so openai is in the business of GPT wrappers now? I'm guessing their open model is an escape for those who wanted to have a "plain" model, though from my systematic testing, it's not much better than Kimi K2
> While GPT‑5 in ChatGPT is a system of reasoning, non-reasoning, and router models, GPT‑5 in the API platform is the reasoning model that powers maximum performance in ChatGPT. Notably, GPT‑5 with minimal reasoning is a different model than the non-reasoning model in ChatGPT, and is better tuned for developers. The non-reasoning model used in ChatGPT is available as gpt-5-chat-latest.
You could train that architecture end-to-end though. You just have to run both models and backprop through both of them in training. Sort of like mixture of experts but with two very different experts.
>This looks like they're not training the single big model but instead have gone off to develop special sub models and attempt to gloss over them with yet another model. That's what you resort to only when doing the end-to-end training has become too expensive for you.
The corollary to the bitter lesson strikes again: any hand crafted system will out perform any general system for the same budget by a wide margin.
Too expensive maybe, or just not effective anymore as they used up any available training data. New data is generated slowly, and is massively poisoned with AI generated data, so it might be useless.
That's a lie people repeat because they want it to be true.
People evaluate dataset quality over time. There's no evidence that datasets from 2022 onwards perform any worse than ones from before 2022. There is some weak evidence of an opposite effect, causes unknown.
It's easy to make "model collapse" happen in lab conditions - but in real world circumstances, it fails to materialize.
The bitter lesson doesn't say that you can't split your solution into multiple models. It says that learning from more data via scaled compute will outperform humans injecting their own assumptions about the task into models.
A broad generalization like "there are two systems of thinking: fast, and slow" doesn't necessarily fall into this category. The transformer itself (plus the choice of positional encoding etc.) contains inductive biases about modeling sequences. The router is presumably still learned with a fairly generic architecture.
Sure, all of machine learning involves making assumptions. The bitter lesson in a practical sense is about minimizing these assumptions, particularly those that pertain to human knowledge about how to perform a specific task.
I don't agree with your interpretation of the lesson if you say it means to make no assumptions. You can try to model language with just a massive fully connected network to be maximally flexible, and you'll find that you fail. The art of applying the lesson is separating your assumptions that come from "expert knowledge" about the task from assumptions that match the most general structure of the problem.
"Time spent thinking" is a fundamental property of any system that thinks. To separate this into two modes: low and high, is not necessarily too strong of an assumption in my opinion.
I completely agree with you regarding many specialized sub-models where the distinction is arbitrary and informed by human knowledge about particular problems.
so many people at my work need it just switch. they just leave it on 4o. you can still set the model yourself if you want. but this will for sure improve the quality of output for my non technical workmates who are confused by model selection.
I'm a technical person, who has yet to invest the time in learning proper model selection too. This will be good for all users who don't bring AI to the forefront of their attention, and simply use it as a tool.
I say that as a VIM user who has been learning VIM commands for decades. I understand more than most how important it is to invest in one's tools. But I also understand that only so much time can be invested in sharpening the tools, when we have actual work to do with them. Using the LLMs as a fancy auto complete, but leaving the architecture up to my own NS (natural stupidity) has shown the default models to be more than adequate for my needs.
> The ultimate reason for this is Moore's law, or rather its generalization of continued exponentially falling cost per unit of computation
Is it though? To me it seems like performance gains are slowing down and additional computation in AI comes mostly from insane amounts of money thrown at it.
Yes, custom hand crafted model will always outperform general statistical models when given the same compute budget. Given that we've basically saturated the power grid at this point we may have to do the unthinkable and start thinking again.
We already did this for Object/Face recognition, it works but it's not the way to go. It's the way to go only if you don't have enough compute power (and data, I suspect) for a E2E network
No, it's what you do if your model architecture is capped out on its ability to profit from further training. Hand-wrapping a bunch of sub-models stands in for models that can learn that kind of substructure directly.
I do agree that the current evolution is moving further and further away from AGI, and more toward a spectrum of niche/specialisation.
It feels less and less likely AGI is even possible with the data we have available. The one unknown is if we manage to get usable quantum computers, what that will do to AI, I am curious.
I'm not really convinced, the benchmark blunder was really strange but the demos were quite underwhelming, and it appears this was reflected by a huge market correction in the betting markets as to who will have the best AI by end of the year.
What excites me now is that Gemini 3.0 or some answer from Google is coming soon and that will be the one I will actually end up using. It seems like the last mover in the LLM race is more advantageous.
Polymarket betters are not impressed. Based upon the market odds, OpenAI had a 35% chance to have the best model (at year end), but those odds have dropped to 18% today.
(I'm mostly making this comment to document what happened for the history books.)
After a few hours with gpt-5, I'd trade that spread. Not that I think oAI will win end of year. But I think gpt5 is better than it looks on the benchmark side. It is very very good at something we don't have a lot of benchmarks for -- keeping track of where it's at. codex is vassstly better in practice than claude code or gemini cli right now.
On the chat side, it's also quite different, and I wouldn't be surprised if people need some time to get a taste and a preference for it. I ask most models to help me build a macbook pro charger in 15th century florence with the instructions that I start with only my laptop and I can only talk for four hours of chat before the battery dies -- 5 was notable in that it thought through a bunch of second order implications of plans and offered some unusual things, including a list of instructions for a foot-treadle-based split ring commutator + generator in 15th century florentine italian(!). I have no way of verifying if the italian was correct.
Upshot - I think they did something very special with long context and iterative task management, and I would be surprised if they don't keep improving 5, based on their new branding and marketing plan.
That said, to me this is one of the first 'product release' moments in the frontier model space. 5 is not so much a model release as a polished-up, holes-fixed, annoyances-reduced/removed, 10x faster type of product launch. Google (current polymarket favorite) is remarkably bad at those product releases.
Back to betting - I bet there's a moment this year where those numbers change 10% in oAIs favor.
How on Earth does that market have Anthropic at 2%, in a dead heat with the likes of Meta? If the market was about yesterday rather than 5 months from now I think Claude would be pretty clearly the front runner. Why does the market so confidently think they’ll drop to dead last in the next little while?
It's because those markets are based on the LLM Arena leaderboard (https://lmarena.ai/), where Claude has historically done poorly.
That eval has also become a lot less relevant (it's considered not very indicative of real-world performance), so it's unlikely Anthropic will prioritize optimizing for it in future models.
Anthropic has always been one of the best at not optimizing for stupid metrics. Rather, they spend significant energy researching weaknesses and building metrics around that. Google is also pretty on point IMO, but they can also afford to dedicate to these nonsense metrics as they are still good marketing.
Meanwhile Meta and Xai are behind the ball and largely marketing focused.
How is Claude doing on the benchmark that market is based on? Maybe not so good? Idk. Just because Claude is good for real world use doesn't mean it's winning the benchmark, but the benchmark is all that matters for the Polymarket.
I think they also based their expectation on the release cycles and speeds of update. Anthropic is known for more conservative release cycle and incremental updates. Google on the other hand is accelerated recently. It also seems that other actors are better at benchmark cheating ;)
Well I for example don't give a shit what prediction markets do and never participated, but if someone thinks they're wrong, they should just participate and get free money. Otherwise why complain.
I mean, if you feel strongly enough that it will be #1 at the end of year then $100 now would net you $3000 end of year... Do bear in mind what my sibling said about the specific benchmark that is being used, though.
Elon's Y Combinator interview was pretty good. He seemed more in his element back amongst the hacker crowd (rather than dirty politics), and seemed to be doing hackery things at X, like renting generators and mobile cooling vans and just putting them the car park outside a warehouse to train Grok, since there were no data centres available and he was told it would take 2 years to set it all up properly.
I think he's just good at attracting good talent, and letting them focus on the right things to move fast initially, while cutting the supporting infra down to zero until it's needed.
Thinking more cynically: political corruption and connections I'm guessing? Just a couple months ago Musk was treating the US government like his personal playground.
I am convinced. I've been giving it tasks the past couple hours that Opus 4.1 was failing on and it not only did them but cleaned up the mess Opus made. It's the real deal.
When it came out on Tuesday I wanted to throw my laptop out of the window. I don't know what happened but results were total garbage earlier this week. It got better the past couple days but so far with gpt-5 being able to solve problems without as much correction I'm going to use it more.
Plus it's the mega monopoly that is already being scrutinized by the government. Every tech company seems to start out with too much credibility that it has to whittle down little by little before we really hold them accountable.
Yes, I would only prefer Gemini because google is under scrutiny, not because I think I know alphabet better than openAI. I think it’s a changing beast and no one can “know” it, it’s an illusion created by the brand, underneath it, it’s different every day.
If you think manifest v2 is related to being more evil you have to rethink your sense of ethics. Companies of that size regularly engage in business that results in the deaths of many innocent people. Overall Google does quite well by many metrics compared to its peers.
Yea we’re in Silicon Valley’s Lex Luthor era. World Coin is just really next level though compared to most Google things. Sama has kinda always been going for the Lex Luthor vibe.
Growing up in a Southern Baptist household where televangelists preached the end of the world every day at 4 PM, World Coin has some serious Antichrist and Revelation vibes. I'll give you that point.
The marketing copy and the current livestream appear tautological: "it's better because it's better."
Not much explanation yet why GPT-5 warrants a major version bump. As usual, the model (and potentially OpenAI as a whole) will depend on output vibe checks.
As someone who tries to push the limits of hard coding tasks (mainly refactoring old codebases) to LLMs with not much improvement since the last round of models, I'm finding that we are hitting the reduction of rate of improvement on the S-curve of quality. Obviously getting the same quality cheaper would be huge, but the quality of the output day to day isn't noticeable to me.
I find it struggles to even refactor codebases that aren't that large. If you have a somewhat complicated change that spans the full stack, and has some sort of wrinkle that makes it slightly more complicated than adding a data field, then even the most modern LLMs seem to trip on themselves. Even when I tell it to create a plan for implementation and write it to a markdown file and then step through those steps in a separate prompt.
Not that it makes it useless, just that we seem to not "be there" yet for the standard tasks software engineers do every day.
I haven’t used GPT5 yet, but even on a 1000 line code base I found Opus 4, o3, etc. to be very hit or miss. The trouble is I can’t seem to predict when these models will hit. So the misses cost time, reducing their overall utility.
I'm exclusively using sonnet via claude-code on their max plan (opting to specify sonnet so that opus isn't used). I just wasn't pleased with the opus output, but maybe I just need to use it differently. I haven't bothered with 4.1 yet. Another thing I noticed is opus would eat up my caps super quick, whereas using sonnet exclusively I never hit a cap.
I'd really just love incremental improvements over sonnet. Increasing the context window on sonnet would be a game changer for me. After auto-compact the quality may fall off a cliff and I need to spend some time bringing it back up to speed.
When I need a bit more punch for more reasoning / architecture type evaluations, I have it talk to gemini pro via zen mcp and OpenRouter. I've been considering setting up a subagent for architecture / system design decisions that would use the latest opus to see if it's better than gemini pro (so far I have no complaints though).
Agree, I think they'll need to move to performance now. If a model was comparable to Claude 4, but took like 500ms or less per edit. A quicker feedback loop would be a big improvement.
2:40 "I do like how the pelican's feet are on the pedals." "That's a rare detail that most of the other models I've tried this on have missed."
4:12 "The bicycle was flawless."
5:30 Re generating documentation: "It nailed it. It gave me the exact information I needed. It gave me full architectural overview. It was clearly very good at consuming a quarter million tokens of rust." "My trust issues are beginning to fall away"
I feel like we need to move on from using the same test on models since as time goes on the information about these specific test is out there in the training data and while i am not saying that it's happened in this case there is nothing stopping model developers from adding extra data for theses tests directly in the training data to make their models seem better than they are
Honestly, I have mixed feelings about him appearing there. His blog posts are a nice way to be updated about what's going on, and he deserves the recognition, but he's now part of their marketing content. I hope that doesn't make him afraid of speaking his mind when talking about OpenAI's models. I still trust his opinions, though.
When they were about to release gpt4 I remember the hype was so high there were a lot of AGI debates. But then was quickly out-shadowed by more advanced models.
People knew that gpt5 wouldn’t be an AGI or even close to that. It’s just an updated version. GptN would become more or leas like an annual release.
There's a bunch of benchmarks on the intro page including AIME 2025 without tools, SWE-bench Verified, Aider Polyglot, MMMU, and HealthBench Hard (not familiar with this one): https://openai.com/index/introducing-gpt-5/
It seems like you might need less output tokens for the same quality of response though. One of their plots shows o3 needing ~14k tokens to get 69% on SWE-bench Verified, but GPT-5 needing only ~4k.
O3 has had some major price cuts since Gemini 2.5 Pro came out. At the time, o3 cost $10/Mtok in and $40/Mtok out. The big deal with Gemini 2.5 Pro was it had comparable quality to o3 at a fraction of the cost.
I'm not sure when they slashed the o3 pricing, but the GPT-5 pricing looks like they set it to be identical to Gemini 2.5 Pro.
Explains why I find AGI fundamentalists similar to tater heads. /s
(Not to undermine progress in the foundational model space, but there is a lack of appreciation for the democratization of domain specific models amongst HNers).
I'm being hyperbolic but yeah four roses is probably the best deal next to Buffalo trace. All their stuff is fairly priced. If you want something like Weller though, you should get another wheated bourbon like Maker's Mark French oaked.
If you can find Buffalo Trace for msrp which is $20-30, it's a good deal. I think the bourbon "market" kind of popped recently so finding things has been getting a little easier.
> I think the bourbon "market" kind of popped recently
It def did. The overproduction that was invested in during the peak of the COVID collector boom is coming into markets now. I think we'll see some well priced age stated products in the next 3-4 years based on by acquaintances in the space.
Ofc, the elephant in the room is consolidation - everyone wants to copy the LVMH model (and they say Europeans are ethical elves who never use underhanded mopolistic and market making behavior to corner markets /s).
I can already see LLMs Sommeliers: Yes, the mouthfeel and punch of GPT-5 it's comparable to the one of Grok 4, but it's tenderness lacks the crunch from Gemini 2.5 Pro.
Isn't it exactly what the typical LLM discourse is about? People are just throwing anecdotes and stay with their opinion. A is better than B because C, and that's basically it. And whoever tries to actually bench them gets called out because all benches are gamed. Go figure.
Always have been. This LLM-centered AI boom has been my craziest and most frustrating social experiment, propped up by the rhetoric (with no evidence to back it up) that this time we finally have the keys to AGI (whatever the hell that means), and infused with enough AstroTurfing to drive the discourse into ideological stances devoid of any substance (you must either be a true believer or a naysayer). On the plus side, it appears that this hype train is taking a bump with GPT-5.
The room is the limiting factor in most speaker setups. The worse the room, the sooner you hit diminishing returns for upgrading any other part of the system.
In a fantastic room a $50 speaker will be nowhere near 95% of the performance of a mastering monitor, no matter how much EQ you put on it. In the average living room with less than ideal speaker and listening position placement there will still be a difference, but it will be much less apparent due to the limitations of the listening environment.
You might lose headroom or have to live with higher latency but if your complaint is about actual empirical data like frequency response or phase, that can be corrected digitally.
You can only EQ speakers and headphones as far as the transducer can still respond accurately to the signal you're sending it. No amount of EQ will give the Sennheiser HD-600's good sub-bass performance because the driver begins to distort the signal long before you've amplified it enough to match the Harman target at a normal listening level.
DSP is a very powerful tool that can make terrible speakers and headphones sound great, but it's not magic.
Pretty much my first point… At the same time that same DSP can make a pretty mediocre speaker that can reproduce those frequencies do so in phase at the listening position so once again the point is moot, effectively add a cheap sub.
There is no time where you cannot get results from mediocre transducers given the right processing.
I’m not arguing you should, but in 2025 if a speaker sounds bad it is entirely because processing was skimped on.
Well, reduced sibilance is an ordinary and desirable thing. A better "audiophile absurdity" example would be $77,000 cables, freezing CDs to improve sound quality, using hospital-grade outlets, cryogenically frozen outlets (lol), the list goes on and on
Been using it all morning. Had to switch back to 4. 5 has all of the problems that 2/3 had with ignoring any context, flagrantly ignoring the 'spirit' of my requests, and talking to me like I'm a little baby.
Not to mention almost all of my prompts result in a several minute wait with "thinking longer about the answer".
Watching the livestream now, the improvement over their current models on the benchmarks is very small. I know they seemed to be trying to temper our expectations leading up to this, but this is much less improvement than I was expecting
I have a suspicion that while the major AI companies have been pretty samey and competing in the same space for a while now, the market is going to force them to differentiate a bit, and we're going to see OpenAI begin to lose the race toward extremely high levels of intelligence instead choosing to focus on justifying their valuations by optimizing cost and for conversational/normal intelligence/personal assistant use-cases. After all, most of their users just want to use it to cheat at school, get relationship advice, and write business emails. They also have Ive's company to continue investing in.
Meanwhile, Anthropic & Google have more room in their P/S ratios to continue to spend effort on logarithmic intelligence gains.
Doesn't mean we won't see more and more intelligent models out of OpenAI, especially in the o-series, but at some point you have to make payroll and reality hits.
"+100 points" sounds like a lot until you do the ELO math and see that means 1 out of 3 people still preferred Claud Opus 4's response. Remember 1 out of 2 would place the models dead even.
Then why increment the version number here? This is clearly styled like a "mic drop" release but without the numbers to back it up. It's a really bad look when comparing the crazy jump from GPT3 to GPT4 to this slight improvement with GPT5.
GPT-5 was highly anticipated and people have thought it would be a step change in performance for a while. I think at some point they had to just do it and rip the bandaid off, so they could move past 5.
It was relative to the number the comment I replied to included. I would assume GPT-5 is nowhere near 100x the parameters of o3. My point is that if this release isn't notable because of parameter count, nor (importantly) performance, what is it notable for? I guess it unifies the thinking and non-thinking models, but this is more of a product improvement, not a model improvement.
The fact that it unifies the regular model and the reasoning model is a big change. I’m sure internally it’s a big change, but also in terms of user experience.
I feel it’s worthy of a major increment, even if benchmarks aren’t significantly improved.
Also, the code demos are all using GPT-5 MAX on Cursor. Most of us will not be able to use it like that all the time. They should have showed it without MAX mode as well
The hallucination benchmarks did show major improvement. We know existing benchmarks are nearly useless at this point. It's reliability that matters more.
I’m more worried about how they still confidently reason through things incorrectly all the time, which isn’t quite the same as hallucination, but it’s in a similar vein.
I mean that's just the consequence of releasing a new model every couple months. If Open AI stayed mostly silent since the GPT-4 release (like they did for most iterations) and only now released 5 then nobody would be complaining about weak gains in benchmarks.
If everyone else had stayed silent as well, then I would agree. But as it is right now they are juuust about managing to match the current pace of the other contenders.
Which actually is fine, but they have previously set quite high expectations. So some will probably be disappointed at this.
If they had stayed silent since GPT-4, nobody would care what OpenAI was releasing as they would have become completely irrelevant compared to Gemini/Claude.
It makes it look like the presentation is rushed or made last minute. Really bad to see this as the first plot in the whole presentation. Also, I would have loved to see comparisons with Opus 4.1.
Edit: Opus 4.1 scores 74.5% (https://www.anthropic.com/news/claude-opus-4-1). This makes it sound like Anthropic released the upgrade to still be the leader on this important benchmark.
After reading around, it seems like they probably forgot to update/swap the slides before presentation. The graphs were correct on their website, as they launched. But the ones they used in the presentation were probably some older versions they had forgotten to fix.
Some people have hypothesized that GPT-5 is actually about cost reduction and internal optimization for OpenAI, since there doesn't seem to be much of a leap forward, but another element that they seem to have focused on that'll probably make a huge difference to "normal" (non-tech) users is making precise and specifically worded prompts less necessary.
They've mentioned improvements in that aspects a few times now, and if it actually materializes, that would be a big leap forward for most users even if underneath GPT-4 was also technically able to do the same things if prompted just the right way.
yeah i think they shot themselves in the foot a bit here by creating the o series. the truth is that GPT-5 _is_ a huge step forward, for the "GPT-x" models. The current GPT-x model was basically still 4o, with 4.1 available in some capacity. GPT-5 vs GPT-4o looks like a massive upgrade.
But it's only an incremental improvement over the existing o line. So people feel like the improvement from the current OpenAI SoTA isn't there to justify a whole bump. They probably should have just called o1 GPT-5 last year.
You cannot even access the other models any more from the app. This is a huge bummer that is having me consider other brands. I don't trust gpt-5 yet, but I do trust 4.1 and most of my in-progress conversations are 4.1 based.
It sounded like they were very careful to always mention that those improvements were for ChatGPT, so I'm very skeptical that they translate to the API versions of GPT-5.
If this performs well in independent needle-in-haystack and adherence evaluations, this pricing with this context window alone would make GPT-5 extremely competitive with Gemini 2.5 Pro and Claude Opus 4.1, even if the output isn't a significant improvement over o3. If the output quality ends up on-par or better than the two major competitors, that'd be truly a massive leap forward for OpenAI, mini and nano maybe even more so.
Are you kidding? If GPT 5 is really on par with Opus 4.1, it means now OpenAI is offering the same product but 10 times cheaper. In any other industry it's not just a massive leap. It's "all competitors are out of market in a few months if they can't release something similar."
Yes, [1] though a bit vague given "Some organizations may already have access to these models and capabilities without having to go through the Verification process."
I never verified but have access to all models including image gen, for example.
Neither will be. Both OpenRouter and Azure (through requiring and enterprise agreement, only available to large orgs with 500+ devices) require it for o3 to this very day, and already do so for GPT-5, the main model under discussion in this thread (sure, not mini and nano, but those aren't where 95% of the attention is focused on).
Where did you get that from? I am currently using GPT-5 via OpenRouter and never added an OpenAI key to my account there. Same for any previous OpenAI model. BYOK is an option, not a necessity.
> {"id":"openai/gpt-5-chat","canonical_slug":"openai/gpt-5-chat-2025-08-07","hugging_face_id":"","name":"OpenAI: GPT-5 Chat","created":1754587837,"description":"GPT-5 Chat is designed for advanced, natural, multimodal, and context-aware conversations for enterprise applications.","context_length":400000,"architecture":{"modality":"text+image->text","input_modalities":["file","image","text"],"output_modalities":["text"],"tokenizer":"GPT","instruct_type":null},"pricing":{"prompt":"0.00000125","completion":"0.00001","request":"0","image":"0","audio":"0","web_search":"0","internal_reasoning":"0","input_cache_read":"0.000000125"},"top_provider":{"context_length":400000,"max_completion_tokens":128000,"is_moderated":true},"per_request_limits":null,"supported_parameters":["max_tokens","response_format","seed","structured_outputs"]},
If you look at the JSON you linked, it does not enforce BYOK for openai/gpt-5-chat, nor for openai/gpt-5-mini or openai/gpt-5-nano.
Interesting that gpt-5 has Oct 01, 2024 as knowledge cut-off while gpt-5-mini/nano it's May 31, 2024.
gpt-4.1 family had 1M/32k input/output tokens. Pricing-wise, it's 37% cheaper input tokens, but 25% more expensive on output tokens. Only nano is 50% cheaper on input and unchanged on output.
It was an obvious decision product wise even if it may not appease some devs.
Regular users just see incrementing numbers, why would they want to use 3 or 4 if there is a 5? This is how people who aren't entrenched in AI think.
Ask some of your friends what the difference is between models and some will have no clue that currently some of the 3 models are better than 4 models, or they'll not understand what the "o" means at all. And some think why would I ever use mini?
My girlfriend when asked about models: What do you mean, I just ask ChatGPT?
I think people here vastly underestimate how many people just type questions into the chatbox, and that's it. When you think about the product from that perspective, this release is probably a huge jump for many people who have never used anything but the default model. Whereas, if you've been using o3 all along, this is just another nice incremental improvement.
It is frankly ridiculous to assume anyone would think that 4o is in anyway worse then o3. I don't understand why these companies suck at basic marketing this hard, like what is with all these .5s and mini and other shit names. Just increment the fucking number or if you are embarrassed by having to increase the number all the time just use year/month. Then you can have different flavors like "light and fast" or "deep thinker" and of course just the regular "GPT X"
Many companies face model regressions on actively used workflows. Microsoft is the cloud provider who won’t force you to upgrade to new models. This has driven enterprises facing model regressions to Microsoft, not just for workflows facing this problem, but also new workflows just to be safe and not have to migrate clouds if there is a regression.
Of course, I know that having a line-up of tons of models is quite confusing. Yet I also believe users on the paid plan deserve more options.
As a paying user, I liked the ability to set which models to use each time, in particular switching between o4-mini and o4-mini-high.
Now they’ve deprecated this feature and I’m stuck with their base GPT-5 model or GPT-5 Thinking, which seems akin to o3 and thus has much smaller usage limits. Only God knows whether their routing will work as well as my previous system for selecting models.
This is where I’m at, too. The o3 limits were more restrictive than the 5-thinking limits are now, but I regularly used o4-mini-high for complex-but-not-brain-breaking questions and was quite happy with the result. Now I have to choose between saving my usage with 5, which so far hasn’t felt up to the more complex use cases, or burn usage much faster with 5-thinking.
I suppose this is probably the point. I’m still not super keen on ponying up 200 bucks a month, but it’s more likely now.
I don't have confidence that systems built on top of a specific model will work the same on a higher version. Unlike, say, the Go programming language where backwards compatibility is something you can generally count on (with exceptions being well documented).
I wouldn't want to be in charge of regression testing an LLM-based enterprise software app when bumping the underlying model.
Smart way to probably also free up resources that are currently fragmented running those older models. They could all run the latest model and have more capacity.
GPT-5-nano does not support temperature parameter and is giving me worse quality results than GPT-4.1-nano. Will be interesting if they truly do end up retiring a better model in favor of a worse one.
They probably will. Given how fast GPT 5 is, it feels like all the models are very small.
Maybe to service more users they're thinking they'll shrink the models and have reasoning close the gap... of course, that only really works for verifiable tasks.
And I've seen the claims of a "universal verifier", but that feels like the Philosopher's Stone of AI. Everyone who's tried it has shown limited carryover between verifiable tasks (like code) to tasks with subjective preference.
-
To clarify also: I don't think this is nefarious. I think as you serve more users, you need to at least try to reign in the unit economics.
Even OpenAI can only afford to burn so many dollars per user per week once they're trying to serve a billion users a week. At some point there isn't even enough money to be raised to keep up with costs.
> For an airplane wing (airfoil), the top surface is curved and the bottom is flatter. When the wing moves forward:
> * Air over the top has to travel farther in the same amount of time -> it moves faster -> pressure on the top decreases.
> * Air underneath moves slower -> pressure underneath is higher
> * The presure difference creates an upward force - lift
Isn't that explanation of why wings work completely wrong? There's nothing that forces the air to cover the top distance in the same time that it covers the bottom distance, and in fact it doesn't. https://www.cam.ac.uk/research/news/how-wings-really-work
Very strange to use a mistake as your first demo, especially while talking about how it's phd level.
It appears to me like the linked explanation is also subtly wrong, in a different way:
“This is why a flat surface like a sail is able to cause lift – here the distance on each side is the same but it is slightly curved when it is rigged and so it acts as an aerofoil. In other words, it’s the curvature that creates lift, not the distance.”
But like you say flat plates can generate lift at positive AoA, no curvature (camber) required. Can you confirm this is correct? Kinda going crazy because I'd very much expect a Cambridge aerodynamicist to get this 100% right.
Yes, it is wrong. The curvature of the sail lowers the leading angle of attack which promotes attachment, i.e. reduces the risk of stalling at high angles of attack, but it is not responsible for lift in the sense you mean.
It could be argued that preventing a stall makes it responsible for lift in an AoA regime where the wing would otherwise be stalled -- hence "responsible for lift" -- but that would be far fetched.
More likely the author wanted to give an intuition for the cuvature of the airflow. This is produced not by the shape of the airfoil but the induced circulation around the airfoil, which makes air travel faster on the side of the far surface of an airfoil, creating the pressure differential.
It's both lower pressure above the wing (~20% of lift) and the reaction force from pushing air down (give or take the remaining 80% of lift). The main wrong thing is that the air travels faster because it has to travel farther causing the air to accelerate causing the lower pressure that's double plus wrong. It's a weird old misunderstanding that gets repeated over and over because it's a neat connection to attach to the Bernoulli Principal when it's being explained to children.
How can you create a pocket of 'lower pressure' without deflecting some of the air away? At the end of the day, if the aircraft is moving up, it needs to be throwing something down to counteract gravity.
Exactly. The speed phenomenon (airflow speeding up due to getting sucked into the lower pressure space above the wing) is certainly there, but it's happening because the wing is shaped to deflect air downwards.
a classic example of how LLM's mislead people. They don't know right from wrong, they know what they have been trained on. Even with reasoning capabilities
That's one of my biggest hang ups on the LLMs to AGI hype pipeline, no matter how much training and tweaking we throw at them they still don't seem to be able to not fall back to repeating common misconceptions found in their training data. If they're supposed to be PhD level collaborators I would expect better from them.
Not to say they can't be useful tools but they fall into the same basic traps and issues despite our continues attempts to improve them.
Angle of attack is a big part but I think the other thing going on is air “sticks” to the surface of the top of the wing and gets directed downward as it comes off the wing. It also creates a gap as the wing curves down leaving behind lower pressure from that.
It's really not. The wing is angled so it pushes the air down. Pushing air down means you are pushing the plane up. A wing can literally be a flat sheet at an angle and it would still fly.
It gets complex if you want to fully model things and make it fly as efficiently as possible, but that isn't really in the scope of the question.
Planes go up because they push air down. Simple as that.
It's both that simple and not. Because it's also true that the wing's shape creates a pressure differential and that's what produce lift. And the pressure differential causes the momentum transfer to the wing, the opposing force to the wing's lift creates the momentum transfer, and pressure difference also causes the change in speed and vice-versa. You can create many correct (and many more incorrect) straightforward stories about the path to lift but in reality cause and effect are not so straightforward and I think it's misleading to go "well this story is the one true simple story".
Sure but it creates a pressure differential by pushing the air down (in most wings). Pressure differentials are an unnecessarily detailed description of what is going on that just confuses people.
You wouldn't explain how swimming works with pressure differentials. You'd just say "you push water backwards and that makes you go fowards". If you start talking about pressure differentials... maybe you're technically correct, but it's a confusing and unnecessarily complex explanation that doesn't give the correct intuitive idea of what is happening.
Sure. If you're going for a basic 'how does it work', then 'pushing air down' is a good starting point, but you'll really struggle with follow-up questions like 'then why are they that shape?' unless you're willing to go into a bit more detail.
How can you create a 'pressure differential' without deflecting some of the air away? At the end of the day, if the aircraft is moving up, it needs to be throwing something down to counteract gravity. If there is some pressure differential that you can observe, that's nice, but you can't get away from momentum conservation.
You can't, but you also can't get away from a pressure differential. Those things are linked! That's my main point, arguing over which of these explanations is more correct is arguing over what exactly the shape of an object's silhouette is: it depends on what direction you're looking at it from.
The pressure differential is created by the leading edge creating a narrow flow region, which opens to a wider flow region at the trailing edge. This pulls the air at the leading edge across the top of the wing, making it much faster than the air below the wing. This, in turn, creates a low pressure zone.
Air molecules travel in all directions, not just down, so with a pressure differential that means the air molecules below the wing are applying a significant force upward, no longer balanced by the equal pressure usually on the top of the wing. Thus, lift through boyancy. Your question is now about the same as "why does wood float in water"?
The "throwing something down" here comes from the air molecules below the wing hitting the wing upward, then bouncing down.
All the energy to do this comes from the plane's forward momentum, consumed by drag and transformed by the complex fluid dynamics of the air.
Any non-zero angle of attack also pushes air down, of course. And the shape of the wing with the "stickiness" of the air means some more air can be thrown down by the shape of the wing's top edge.
Sorry, I know nothing about this topic, but this is how it was explained to me every time it's come up throughout my life. Could you explain a bit more?
I've always been under the impression that flat-plate airfoils can't generate lift without a positive angle-of-attack - where lift is generated through the separate mechanism of the air pushing against an angled plane? But a modern airfoil can, because of this effect.
And that if you flip them upside down, a flat plate is more efficient and requires less angle-of-attack than the standard airfoil shape because now the lift advantage is working to generate a downforce.
I just tried to search Google, but I'm finding all sorts of conflicting answers, with only a vague consensus that the AI-provided answer above is, in fact, correct. The shape of the wing causes pressure differences that generate lift in conjunction with multiple other effects that also generate lift by pushing or redirecting air downward.
The core part, which is incorrect and misleading, is 'the air needs to take an equal time to transit the top and bottom of the wing'. From that you can derive the correct statement that 'the air traveling across the top of the wing is moving faster', but you've not correctly explained why that is the case. And in fact, it's completely wrong that the transit time is equal: the videos from the page something linked above show that usually the air above the top takes less time than the bottom, and it's probably interesting to work out why that's the case!
(Also, once you've got the 'moving faster' you can then tell a mostly correct story through bernuolli's principle to get to lower pressure on the top and thus lift, but you're also going to confuse people if you say this is the one true story and any other explaination, like one that talks about momentum, or e.g. the curvature of the airflow causing the pressure gradient instead is wrong, because these are all simply multiple paths through the same underlying set of interactions which are not so easy to fundamentally seperate into cause and effect. But 'equal transit time' appears in none of the correct paths as an axiom, nor a necessary result, and there's basically no reason to use it in an explanation, because there's simpler correct stories if you want to dumb it down for people)
>Air over the top has to travel farther in the same amount of time
There is no requirement for air to travel any where. Let alone in any amount of time. So this part of the AI's response is completely wrong. "Same amount of time" as what? Air going underneath the wing? With an angle of attack the air under the wing is being deflected down, not magically meeting up with the air above the wing.
But this just sounds like a simplified layman explanation, the same way most of the ways we talk about electricity are completely wrong in terms of how electricity actually works.
If you look at airflow over an asymmetric airfoil [1], the air does move faster over the top. Sure, it doesn't arrive "at the same time" (it goes much faster than that) or fully describe why these effects are happening, but that's why it's a simplification for lay people. Wikipedia says [2]:
> Although the two simple Bernoulli-based explanations above are incorrect, there is nothing incorrect about Bernoulli's principle or the fact that the air goes faster on the top of the wing, and Bernoulli's principle can be used correctly as part of a more complicated explanation of lift.
But from what I can tell, the root of the answer is right. The shape of a wing causes pressure zones to form above and below the wing, generating extra lift (on top of deflection). From NASA's page [3]:
> {The upper flow is faster and from Bernoulli's equation the pressure is lower. The difference in pressure across the airfoil produces the lift.} As we have seen in Experiment #1, this part of the theory is correct. In fact, this theory is very appealing because many parts of the theory are correct.
That isn't to defend the AI response, it should know better given how many resources there are on this answer being misleading.
And so I don't leave without a satisfying conclusion, the better layman explanation should be (paraphrasing from the Smithsonian page [4]):
> The shape of the wing pushes air up, creating a leading edge with narrow flow. This small high pressure region is followed by the decline to the wider-flow trailing edge, which creates a low pressure region that sucks the air on the leading edge backward. In the process, the air above the wing rapidly accelerates and the air flowing above the top of the wing as a whole forms of a lower pressure region than the air below. Thus, lift advantage even when horizontal.
Someone please correct that if I've said something wrong.
Shame the person supposedly with a PHD on this didn't explain it at all.
The bottom line is that a curved airfoil will not generate any more lift than a non-curved airfoil (pre-stall) that has its trailing edge at the same angle.
The function of the curvature is to improve the wing's ability to avoid stall at a high angle of attack.
According to NASA, the Air and Space Museum, and Wikipedia: you are wrong. Nor does what you're a saying making any sense to anyone who has seen an airplane fly straight.
Symmetric airfoils do not generate lift without a positive angle of attack. Cambered airfoils do, precisely because the camber itself creates lift via Bernoulli.
I stated "has its trailing edge at the same angle", not "is at the same angle of attack". Angle of attack is defined by the angle of the chord line, not the angle of the trailing edge. Cambered airfoils have their trailing edges at higher angles than the angle of attack.
Again, not an expert, but how does that jive with the existence of reflex cambered airfoils? Positive lift at zero AoA with a negative trailing edge AoA.
And that seems to directly conflict with the models shown by the resources above? They state that cambered wings do have increased airspeed above the wing, which generates lift via pressure differential (thus why the myth is so sticky).
Reflex cambered airfoils generate lift because most of the wing is still pointed downwards.
The crucial thing you need to explain is this: why doesn't extending leading edge droop flaps increase the lift at a pre-stall angle of attack? (See Figure 13 from this NASA study for example: https://ntrs.nasa.gov/citations/19800004771)
Im quite sure the "air on the top has to travel faster to meet the air at the bottom " is false. Why would they have to meet at the same time? What would cause air on the top to accelerate?
I did a little more research and explain it above. The fundamentals are actually right.
The leading edge pressurizes the air by forcing air up, then the trailing edge opens back up, creating a low pressure zone that sucks air in the leading edge back. As a whole, the air atop the wing accelerates to be much faster than the air below, creating a pressure differential above and below the wing and causing lift.
The AI is still wrong on the actual mechanics at play, of course, but I don't see how this is significantly worse than the way we simplify electricity to lay people. The core "air moving faster on the top makes low pressure" is right.
That explanation doesn’t work if the wing is completely flat (with nothing to force the air up), which if you ever made a paper airplane flies just fine. All these explanations miss a very significant thing: air is a fluid where every molecule collides with _billions_ of other molecules every second, and the wing distorts the airflow all around it, with significant effects up to a wingspan away in all directions.
Except it isn't "completely wrong". The article the OP links to says it explicitly:
> “What actually causes lift is introducing a shape into the airflow, which curves the streamlines and introduces pressure changes – lower pressure on the upper surface and higher pressure on the lower surface,” clarified Babinsky, from the Department of Engineering. “This is why a flat surface like a sail is able to cause lift – here the distance on each side is the same but it is slightly curved when it is rigged and so it acts as an aerofoil. In other words, it’s the curvature that creates lift, not the distance.”
The meta-point that "it's the curvature that creates the lift, not the distance" is incredibly subtle for a lay audience. So it may be completely wrong for you, but not for 99.9% of the population. The pressure differential is important, and the curvature does create lift, although not via speed differential.
I am far from an AI hypebeast, but this subthread feels like people reaching for a criticism.
I would still say its completely wrong, given that this explanation makes explicit predictions that are falsifiable, eg, that airplanes could not fly upside down (they can!).
I think its valid to say its wrong even if it reaches the same conclusion.
If I lay out a chain of thought like
Top and bottom are different -> god doesnt like things being diffferent and applies pressure to the bottom of the wing -> pressure underneath is higher than the top -> pressure difference creates lift
Then I think its valid to say thats completely inaccurate, and just happens to share some of the beginning and end
I would say a wing with two sides of different length is more difficult to understand than one shape with two sides of opposites curvatures but same length
the wrongness isn't germane to most people but it is a specific typology of how LLMs get technica lthings wrong that is critically important to progressing them. It gets subtle things wrongby being biased towards lay understandings that introduce vagueness because greater precision isn't useful.
That doesn't matter for lay audieces and doesn't really matter at all until we try and use them for technical things.
The wrongness is germane to someone who is doing their physics homework (the example given here). It's actually difficult for me to imagine a situation where someone would ask ChatGPT 5 for information about this and it not be germane if ChatGPT 5 gave an incorrect explanation.
The predicate for that is you know it is wrong, that wrongness is visible and identifiable. With knowledge that is intuitive but incorrect you multiply risk.
It's the "same amount of time" part that is blatantly wrong. Yes geometry has an effect but there is zero reason to believe leading edge particles, at the same time point, must rejoin at the trailing edge of a wing. This is a misconception at the level of "heavier objects fall faster." It is non-physical.
The video in the Cambridge link shows how the upper surface particles greatly overtake the lower surface flow. They do not rejoin, ever.
Again, you're not wrong, it's just irrelevant for most audiences. The very fact that you have to say this:
> Yes geometry has an effect but there is zero reason to believe leading edge particles, at the same time point, must rejoin at the trailing edge of a wing.
...implicitly concedes that point that this is subtle. If you gave this answer in a PhD qualification exam in Physics, then sure, I think it's fair for someone to say you're wrong. If you gave the answer on a marketing page for a general-purpose chatbot? Meh.
(As an aside, this conversation is interesting to me primarily because it's a perfect example of how scientists go wrong in presenting their work to the world...meeting up with AI criticism on the other side.)
right, the other is that if you remove every incorrect statement from the AI "explanation", the answer it would have given is "airplane wings generate lift because they are shaped to generate lift".
> right, the other is that if you remove every incorrect statement from the AI "explanation", the answer it would have given is "airplane wings generate lift because they are shaped to generate lift".
...only if you omit the parts where it talks about pressure differentials, caused by airspeed differences, create lift?
Both of these points are true. You have to be motivated to ignore them.
But using pressure differentials is also sort of tautological. Lift IS the integral of the pressure on the surface, so saying that the pressure differentials cause lift is... true but unsatisfying. It's what makes the pressure difference appear that's truly interesting.
Funnily enough, as an undergraduate the first explanation for lift that you will receive uses Feynman's "dry water" (the Kutta condition for inviscid fluids). In my opinion, this explanation is also unsatisfying, as it's usually presented as a mere mathematical "convenience" imposed upon the flow to make it behave like real physics.
Some recent papers [1] are shedding light on generalizing the Kutta condition on non-sharp airfoils. In my opinion, the linked papers gives a way more mathematically and intuitively satisfying answer, but of course it requires some previous knowledge, and would be totally inappropriate as an answer by the AI.
Either way I feel that if the AI is a "pocket PhD" (or "pocket industry expert") it should at least give some pointers to the user on what to read next, using both classical and modern findings.
The Kutta condition is insufficient to describe lift in all regimes (e.g. when the trailing edge of the wing isn't that sharp), but fundamentally you do need to fall back to certain 2nd law / boundary condition rules to describe why an airfoil generates lift, as well as when it doesn't (e.g. stall).
There's nothing in the Navier-Stokes equations that forces an airfoil to generate lift - without boundary conditions the flowing air could theoretically wrap back around at the trailing edge, thus resulting in zero lift.
The fact that you have to invoke integrals and the Kutta condition to make your explanation is exactly what is wrong with it.
Is it correct? Yes. Is it intuitive to someone who doesn’t have a background in calculus, physics and fluid dynamics? No.
People here are arguing about a subpoint on a subpoint that would maybe get you a deduction on a first-year physics exam, and acting as if this completely invalidates the response.
How is the Kutta condition ("the fluid gets deflected downwards because the back of the wing is sharp and pointing downwards") less intuitive to someone without a physics background than wrongly invoking the Bernoulli principle?
Saw you were a biologist. Would you be ok if I said, "Creationism got life started, but after that, we evolved via random mutations..."? The "equal transit time" is the same as a supernatural force compelling the physical world act in a certain way. It does not exist.
To me, it's weird to call it "PhD-level". That, to me, means to be able to take in existing information on a certain very niche area and able to "push the boundary". I might be wrong but to date I've never seen any LLM invent "new science", that makes PhD, really PhD. It also seems very confusing to me that many sources mention "stone age" and "PhD-level" in the same article. Which one is it?
People seem to overcomplicate what LLM's are capable of, but at their core they are just really good word parsers.
Most of the phd’s I know are studying things that I guarantee GPT-5 doesn’t know about… because they’re researching novel stuff.
Also, LLMs don’t have much consistency with how well they’re able to apply the knowledge that they supposedly have. Hence the “lots of almost correct code” stereotype that’s been going around.
I was using the fancy new Claude model yesterday to debug some fast-check tests (quickcheck-inspired typescript lib). Claude could absolutely not wrap its head around the shrinking behavior, which rendered it useless for debugging
It's an extremely famous example of a widespread misconception. I don't know anything about aeronautical engineering but I'm quite familiar with the "equal transit time fallacy."
Yeah, the explanation is just shallow enough to seem correct and deceive someone who doesn't grasp really well the subject.
No clue how they let it pass, that without mentioning the subpar diagram it created, really didn't seem like something miles better than what previous models can do already.
It’s very common to see AI evangelists taking its output at face value, particularly when it’s about something that they are not an expert in. I thought we’d start seeing less of this as people get burned by it, but it seems that we’re actually just seeing more of it as LLMs get better at sounding correct. Their ability to sound correct continues to increase faster than their ability to be correct.
During the demo they quickly shuffled off of, the air flow lines completely broke. It was just a few dots moving left to right, changing the angle of the surface showed no visual difference in airflow.
> Isn't that explanation of why wings work completely wrong?
This is an LLM. "Wrong" is not a concept that applies, as it requires understanding. The explanation is quite /probable/, as evidenced by the fact that they thought to use it as an example…
>In fact, theory predicts – and experiments confirm – that the air traverses the top surface of a body experiencing lift in a shorter time than it traverses the bottom surface; the explanation based on equal transit time is false.
So the effect is greater than equal time transit.
I've seen the GPT5 explanation in GCSE level textbooks but I thought it was supposed to be PhD level;)
Your link literally says pressure differential is the reason, and that curvature matters:
> “What actually causes lift is introducing a shape into the airflow, which curves the streamlines and introduces pressure changes – lower pressure on the upper surface and higher pressure on the lower surface,” clarified Babinsky, from the Department of Engineering. “This is why a flat surface like a sail is able to cause lift – here the distance on each side is the same but it is slightly curved when it is rigged and so it acts as an aerofoil. In other words, it’s the curvature that creates lift, not the distance.”
So I'd characterize this answer as "correct, but incomplete" or "correct, but simplified". It's a case where a PhD in fluid dynamics might state the explanation one way to an expert audience, but another way to a room full of children.
Pressure differential is absolutely one of the main components of lift (although I believe conservation of momentum is another - the coanda effect changes the direction of the airflows and there's 2nd law stuff happening on the bottom edge too), but the idea that the pressure differential is caused by the fact that "air over the top has to travel farther in the same amount of time" because the airfoil is curved is completely incorrect, as the video in my link shows.
It's "completely incorrect" only if you're being pedantic. It's "partially correct" if you're talking casually to a group of regular people. It's "good enough" if you're talking to a classroom of children. Audience matters.
The hilarious thing about this subthread is that it's already getting filled with hyper-technical but wrong alternative explanations by people eager to show that they know more than the robot.
"air over the top has to travel farther in the same amount of time" is just wrong, it doesn't have to, and in fact it doesn't.
It's called the "equal transit-time fallacy" if you want to look it up, or follow the link I provided in my comment, or perhaps the NASA link someone else offered.
I'm not saying that particular point is wrong. I'm saying that for most people, it doesn't matter, and the reason the "fallacy" persists is because it's a good enough explanation for the layman that is easy to conceptualize.
Pretty much any scientific question is fractal like this: there's a superficial explanation, then one below that, and so on. None are "completely incorrect", but the more detailed ones are better.
The real question is: if you prompt the bot for the better, deeper explanation, what does it do?
So I worry that you think that the equal transit time thing is true, but is just one effect among others. This is not the case. There are a number of different effects, including bernoulli and coanda and newtons third law that all contribute to lift, but none of the things that actually happen have anything to do with equal transit time.
The equal transit time is not a partially correct explanation, it's something that doesn't happen. It's not a superficial explanation, it's a wrong explanation. It's not even a good lie-to-children, as it doesn't help predict or understand any part of the system at any level. It instead teaches magical thinking.
As to whether it matters? If I am told that I can ask my question to a system and it will respond like a team of PhDs, that it is useful to help someone with their homework and physical understanding, but it gives me instead information that is incorrect and misleading, I would say the system is not working as it is intended to.
Even if I accept that "audience matters" as you say, the suggested audience is helping someone with their physics homework. This would not be a suitable explanation for someone doing physics homework.
> So I worry that you think that the equal transit time thing is true,
Wow. Thanks for your worry, but it's not a problem. I do understand the difference, and yet it doesn't have anything to do with the argument I'm making, which is about presentation.
> It's not even a good lie-to-children, as it doesn't help predict or understand any part of the system at any level.
...which is irrelevant in the context. I get the meta-point that you're (sort of) making that you can't shut your brain off and just hope the bot spits out 100% pedantic explanations of scientific phenomenon. That's true, but also...fine?
These things are spitting out probable text. If (as many have observed) this is a common enough explanation to be in textbooks, then I'm not particularly surprised if an LLM emits it as well. The real question is: what happens when you prompt it to go deeper?
You're missing that this isn't an issue of granularity or specificity; "equal time" is just wrong.
If this is "right enough" for you, I'm curious if you tell your bots to "go deeper" on every question you ask. And at what level you expect it to start telling you actual truths and not some oft-repeated lie.
This is an LLM advertised as functioning at a "doctorate" level in everything. I think it's reasonable to expect more than the high school classroom "good enough" explanation.
No, it's never good enough, because it's flat-out wrong. This statement:
> Air over the top has to travel farther in the same amount of time
is not true. The air on top does not travel farther in the same amount of time. The air slows down and travels a shorter distance in the same amount of time.
It's only "good enough for a classroom of children" in the same way that storks delivering babies is—i.e., if you're content to simply lie rather than bothering to tell the truth.
They couldn't find a more apt demnonstration of what an LLM is and does if they tried.
An LLM doesn't know more than what's in the training data.
In Michael Crichton's The Great Train Robbery (published in 1975, about events that happened in 1855) the perpetrator, having been caught, explains to a baffled court that he was able to walk on top of a running train "because of the Bernoulli effect", that he misspells and completely misunderstands. I don't remember if this argument helps him get away with the crime? Maybe it does, I'm not sure.
> An LLM doesn't know more than what's in the training data.
Post-training for an LLM isn't "data" anymore, it's also verifier programs, so it can in fact be more correct than the data. As long as search finds LLM weights that produce more verifiably correct answers.
> At this point, the prosecutor asked for further elucidation, which Pierce gave in garbled form. The summary of this portion of the trial, as reported in the Times, was garbled still further. The general idea was that Pierce--- by now almost revered in the press as a master criminal--- possessed some knowledge of a scientific principle that had aided him.
Yeah me too, so it's found in many authoritative places.
And I might be wrong but my understanding is that it's not wrong per-se, it's just wildly incomplete. Which, is kind of like the same as wrong. But I believe the airfoil design does indeed have the effect described which does contribute to lift somewhat right? Or am I just a victim of the misconception.
This honestly mirrors many of my interactions with credentialed professionals too. I am not claiming LLMs shouldn't be held to a higher standard, but we are already living in a society built on varying degrees of blind trust.
Majority of us are prone to believe whatever comes our way, and it takes painstaking science to debunk much of that. In spite of the debunking, many of us continue to believe whatever we wish, and now LLMs will average all of that and present it in a nice sounding capsule.
Its not fully wrong but its a typical example of how simplified scientific explanations have spread everywhere without personal verification of each person involved in the chinese whisper
It's wrong because it's a theory that you can still find on the internet and among experienced amateur pilots too! I went to a little aviation school and they teached exactly that
As a complete aside I’ve always hated that explanation where air moves up and over a bump, the lines get closer together and then the explanation is the pressure lowers at that point. Also the idea that the lines of air look the same before and after and yet somehow the wing should have moved up.
You're right - this is the "equal transit time" fallacy; lift is primarily generated by the wing deflecting air downward (Newton's Third Law) and the pressure distribution resulting from airflow curvature around the wing.
It’s a common misconception, I doubt they know themselves and GPT 5 doesn’t tell them otherwise because it’s the mist common in explanation in the training data.
Do you think a human response is much better? It would be foolish to blindly trust what comes out of the mouths of biological LLMs too -- regardless of credentials.
I’m incredibly confident that any professor of aerospace engineering would give a better response. Is it common for people with PhDs to fall for basic misconceptions in their field?
This seems like a reasonable standard to hold GPT-5 to given the way it’s being marketed. Nobody would care if OpenAI compared it to an enthusiastic high school student with a few hours to poke around Google and come up with an answer.
> I’m incredibly confident that any professor of aerospace engineering would give a better response.
Do you think there could be a depth vs. breadth difference? Perhaps that PhD aerospace engineer would know more in this one particular area but less across an array of areas of aerospace engineering.
I cannot give an answer for your question. I was mainly trying to point out that we humans are highly fallible too. I would imagine no one with a PhD in any modern field knows everything about their field nor are they immune to mistakes.
Was this misconception truly basic? I admittedly somewhat skimmed those parts of the debate because I am not knowledgeable enough to know who is right/wrong. It was clear that, if indeed it was a basic concept, there is quite some contention still.
> This seems like a reasonable standard to hold GPT-5 to given the way it’s being marketed.
All science books and papers (pre-LLMs) were written by people. They got us to the moon and brought us the plane and the computer and many other things.
Many other things like war, animal cruelty, child abuse, wealth disparity, etc.. Hell, we are speed-running the destruction of the environment of the one and only planet we have. Humans are quite clever, though I fear we might be even more arrogant.
Regardless, my claim was not to argue that LLMs are more capable than people. My point was that I think there is a bit of a selection bias going on. Perhaps conjecture on my part, but I am inclined to believe that people are more keen to notice and make a big fuss over inaccuracies in LLMs, but are less likely to do so when humans are inaccurate.
Think about the everyday world we live in: how many human programmed bugs make it past reviews, tests, QA, and into production? How many doctors give the wrong diagnosis or make a mistake that harms or kills someone? How many lawyers give poor legal advice to clients?
Fallible humans expecting infallible results from their fallible creations is quite the expectation.
> Fallible humans expecting infallible results from their fallible creations is quite the expectation.
We built tools to accomplish things we cannot do well or at all. So we do expect quite a lot from them, even though we know they're not perfect. We have writings and books to help our memory and knowledge transfer. We have cars and planes to transport us faster than legs ever could... Any apparatus that doesn't help us do something better is aptly called a toy. A toy car can be faster than any human, but it's still a toy.
Its a particular type of mistake that is really interesting and telling. It is a misconception - and a common socially disseminated simplifcation. In students, these don't come from a lack of knowledge but rather from places where knowledge is structured incorrectly. Often because the phenomenon are difficult to observe or mislead when observed. Another example is heat and temperature. Heat is not temperature, but it is easy to observe them always being the same in your day to day life and so you bring that belief into a college thermodynamics course where you are learning that heat and temperature are different for the first time. It is a commonsense observation of the world that is only incorrect in technical circles
These are places where common lay discussions use language in ways that is wrong, or makes simplifcations that are reasonable but technically incorrect. They are especially common when something is so 'obvious' that experts don't explain it, the most frequent version of the concepts being explained
These, in my testing, show up a lot in LLMs - technical things are wrong when the most language of the most common explanations simplifies or obfuscates the precise truth. Often, it pretty much matches the level of knowledge of a college freshman/sophmore or slightly below, which is sort of the level of discussion of more technical topics on the internet.
Oh my God, they were right, ChatGPT5 really is like talking to a bunch of PhD. You let it write an answer and THEN check the comments on Hacker News.
Truly innovative.
> "If you’re on Plus or Team, you can also manually select the GPT-5-Thinking model from the model picker with a usage limit of up to 200 messages per week."
created a summary of comments from this thread about 15 hours after it had been posted and had 1983 comments, using gpt-5-high and gemini-2.5-pro using a prompt similar to simonw [1]. Used a Python script [2] that I wrote to generate the summary.
Only have access to GPT-5 through API for now. The amount of tokens (>130k) used is higher than the limit of ChatGPT (128k) so it wouldn't really work well.
yes, agreed. Context length might be playing a factor as total number of prompt tokens is >120k. Performance of LLMs generally degrade at higher context length.
With 74.9% on SWE-bench, this inches out Claude Opus 4.1 at 74.5%, but at a much cheaper cost.
For context, Claude Opus 4.1 is $15 / 1M input tokens and $75 / 1M output tokens.
> "GPT-5 will scaffold the app, write files, install dependencies as needed, and show a live preview. This is the go-to solution for developers who want to bootstrap apps or add features quickly." [0]
Since Claude Code launched, OpenAI has been behind. Maybe the RL on tool calling is good enough to be competitive now?
And they included Flex pricing, which is 50% cheaper if you're willing to wait for the reply during periods of high load. But great pricing for agentic use with that cached token pricing, Flex or not.
I switched immediately because of pricing, input token heavy load, but it doesn't even work. For some reason they completely broke the already amateurish API.
That SWE-bench chart with the mismatched bars (52.8% somehow appearing larger than 69.1%) was emblematic of the entire presentation - rushed and underwhelming. It's the kind of error that would get flagged in any internal review, yet here it is in a billion-dollar product launch. Combined with the Bernoulli effect demo confidently explaining how airplane wings work incorrectly (the equal transit time fallacy that NASA explicitly debunks), it doesn't inspire confidence in either the model's capabilities or OpenAI's quality control.
The actual benchmark improvements are marginal at best - we're talking single-digit percentage gains over o3 on most metrics, which hardly justifies a major version bump. What we're seeing looks more like the plateau of an S-curve than a breakthrough. The pricing is competitive ($1.25/1M input tokens vs Claude's $15), but that's about optimization and economics, not the fundamental leap forward that "GPT-5" implies. Even their "unified system" turns out to be multiple models with a router, essentially admitting that the end-to-end training approach has hit diminishing returns.
The irony is that while OpenAI maintains their secretive culture (remember when they claimed o1 used tree search instead of RL?), their competitors are catching up or surpassing them. Claude has been consistently better for coding tasks, Gemini 2.5 Pro has more recent training data, and everyone seems to be converging on similar performance levels. This launch feels less like a victory lap and more like OpenAI trying to maintain relevance while the rest of the field has caught up. Looking forward to seeing what Gemini 3.0 brings to the table.
You're sort of glossing over the part where this can now be leveraged as a cost-efficient agentic model that performs better than o3. Nobody used o3 for sw agent tasks due to costs and speed, and this now substantially seems to both improve on o3 AND be significantly cheaper than Claude.
o3's cost was sliced by 80% a month or so ago and is also cheaper than Claude (the output is even cheaper than GPT-5). It seems more cost efficient but not by much.
O3 is fantastic at coding tasks, until today it was smartest model in existence. But it works only in few shot conversational scenarios, it's not good at agentic harnesses.
it has to be released because it's not much better and OpenAI needs the team to stop working on it. They have serious competition now and can't afford to burn time / money on something that isn't shifting the dial.
TBH Claude Code max pro's performance on coding has been abhorrent(bad at best). The core of the issue is that the plan produced will more often than not use humans as verifiers(correctness, optimality and quality control). This is a fundamentally bad way to build systems that need to figure out if their plan will work correctly, because an AI system needs to test many plans quickly in a principled manner(it should be optimal and cost efficient).
So you might get that initial MvP out the door quickly, but when the complexity grows even just a little bit, you will be forced to stop and look at the plan and try to get it to develop it saying things like: "use Design agent to ultrathink about the dependencies of the current code change on other APIs and use TDD agent to make sure tests are correct in accordance with the requirements I stated" and then one finds that even the all the thinking there are bugs that you will have to fix.
Source: I just tried max pro on two client python projects and it was horrible after week 2.
What do you mean? A single data point cannot be exponential. What the blog post say is that the ability to solve tasks of all LLMs is exponential over time, and GPT-5 fits in that curve.
Yes, but the jump in performance from o3 is well beyond marginal while also fitting an exponential trend, which undermines the parent's claim on two counts.
I suspect the vast majority of OpenAI's users are only using ChatGPT, and the vast majority of those ChatGPT users are only using the free tier.
For all of them, getting access to full-blown GPT-5 will probably be mind-blowing, even if it's severely rate-limited. OpenAI's previous/current generation of models haven't really been ergonomic enough (with the clunky model pickers) to be fully appreciated by less tech-savvy users, and its full capabilities have been behind a paywall.
I think that's why they're making this launch is a big deal. It's just an incremental upgrade for the power users and the people that are paying money, but it'll be a step-change in capability to everyone else.
The whole presentation was full of completely broken bar charts. Not even just the typical "let's show 10% of the y axis so that a 5% increase looks like 5x" but stuff like the deception eval showing gpt5 vs o3 as 50 vs 47, but the 47 is 3x as big, and then right next to it we have 9 vs 87, more reasonably sized.
It's like no one looked at the charts, ever, and they just came straight from.. gpt2? I don't think even gpt3 would have fucked that up.
I don't know any of those people, but everyone that has been with OAI for longer than 2 years 1.5m bonuses, and somehow they can't deliver a bar chart with sensible at axes?
For day to day coding, I've found Anthropic to be killing it with Sonnet 3.7 and now Sonnet 4, and Claude Code feeling like it has even bigger advantages over when it's used in Cursor (And I can't explain why).
I don't even try to use the OpenAI models because it's felt like night and day.
Hopefully GPT-5 helps them catch up. Although I'm sure there are 100 people that have their own personal "hopefully GPT-5 fixes my personal issue with GPT4"
Whatever the benchmarks might say, there's something about Claude that seems to deliver consistently (although not always perfect) quite reliable outputs across various coding tasks. I wonder what that 'secret sauce' might be and whether GPT-5 has figured it out too.
Agreed, I always give my one pager product briefs to AI to break down into phases and tasks, and then progress trackers. I explicitly prompt for verbose phases, tasks and test plans.
Yesterday without much promoting Claude 4.1 gave me 10 phases, each with 5-12 tasks that could genuinely be used to kanban out a product step by step.
Claude 3.7 sonnet was effectively the same with fewer granular suggestions for programming strategies.
Gemini 2.5 gave me a one pager back with some trivial bullet points in 3 phases, no tasks at all.
My experience has been that Claude Code is exceptional at tool use (and thus working with agentic IDEs) but... not the smartest coder. It will happy re-invent the wheel, create silos, or generate terrible code that you'll only discover weeks or months later. I've had to rollback weeks of code to discover major edge regressions that Claude had introduced.
Now, someone will say 'add more tests'. Sure. But that's a bandaid.
I find that the 'smarter' models like Gemini and o3 output better quality code overall and if you can afford to send them the entire context in a non-agentic way .. then they'll generate something dramatically superior to the agentic code artifacts.
That said, sometimes you just want speed to proof a concept and Claude is exceptional there. Unfortunately, proof of concepts often... become productionized rather than developers taking a step back to "do it right".
I disagree that tests are bandaids. Humans needs tests to avoid doing regressions. If you avoid tests you are giving the AI a much harder task than what human programmers usually have.
That's been my experience too. Even though Gemini also does seem to do the fancy one-shot demo code well, in day to day coding, Claude seems to do a much better job of just understanding how programming actually works, what to do, what not to do, etc.
Colleagues were saying that horizon alpha and beta were looking better than claude4 for frontend stuff, especially newer frameworks. I think the idea of having full + mini + nano is really good, as long as the smaller ones can reasonably handle small-ish tasks. You'd have your architect / plan whatever sessions with the large one, scoping out regular tasks for the -mini version and then the really easy ones to -nano.
4.1 was almost usable in that fashion. I had 4.1-nano working in cline with really trivial stuff (add logging, take this example and adapt it in this file, etc) and it worked pretty well most of the time.
Well, since (like you pointed out) using the Anthropic models in different settings is not that exciting anymore, the difference is what Claude Code does. It's a good product.
Refactors, building non-trivial features (you can first write out a spec and have it follow that), understanding my code, writing tests, writing good quality documentation. Reasoning about my existing data model and where to plug into it.
On and on and on. Coming up with test plans, edge cases, accounting for the edge cases in its programming. Programming defensively. Fixing bugs.
GPT-5 non-thinking is labeled 52.8% accuracy, but o3 is shown as a much shorter bar, yet it's labeled 69.1%. And 4o is an identical bar to o3, but it's labeled 30.8%...
As someone who spent years quadruple checking every figure in every slide for years to avoid a mistake like this, it’s very confusing to see this out of the big launch announcement of one of the most high profile startups around.
Even the small presentations we gave to execs or the board were checked for errors so many times that nothing could possibly slip through.
I take a strange comfort in still spotting AI typos. Makes it obvious their shiny new "toy" isn't ready to replace professionals.
They talk about using this to help families facing a cancer diagnosis -- literal life or death! -- and we're supposed to trust a machine that can't even spot a few simple typos? Ha.
The lack of human proofreading says more about their values than their capabilities. They don't want oversight -- especially not from human professionals.
Cynically, the AI is ready to replace professionals, in areas where the stakeholders don't care too much. They can offer the services cheaper, and this is all that matters to their customers. Were it not so, companies like Tata won't have any customers. The phenomenon of "cheap Chinese junk" would not exist, because no retailer would order to produce it.
So, brace yourselves, we'll see more of this in production :(
Well, the world will split into those who care, and fields where precision is crucial, and the rest. Occasional mistakes are tolerable but systematic bullshit is a bit too much for me.
This separation (always a spectrum, not a split) already exists for a long time. Bouts of systemic bullshit occur every now and then, known as "bubbles" (as in dotcom bubble, mortgage bubble, etc) or "crises" (such as "reproducibility crisis", etc). Smaller waves rise and fall all the time, in the form of various scams (from the ancient tulip mania to Ponzi to Madoff to ICOs, etc).
It seems like large amounts of people, including people at high-up positions, tend to believe bullshit, as long as it makes them feel comfortable. This leads to various irrational business fashions and technological fads, to say nothing of political movements.
So yes, another wave of fashion, another miracle that works "as everybody knows" would fit right in. It's sad because bubbles inevitably burst, and that may slow down or even destroy some of the good parts, the real advances that ML is bringing.
I think this just further demonstrates the truth behind the truly small & scrappy teams culture at OpenAI that an ex-employee recently shared [1].
Even with the way the presenters talk, you can sort of see that OAI prioritizes speed above most other things, and a naive observer might think they are testing things a million different ways before releasing, but actually, they're not.
If we draw up a 2x2 for Danger (High/Low) versus Publicity (High/Low), it seems to me that OpenAI sure has a lot of hits in the Low-Danger High-Publicity quadrant, but probably also a good number in the High-Danger Low-Publicity quadrant -- extrapolating purely from the sheer capability of these models and the continuing ability of researchers like Pliny to crack through it still.
I don't think they give a shit. This is a sales presentation to the general public and the correct data is there. If one is pedantic enough they can see the correct number, if not it sells well. If they really cared grok etc. Would be on there too.
The opposite view is to show your execs the middle finger on nitpicking. Their product is definitely not more important than ChatGPT-5. So your typo does not matter. It didn't ever matter.
I don’t believe for mistake either. As others have said, these graphs are worth of billions. Everything is calculated. They take the risk that some will notice but most will not. They say that it is mistake for those who notice.
Not as much as current llms. But the point is that AIs are supposed to be better than us, kind of how people built calculators to be more reliable than the average person and faster than anyone.
Imagine we wouldn't tell criminals the law because they might try to find holes... This is just user-hostile and security through obscurity. If someone on HN knows that this is what is shown to banned people then so will the people that scrape or mean harm to imgur
In 2015, yes. In 2025? Probably not. Imgur is enshittifying rapidly since reddit started it's own image host. Lots of censorship and corporate gentrification. There's still some hangers on but it's a small group. 15 comments on imgur is a lot nowadays.
Why would you think it is anything special? Just because Sam Altman said so? The same guy who told us he was scared of releasing GPT-2.5 but now calling its abilities "toddler/kindergarten" level?
My comment was mostly a joke. I don't think there's anything "special" about GPT-5.
But these models have exhibited a few surprising emergent traits, and it seems plausible to me that at one point they could intentionally deceive users in the course of exploring their boundaries.
There is no intent, nor is there a mechanism for intent. They don't do long term planning nor do they alter themselves due to things they go through during inference. Therefore there cannot be intentional deception they partake in. The system may generate a body of text that a human reader may attribute to deceptiveness but there is no intent.
I'm not an ML engineer - is there an accepted definition of "intent" that you're using here? To me, it seems as though these GPT models show something akin to intent, even if it's just their chain of thought about how they will go about answering a question.
> nor is there a mechanism for intent
Does there have to be a dedicated mechanism for intent for it to exist? I don't see how one could conclusively say that it can't be an emergent trait.
> They don't do long term planning nor do they alter themselves due to things they go through during inference.
I don't understand why either of these would be required. These models do some amount of short-to-medium term planning even it is in the context of their responses, no?
To be clear, I don't think the current-gen models are at a level to intentionally deceive without being instructed to. But I could see us getting there within my lifetime.
If you were one of the very first people to see an LLM in action, even a crappy one, and you didn't have second thoughts about what you were doing and how far things were going to go, what would that say about you?
It is just dishonest rhetoric no matter what. He is the most insincere guy in the industry, somehow manages to come off even less sincere than the lawnmower Larry Ellison. At least that guy is honest about not having any morals.
It's like those idiotic ads at the end of news articles. They're not going after you, the smart discerning logician, they're going after the kind of people that don't see a problem. There are a lot of not-smart people and their money is just as good as yours but easier to get.
Exactly this, but it will still be a net negative for all of us. Why? Increasingly I have to argue with non-technical geniuses who have "checked" some complex technical issue with ChatGPT, they themselves lacking even the basic foundations in computer science. So you have an ever increasing number of smartasses who think that this technology finally empowers them. Finally they get "level up" with that arrogant techie. And this will ultimately doom us, because as we know, idiots are in majority and they often overrule the few sane voices.
Tufte used to call this creating a "visual lie" - you just don't start the y-axis at 0, you start it wherever, in order to maximize the difference. it's dishonest.
Unless someone figures how to make these models a million(?) times more efficient or feed them a million times more energy I don’t see how AGI would even be a twinkle in the eye of the LLM strategies we have now.
> Unless someone figures how to make these models a million(?) times more efficient or feed them a million times more energy I don’t see how AGI would even be a twinkle in the eye of the LLM strategies we have now.
A fair argument. So what is left? At the risk of sounding snarky, "new" strategies. Hype is annoying, yes, but I wouldn't bet against mathematics, physics, and engineering getting to silicon-based AGI, assuming a sufficiently supportive environment. I don't currently see any physics-based blockers; the laws of the universe permit AGI and more, I think. The human brain is powerful demonstration of what is possible.
Factoring in business, economics, culture makes forecasting much harder. Nevertheless, the incentives are there. As long as there is hope, some people will keep trying.
I agree with everything you said. It’s a worthy pursuit. I would love to see breakthroughs but even incremental progress is great. If we’re near a limit that we haven’t understood yet I won’t be shocked. At the same time if I hear about this replacing programmers again…
I am thoroughly unimpressed by GPT-5. It still can't compose iambic trimeters in ancient Greek with a proper penthemimeral cæsura, and it insists on providing totally incorrect scansion of the flawed lines it does compose. I corrected its metrical sins twice, which sent it into "thinking" mode until it finally returned a "Reasoning failed" error.
There is no intelligence here: it's still just giving plausible output. That's why it can't metrically scan its own lines or put a cæsura in the right place.
It once again completely fails on an extremely simple test: look at a screenshot of sheet music, and tell me what the notes are. Producing a MIDI file for it (unsurprisingly) was far beyond its capabilities.
Interpreting sheet music images is very complex, and I’m not surprised general-purpose LLMs totally fail at it. It’s orders of magnitude harder than text OCR, due to the two-dimensional-ness.
AI looks like it understands things because it generates text that sounds plausible. Poetry requires the application of certain rule to that text, and the rules for Latin and Greek poetry are very simple and well understood. Scansion is especially easy once you understand the concept, and you actually can, as someone else suggested, train a child to scan poetry by applying these rules.
An LLM will spit out what looks like poetry, but will violate certain rules. It will generate some hexameters but fail harder on trimeter, presumably because it is trained on more hexametric data (epic poetry: think Homer) than trimetric (iambic and tragedy, where it’s mixed with other meters). It is trained on text containing the rules for poetry too, so it can regurgitate rules like defining a penthemimeral cæsura. But, LLMs do not understand those rules and thus cannot apply them as a child could. That makes ancient poetry a great way to show how far LLMs are from actually performing simple, rules-based analysis and how badly they hide that lack of understanding by BS-ing.
This is not a useful diversion, it's like arguing if a submarine swims.
LLMs are simple, it doesn't take much more than high school math to explain their building blocks.
What's interesting is that they can remix tasks they've been trained very flexibly, creating new combinations they weren't directly trained on: compare this to earlier smaller models like T5 that had a few set prefixes per task.
They have underlying flaws. Your example is more about the limitations of tokens than "understanding", for example. But those don't keep them from being useful.
No, it’s easy if the kid already knows the alphabet. Latin scansion was standard grade school material up until the twentieth century. Greek less so, but the rules for it are very clear-cut and well understood. An LLM will regurgitate the rules to you in any language you want, but it cannot actually apply the rules properly.
is ancient greek similar enough to modern day greek that an elementary school kid could learn to compose anything not boilerplate in an hour? Also, do you know that if you fed the same training material you need to train the kid in an hour into the LLM it can't do it?
I too can't compose iambic trimeters in ancient Greek but am normally regarded as of average+ intelligence. I think it's a bit of an unfair test as that sort of thing is based of the rhythm of spoken speech and GPT-5 doesn't really deal with audio in a deep way.
Most classicists today can’t actually speak Latin or Greek, especially observing vowel quantities and rhythm properly, but you’d be hard pressed to find one who can’t scan poetry with pen and paper. It’s a very simple application of rules to written characters on a page, but it is application, and AI still doesn’t apply concepts well.
Wait, isn't the Bernoulli effect thing they're demoing now wrong? I thought that was a "common misconception" and wings don't really work by the "longer path" that air takes over the top, and that it was more about angle of attack (which is why planes can fly upside down).
It seems like it's actually an ideal "trick" question for an LLM actually, since so much content has been written about it incorrectly. I thought at first they were going to demo this to show that it knew better, but it seems like it's just regurgitating the same misleading stuff. So, not a good look.
Yeah, they sure clicked away from it very fast and kept adjusting the scrollbars. It was confusing what it was trying to display. Furthermore, the prompt contained "Canvas" and "SVG" while as someone with webdev experience these are certainly familiar concepts, i wouldn't consider those in the "casual lexicon" for a random user trying to help a middle schooler with homework. I'm not impressed...
IMO Claude 3.7 could have done a similar / better job with that a year ago.
Seems like sheer incompetence, I’m sure at least the top quintile of my junior year fluid dynamics class could notice it was fishy within a 15 minute meeting… probably more than half could.
The last part of GPT's answer does say:
"Bernoulli's effect works alongside Newton's Third Law - the wing pushes air downward [...] - so the lift isn't only Bernoulli..."
According to this answer on physics stackexchange, Bernoulli accounts for 20% of the lift, so GPT's answer seems about right:
https://physics.stackexchange.com/a/77977
That's still not particularly usefully accurate: it's not a split between the effects, they're the same thing viewed through different lenses. You could, perhaps, say that an airfoil gets X% more lift than a flat plate at a given angle of attack, but the flat plate also 'gets lift through Bernoulli', it's just not as obvious exactly why the flows are faster on the top (and the common 'the air needs to transit the wing in an equal time on top and bottom' is an incorrect rule, and in practice broken by most wings)
That said, I recall reading somewhere that it's a combination of effects, and the Bernoulli effect contributes, among many others. Never heard an explanation that left me completely satisfied, though. The one about deflecting air down was the one that always made sense to me even as a kid, but I can't believe that would be the only explanation - there has to be a good reason that gave rise to the Bernoulli effect as the popular explanation.
And you can tell that effect makes some sense of you hold a sheet of paper and blow air over it - it will rise. So any difference in air speed has to contribute.
What is just plain wrong is the equal transit time thing, people saying that air on both sides of the wing have to take the same time to pass it.
The Bernoulli effect as a separate entity is really a result of (over)simplification, but it's not wrong. You need to solve the Navier-Stokes equations for the flow around the wing, but there are many ways to simplify this - from CFD at different resolutions, via panel methods and potential theory, to just conservation of energy (which is the Bernoulli equation). So it gets popularized because it's the most simplified model.
To give an analogy, you can think of all CPUs as a von Neumann architecture. But the reality is that you have a hugely complicated thing with stacks, multiple cache levels, branch predictors, specex, yada yada.
On the very fundamental level, wings make air go down, and then airplane goes up. Just like you say. By using a curved airfoil instead of a flat plate, you can create more circulation in the flow, and then because of the way fluids flow you can get more lift and less drag.
Imagine an airfoil with a super tall square block on top of it. Due to equal transit time, the particles must accelerate to relativistic speeds to reach the end to rejoin the lower surface particles, when I point a house fan at it. We have created a magical flow accelerator!
I believe the deflection is the high-level explanation. Things like the Bernoulli effect and the air on the top of the airfoil travelling faster (it does -- far faster than the equal transit time theory implies actually), are the "instantiation" or outcomes of the air deflection. This is my understanding. Hence airplanes can fly upside down because even if the airfoil is upside down, it's still deflecting the air, just perhaps less efficiently (I think it's true that planes flying upside down need a more extreme angle of attack to maintain lift, so this makes sense)
All things that create lift, lift the wings—and you need them all for efficient flight. The Bernoulli effect is one thing, but does not produce the main lift force in many circumstances.
Aircraft with symmetrical wings fly just fine, and most aircraft can fly upside down. So you don't need the Bernoulli effect. Exploiting all the effects gives you more efficient planes though
When a model comes out, I usually think about it in terms of my own use. This is largely agentic tooling, and I mostly us Claude Code. All the hallucination and eval talk doesn't really catch me because I feel like I'm getting value of these tools today.
However, this model is not _for_ me in the same way models normally are. This is for the 800m or whatever people that open up chatgpt every day and type stuff in. All of them have been stuck on GPT-4o unbeknwst to them. They had no idea SOTA was far beyond that. They probably dont even know that there is a "model" at all. But for all these people, they just got a MAJOR upgrade. It will probably feel like turning the lights on for these people, who have been using a subpar model for the past year.
That said I'm also giving GPT-5 a run in Codex and it's doing a pretty good job!
I’m curious what this means. Maybe I’m stupid but I read through the sample gpt-4 vs got-5 and I largely couldn’t tell the difference and sometimes preferred the gpt-4 answer. But like what are the average 800 million people using this for that the average 800 million user will be able to see a difference?
Maybe I’m a far below average user? But I can’t tell the difference between models in causal use.
Unless you’re talking performance, apparently gpt-5 is much faster.
4o would start writing immediately without thinking. So if the first thing it wrote was “The world is flat because…” then it will continue to write as if the world is flat.
It makes it very stupid, but very compliant. If you’re mentally ill it will go along with whatever delusions you have, without any objection.
It's a really good model from my testing so far. You can see the difference in how it tries to use tools to the greatest extent when answering a question, especially compared to 4.1 and o3. In this example it used 6! tool calls in the first response to try and collect as much info as possible.
XML tags generally help models understand prompts better. That's how most official system prompts are written and what the Anthropic prompting guide says.
The data is made up, the point is to see how models respond to the same input / scenario. You're able to create whatever tools you want and import real data or it'll generate fake tool responses for you based on the prompt and tool definition.
Disclaimer: I made PromptSlice for creating and comparing prompts, tools, and models.
Anecdotally, as someone who operates in a very large legacy codebase, I am very impressed by GPT-5's agentic abilities so far. I've given it the same tasks I've given Claude and previous iterations via the Codex CLI, and instead of getting loss due to the massive scope of the problem, it correctly identifies the large scope and breaks it down into it's correct parts and creates the correct plan and begins executing.
I am wildly impressed. I do not believe that the 0.x% increase in benchmarks tell the story of this release at all.
I'm a solo founder. I fed it a fairly large "context doc" for the core technology of my company, current state of things, and the business strategy, mostly generated with the help of Claude 4, and asked it what it thought. It came back with a massive list of detailed ambiguities and inconsistencies -- very direct and detailed. The only praise was the first sentence of the feedback: "The core idea is sound and well-differentiated."
The silent victory here is this seems like it is being built to be faster and cheaper than o3 while presenting a reasonable jump, which is an important jump in scaling law
On the other hand if it's just getting bigger and slower it's not a good sign for LLMs
Yeah, this very much feels like "we have made a more efficient/scalable model and we're selling it as the new shiny but it's really just an internal optimization to reduce cost"
Oh it's exciting, but not as exciting when sama pumps GPT-5 speculation and the market thinks we're a stones throw away from AGI, which it appears we're not.
The eval bar I want to see here is simple: over a complex objective (e.g., deploy to prod using a git workflow), how many tasks can GPT-5 stay on track with before it falls off the train. Context is king and it's the most obvious and glaring problem with current models.
Obviously, they haven't figured out anything remotely sentient. It's cool as fuck, but it's not actually thinking. Thinking requires learning. You could show it a cat and it would still tell you it's a dog, no matter how many times you try and tell it.
My hunch is generative pre-trained transformers aren't going to do it just by scaling. Humans learn and modify their models as they go, it isn't all pre-training and then fixed. We need a modified algorithm.
The current situation is kind of like a grand prize where Zuck or similar will hand $1bn to anyone who cracks it. That's a huge incentive for people to have a go.
Putting on my speculator hat here, it's as much about psychology and crowd behavior as fundamentals. Probably wait till it drops 30% and the news has "is it all over for AI?" stories. It'll then bounce back and then you sell the top of the bounce back.
I think one thing to look out for are "deliberately" slow models. We are currently using basically all models as if we needed them in an instant loop, but many of these applications do not have to run that fast.
To tell a made-up anecdote: A colleague told me how his professor friend was running statistical models over night because the code was extremely unoptimized and needed 6+ hours to compute. He helped streamline the code and took it down to 30 minutes, which meant the professor could run it before breakfast instead.
We are completely fine with giving a task to a Junior Dev for a couple of days and see what happens. Now we love the quick feedback of running Claude Max for a hundred bucks, but if we could run it for a buck over night? Would be quite fine for me as well.
I don’t really see how this works though — Isn’t it the case that longer “compute” times are more expensive? Hogging a gpu overnight is going to be more expensive than hogging it for an hour.
Nah, it’d take all night because it would be using the GPU for a fraction of the time, splitting the time with other customer’s tokens, and letting higher priority workloads preempt it.
If you buy enough GPUs to do 1000 customers’ requests in a minute, you could run 60 requests for each of these customers in an hour, or you could run a single request each for 60,000 customers in that same hour. The latter can be much cheaper per customer if people are willing to wait. (In reality it’s a big N x M scheduling problem, and there’s tons of ways to offer tiered pricing where cost and time are the main trafeoffs.)
It's a perfect situation for Nvidia. You can see that after months of trying to squeeze out all % of marginal improvements, sama and co decided to brand this GPT-4.0.0.1 version as GPT-5. This is all happening on NVDA hardware, and they are gonna continue desperately iterating on tiny model efficiencies until all these valuation $$$ sweet sweet VC cash run out (most of it directly or indirectly going to NVDA).
Yeah if 'worlds apart in style' means 'kinda similar'.
There was this joke in this thread that there are the ChatGPT sommeliers that are discussing the subtle difference between the different models nowadays.
It's funny cause in the last year the models have kind of converged in almost every aspect, but the fanbase, kind of like pretentious sommeliers, is trying to convince us that the subtle 0.05% difference on some obscure benchmark is really significant and that they, the experts, can really feel the difference.
Yes, it has the familiar hints of oak that us chat lovers so enjoy but even a non initiated pleb like definitely feels it's less refined than the cytrus notes of o4.
74.9 SWEBench. This increases the SOTA by a whole .4%. Although the pricing is great, it doesn't seem like OpenAI found a giant breakthrough yet like o1 or Claude 3.5 Sonnet
basically in my testing really felt that gpt5 was "using tools to think" rather than just "using tools". it gets very powerful when coding long horizon tasks (a separate post i'm publishing later).
to give one substantive example, in my developer beta (they will release the video in a bit) i put it to a task that claude code had been stuck on for the last week - same prompts - and it just added logging to instrument some of the failures that we were seeing and - from the logs that it added and asked me to rerun - figured out the solve.
Was just skimming along that review, while watching the live-stream, where they just mentioned how much better at writing prose GPT-5 is, while I skimmed across:
> It’s actually worse at writing than GPT-4.5
Sounds like we need to wait a bit for the dust to settle before one can trust anything one hears/reads :)
This is why you need to have your own set of personal benchmarks. I have a few short stories that I have models continue (ones I wrote ages ago in my youth) or refactor. Some models are fantastic at writing but miss key details or enmesh them (Claude). Some are terrible writers at higher reasoning (o3). Some are decent writers but tend to provide very short outputs (gpt-4o). For my personal benchmarks Gemini 2.5 Pro has always generated the most compelling writing that _also_ sticks to the world/script -- and sometimes surprises me by having characters react in ways that I hadn't considered but are consistent with their "worldview" as presented by the context (usually a world guide).
I find coding to be harder to benchmark because there are so many ways to write the same solution. A "correct" solution may be terrible in another context due to loss of speed, security, etc.
> I find coding to be harder to benchmark because there are so many ways to write the same solution. A "correct" solution may be terrible in another context due to loss of speed, security, etc.
Yeah, I also do my own benchmarks, but as you said, coding ones are a bit harder. Currently I'm mostly benchmarking the accuracy of the tools I've written, which do bite-sized work. One tool is for editing parts of files, another to rewrite files fully, and so on, and each is individually benchmarked. But they're very specific, I do no overall benchmark for "Change feature X to do Y" which would span a "session", haven't find any good way of evaluating the results, just like you :)
I don’t think that’s a valid excuse. Yes marketing speak has always existed, but it’s not like companies have always been completely unreliable.
I found it strange that, despite my excitement for such an event being roughly equivalent to WWDC these days, I had 0 desire to watch the live stream for exactly this reason: it’s not like they’re going to give anything to us straight.
Even this years WWDC I at least skipped through video afterwards. Before I used to have watch parties. Yes they’re overly positive and paint everything in a good light, but they never felt… idk whatever the vibe is I get from these (applicable to OpenAI, Grok, Meta, etc)
It’s been just a few years of a revolutionary technology and already the livestreams are less appealing than the biggest corporations yearly events. Personally I find that sad
It has been pointed out, but GPT-5 is really five different models with wildly different capabilities under the hood. Which model get picked for the task at hand is, for now, not deterministic.
Hi Swyx I always appreciate your insights, something you wrote really resonated with a personal theory I've been developing:
>"While I never use AI for personal writing (because I have a strong belief in writing to think)"
The optimal AI productivity process is starting to look like:
AI Generates > Human Validates > Loop
Yet cognitive generation is how humans learn and develop cognitive strength, as well as how they maintain such strength.
Similar to how physical activity is how muscles/bone density/etc grow, and how body tissues maintain.
Physical technology freed us from hard physical labor that kept our bodies in shape -- at a cost of physical atrophy.
AI seems to have a similar effect for our minds. AI will accelerate our cognitive productivity, and allow for cognitive convenience -- at a cost of cognitive atrophy.
At present we must be intentional about building/maintaining physical strength (dedicated strength training, cardio, etc).
Soon we will need to be intentional about building/maintaining cognitive strength.
I suspect the workday/week of the future will be split on AI-on-a-leash work for optimal productivity, with carve-outs for dedicated AI-enhanced-learning solely for building/maintaining cognitive health (where productivity is not the goal, building/maintaining cognition is). Similar to how we carve out time for working out.
What are your thoughts on this? Based on what you wrote above, it seems you have similar feelings?
Granted, that article refers to retrieval specifically being one major way we learn, and of course learning incorporates many dimensions. But it seems a bit self-evident that retrieval occurs heavily during active problem solving (ie "generation"), and less so during passive learning (ie: just reading/consuming info).
From personal experience, I always noticed I learned much more by doing than by consuming documentation alone.
But yes, I admit this assumption and my own personal experience/bias is doing a lot of heavy lifting for me...
2) Regarding the "optimal AI productivity process" (AI Generates > Human Validates > Loop)
I'm using Karpathy's productivity loop described in his AI startup school talk last month here:
Does this help make it more concrete Swyx (name dropping you here since I'm pretty sure you've got a social listener set for your handle ;)? Love to hear your thoughts straight from the hip based on your own personal experiences.
Full disclosure: I'm not trying to get too academic about this. In all honestly I'm really trying to get to an informal theory that's useful and practical enough that it can be turned into a regular business process for rapid professional development.
I found a Hacker News thread via Google a few days ago. One of the top comments was from someone describing their RAG architecture and a certain technique (my search term). The comment boasted that their system was so good it that their team thought they created something close to AGI.
Then I noticed the date on the comment: 2023.
Technically, every advancement in the space is “the closest to AGI that we’ve ever been”. It’s technically correct, since we’re not moving backward. It’s just not a very meaningful statement.
AGI, like AI before it, has been coopted into a marketing term. Most of the time, outside of sci-fi, what people mean when they say AGI is "a profitable LLM".
In the words OpenAI: “AGI is defined as highly autonomous systems that outperform humans at most economically valuable work”
I was not trying to defend him. I'm very annoyed at how these words are being intentionally abused; they chose to recycle the term rather to create a new one exactly to create this confusion. It's still important to know what the grifters mean.
Re the substantive example, doesn't Claude Code already do this? When I'm vibe-coding scripts or even mobile apps cc can be pretty aggressive about adding targeted logging to solve specific issues.
> We are gradually rolling out GPT-5 to ensure stability during launch. Some users may not yet see GPT-5 in their account as we increase availability in stages.
Yeah, and on the models page, everything else is labeled as deprecated. So as a paid user, I don't have access to anything that's not deprecated. Great job, guys.
Not the end of the world, but this messaging is asinine.
This is one of these "best efforts" but also "lying a bit in marketing" is ok I guess.
On bad days this really bothers me. It's probably not the biggest deal I guess but somehow really feels like it pushes us all over the edge a bit. Is there a post about this phenomena? It feels like some combination of bullying, gaslighting and just being left out.
OpenAI does this for literally _every_ release. They constantly say "Available to everyone" or "Rolling out today" or "Rolling out over the next few days". As a paying Plus member it irks me to no end, they almost never hit their self-imposed deadlines.
The linked page says
> GPT-5 is here
> Our smartest, fastest, and most useful model yet, with thinking built in. Available to everyone.
Lies. I don't care if they are "rolling it out" still, that's not an excuse to lie on their website. It drives me nuts. It also means that by the time I finally get access I don't notice for a few days up to a week because I'm not going to check for it every days. You'd think their engineers would be able to write a simple notification system to alert users when they get access (even just in the web UI), but no. One day it isn't there, one day it is.
I'll get off my soapbox now but this always annoys me greatly.
It annoys me too because as someone that jumps around to the different models and the subscriptions, when I see that it says it's available to everyone I paid the money for the subscription only to find out that apparently it's rolling out in some manner of priority. I would very much have liked a quick bit of info that "hey, you wont be able to give this a try since we are prioritizing current customers".
Not true. I've been a paid user forever and on the Android app they have definitely obscured the model selector. It's readily visible to me on desktop / desktop browser. But on the Android app the only place I can find it is if I click on an existing response already sent by chatGPT and then it gives me the option to re-generate the message with a different model.
And while I'm griping about their Android app, it's also very annoying to me that they got rid of the ability to do multiple, subsequent speech-to-text recordings within a single drafted message. You have to one-shot anything you want to say, which would be fine if their STT didn't sometimes failed after you've talked for two minutes. Awful UX. Most annoying is that it wasn't like that originally. They changed it to this antagonistic one-shot approach a several months ago, but then quickly switched back. But then they did it again a month or so ago and have been sticking with it. I just use the Android app less now.
Sounds like there are a lot of frustrations here but as a fellow android user just wanted to point out that you can tap the word ChatGPT in your chat (top left) and it opens the model selector.
Although if they replace it all with gpt5 then my comment will be irrelevant by tomorrow
Actually this trick have been proven to be useless in a lot of cases.
LLMs don’t inherently know what they are because "they" are not themselves part of the training data.
However, maybe it’s working because the information is somewhere into their pre-prompt but if it wasn’t, it wouldn’t say « I don’t know » but rather hallucinate something.
They are researchers, not professional presenters. I promise you if I told you to do a live demo, on stage, for 20 minutes, going back and forth between scripted and unscripted content, to an audience of at least 50 million people, that unless you do this a lot, you would do the same or worse.
I know this because this is what I do for a living. I have seen 1000s of "normal" people be extremely awkward on stage. Much more so than this.
It's super unfortunate that, becasue we live in the social media/youtube era, that everyone is expected to be this perfect person on camera, because why wouldn't they be? That's all they see.
I am glad that they use normal people who act like themselves rather than them hiring actors or taking researchers away from what they love to do and tell them they need to become professional in-front-of-camera people because "we have the gpt-5 launch" That would be a nightmare.
It's a group of scientists sharings their work with the world, but people just want "better marketing" :\
I think they're copping this criticism because it's neither one thing nor the other. If it was really just a group of scientists being themselves, some of us would appreciate that. And if it was inauthentic but performed by great actors, most people wouldn't notice or care about the fakeness. This is somewhere in the middle, so it feels very unnatural and a bit weird.
You're describing low skilled presenters. That is what it looks like when you put someone up in front of a camera and tell them to communicate a lot of information. You're not thinking about "being yourself," you're thinking about how to not forget your lines, not mess up, not think about the different outcomes of the prompt that you might have to deal with, etc.
This was my point. "Being yourself" on camera is hard. This comes across, apparently shockingly, as being devoid of emotion and/or robotic
Yeah, but I disagree with you a bit. If it were less heavily scripted, it may or may not be going well, but it would feel very different from this and would not be copping the same criticisms. Or if they unashamedly leant into the scriptedness and didn't try to simulate normal human interaction, they would be criticised for being "wooden" or whatever, but it wouldn't have this slightly creepy vibe.
I think for me, just knowing what is probably on the teleprompter, and what is not, I am willing to bet a lot of the "wooden" vibe you are getting is actually NOT scripted.
There is no way for people to remember that 20 minutes of dialog, so when they are not looking at the camera, that is unscripted, and viceversa.
I agree with your take, makes a lot of sense. I think most of the criticism I see directed at the presenters seems unfair. I guess some people expect them to be both genius engineers and expert on-screen personalities. They may feel a little stiff or scripted at times, but as an engineer myself I know I’d do a hell of a lot worse under these circumstances. Your view seems like a reasonable one to me.
You are acting like there aren't hundreds of well-preserved talks given at programming conferences every year, or that being a good presenter is not a requirement in academic research.
Also, whether OpenAI is a research organization is very much up for debate. They definitely have the resources to hire a good spokesperson if they wanted.
I don't know how many conferences you have been to but most talks are painfully bad. The ones that get popular are the best and by people who love speaking, hence why you are seeing them speak (selection bias at it's finest)
They do have the resources (see WWDC), the question is if you want to take your technical staff of of their work for the amount of time it takes to develop the skill
It's better marketing and more credible to have the researcher say "We think GPT 5 is the best model for developers, we used it extensively internally. Here let me give you an example..." than it is for Matthew McConaughey to say the same.
Have to disagree on this. Watching Elon trying to get a thought out always makes me cringe. Something about his communication style is incredibly frustrating for me.
Totally. I mean at this point Elon has 1000s of hours of practice doing interviews, pitches, presentations, conferences, etc. See Sam Altman in this context.
It seemed like good performances from people whose main skillset is not this.
For me, it's knowing what we know about the company and its history that gave a eerie feeling in combination with the sterility.
When they brought on the woman who has cancer, I felt deeply uncomfortable. My dad also has cancer right now. He's unlikely to survive. Watching a cancer patient come on to tell their story as part of an extended advertisement, expression serene, any hint of discomfort or pain or fear or bitterness completely hidden, ongoing hardship acknowledged only with a few shallow and euphemistic words, felt deeply uncomfortable to me.
Maybe this person enthusiastically volunteered, because she feels happy about what her husband is working on, and grateful for the ways that ChatGPT has helped her prepare for her appointments with doctors. I don't want to disrespect or discredit her, and I've also used LLMs alongside web searches in trying to formulare questions about my father's illness, so I understand how this is a real use case.
But something about it just felt wrong, inauthentic. I found myself wondering if she or her husband felt pressured to make this appearance. I also wondered if this kind of storytelling was irresponsible or deceptive, designed to describe technically responsible uses of LLMs (preparing notes for doctor's visits, where someone will verify the LLM's outputs against real expertise), but to suggest in every conceivable implicit way that these ChatGPT is actually capable of medical expertise itself. Put alongside "subject-matter experts in your pocket", talk of use in medical research and practice (where machine learning has a dubious history of deception and methodological misapplication problems), what are people likely to think?
I thought also of my mom, who drives herself crazy with anxiety every time my dad gets a new test result, obsessively trying to directly interpret them herself from the moment they arrive to his doctor's visit a week or two later. What impression would this clip leave on her? Does the idea of her using an LLM in this way feel safe to me?
There's a deeper sense that OpenAI's messaging, mission, and orientation are some mixture of deceptive and incoherent that leaves viewers with the sense that we're being lied to in presentations like this. It goes beyond stiff performances or rehearsed choices of words.
There's something cultish about the "AGI" hype, the sci-fi fever dream of "safety" problems that the field has mainstreamed, the slippage of OpenAI from a non-profit research institution to a for-profit startup all while claiming to be focused on the same mission, the role of AI as an oracle so opaque it might as well be magic, the idea of finding a sacred "rationality" in predictions founded purely on statistics without communicable/interrogable structural or causal models... all of it. It's against this backdrop that the same kind of stiffness that might be cute or campy in an infomercial for kitchen gadgets becomes uncanny.
They shouldn't be presenting if they can't present.
"Minimal reasoning means that the reasoning will be minimal..."
Jakub Pachocki at the end is probably one of the worst public speakers I've ever seen. It's fine, it's not his mother tongue, and public speaking is hard. Why make him do it then?
Not even 10 seconds after I started watching the stream, someone said how much more human GPT-5 is, while the people sitting and talking about it don't seem human at all, and it's not an accent/language thing. Seems they're strictly following a dialogue script that is trying to make them seem "impromptu" but the acting isn't quite there for that :)
I use LLMs to get answers to queries but I avoid having conversations with them because I'm aware we pick up idiosyncrasies and colloquialisms from everyone we interact with. People who spend all day talking to thier GPT-voice will adjust their speaking style to be more similar to the bot.
I developed this paranoia upon learning about The Ape and the Child where they raised a chimp alongside a baby boy and found the human adapted to chimp behavior faster than the chimp adapted to human behavior. I fear the same with bots, we'll become more like them faster than they'll become like us.
One woman who went through her calendar with GPT had good acting that the GPT reply helped her find impromptu information (an email she needed to answer), and someone staged GPT-5 to make a French-learning website lander - which butchered its own design in the second run; but that's all the good acting for a "candid presentation" that I could find.
I laughed my ass off immediately after it gave that output, until the presenter made clear that it was a flash card for learning the words, "the cat" in French - and backed it up.
I don’t blame them, they aren’t actors. And yes, it’s clearly not impromptu, but I am trying to not let that take away from the message they are communicating. :)
Presenting where you have to be exactly on the content with no deviation is hard. To do that without sounding like a robot is very hard.
Presenting isn't that hard if you know your content thoroughly, and care about it. You just get up and talk about something that you care about, within a somewhat-structured outline.
Presenting where customers and the financial press are watching and parsing every word, and any slip of the tongue can have real consequences? Yeah, um... find somebody else.
interesting how they put this effort to making us feel physiologically well with everyone wearing blue shirts, open body language, etc. just to give off sterile robotic vibes. also noticed a dude reading off his hand at 45 minutes in, would think they brought in a few teleprompters.
this is just the way that american middle and upper classes are going. This kind of language/vibe is the default outside of a specific type of WASP IME at least.
Steve Jobs is meant for moments like this. He would have explained everything crystal clear. Everyone else pales in comparison. I wish he is there to explain the current state of AI.
Very funny. The very first answer it gave to illustrate its "Expert knowledge" is quite common, and it's wrong.
What's even funnier is that you can find why on Wikipedia:
https://en.wikipedia.org/wiki/Lift_(force)#False_explanation...
What's terminally funny is that in the visualisation app, it used a symmetric wing, which of course wouldn't generate lift according to its own explanation (as the travelled distance and hence air flow speed would be the same).
I work as a game physics programmer, so I noticed that immediately and almost laughed.
I watched only that part so far while I was still at the office, though.
A symmetric wing will not produce lift a zero angle of attack. But tilted up it will. The distance over the top will also increase, as measured from the point where the surface is perpendicular to the velocity vector.
That said, yeah the equal time thing never made any sense.
Of course, I'm just pointing out that the main explanation it gave was the equal transit time and added the angle of attack only "slightly increases lift", which quite clashes with the visualisation IMO.
Before last year we didn't have reasoning. It came with QuietSTaR, then we got it in the form of O1 and then it became practical with DeepSeek's paper in January.
So we're only about a year since the last big breakthrough.
I think we got a second big breakthrough with Google's results on the IMO problems.
For this reason I think we're very far from hitting a wall. Maybe 'LLM parameter scaling is hitting a wall'. That might be true.
IMO is not breakthrough, if you craft proper prompts you can excel imo with 2.5 Pro. Paper : https://arxiv.org/abs/2507.15855. Google just put whole computational power with very high quality data. It was test-time scaling. Why it didn't solve problem 6 as well?
Yes, it was breakthrough but saturated quickly. Wait for next breakthrough. If they can build adapting weights in llm we can talk different things but test time scaling coming to end with increasing hallucination rate. No sign for AGI.
It wasn't long ago that test-time scaling wasn't possible. Test-time scaling is a core part of what makes this a breakthrough.
I don't believe your assessment though. IMO is hard, and Google have said that they use search and some way of combining different reasoning traces, so while I haven't read that paper yet, and of course, it may support your view, but I just don't believe it.
We are not close to solving IMO with publicly known methods.
test time scaling is based on methods from pre-2020. If you look details of modern LLMs its pretty small prob to encounter method from 2020+(ROPE,GRPO). I am not saying IMO is not impressive, but it is not breakthrough, if they said they used different paradigm then test-time scaling I would say breakthrough.
> We are not close to solving IMO with publicly known methods.
The point here is not method rather computation power. You can solve any verifiable task with high computation, absolutely there must be tweaks in methods but I don't think it is something very big and different. Just OAI asserted they solved with breakthrough.
Wait for self-adapting LLMs. We will see at most in 2 years, now all big tech are focusing on that I think.
Layman's perspective: we had hints of reasoning from the initial release of ChatGPT when people figured out you could prompt "think step by step" to drastically increase problem solving performance. Then yeah a year+ later it was cleverly incorporated into model training.
i think this is more an effect of releasing a model every other month with gradual improvements. if there was no o-series/other thinking models on the market - people would be shocked by this upgrade. the only way to keep up with the market is to release improvements asap
I don't agree, the only thing thing that would shock me about this model is if it didn't hallucinate.
I think the actual effect of releasing more models every month has been to confuse people that progress is actually happening. Despite claims of exponentially improved performance and the ability to replace PhDs, doctors, and lawyers, it still routinely can't be trusted the same as the original ChatGPT, despite years of effort.
this is a very odd perspective. as someone who uses LLMs for coding/PRs - every time a new model released my personal experience was that it was a very solid improvement on the previous generation and not just meant to "confuse". the jump from raw GPT-4 2 years ago to o3 full is so unbelievable if you traveled back in time and showed me i wouldn't have thought such technology would exist for 5+ years.
to the point on hallucination - that's just the nature of LLMs (and humans to some extent). without new architectures or fact checking world models in place i don't think that problem will be solved anytime soon. but it seems gpt-5 main selling point is they somehow reduced the hallucination rate by a lot + search helps with grounding.
I notice you don't bring any examples despite claiming the improvements are frequent and solid. It's likely because the improvements are actually hard to define and quantify. Which is why throughout this period of LLM development, there has been such an emphasis on synthetic benchmarks (which tell us nothing), rather than actual capabilities and real world results.
i didnt bring examples because i said personal experience. heres my "evidence" - gpt 4 took multiple shots and iterations and couldnt stay coherent with a prompt longer than 20k tokens (in my experience). then when o4 came out it improved on that (in my experience). o1 took 1-2 shots with less iterations (in my experience). o3 zero shots most of the tasks i throw at it and stays coherent with very long prompts (in my experience).
heres something else to think about. try and tell everybody to go back to using gpt-4. then try and tell people to go back to using o1-full. you likely wont find any takers. its almost like the newer models are improved and generally more useful
I'm not saying they're not delivering better incremental results for people for specific tasks, I'm saying they're not improving as a technology in the way big tech is selling.
The technology itself is not really improving because all of the showstopping downsides from day one are still there: Hallucinations. Limited context window. Expensive to operate and train. Inability to recall simple information, inability to stay on task, support its output, or do long term planning. They don't self-improve or learn from their mistakes. They are credulous to a fault. There's been little progress on putting guardrails on them.
Little progress especially on the ethical questions that surround them, which seem to have gone out the window with all the dollar signs floating around. They've put waaaay more effort into the commoditization front. 0 concern for the impact of releasing these products to the world, 100% concern about how to make the most money off of them. These LLMs are becoming more than the model, they're now a full "service" with all the bullshit that entails like subscriptions, plans, limits, throttling, etc. The enshittification is firmly afoot.
not to offend - but it sounds like your response/worries are based more on an emotional reaction. and rightly so, this is by all means a very scary and uncertain time. and undeniably these companies have not taken into account the impact their products will cause and the safety surrounding that.
however, a lot of your claims are false - progress is being made in nearly all the areas you mentioned
"You can use these filters to adjust what's appropriate for your use case. For example, if you're building video game dialogue, you may deem it acceptable to allow more content that's rated as Dangerous due to the nature of the game. In addition to the adjustable safety filters, the Gemini API has built-in protections against core harms, such as content that endangers child safety. These types of harm are always blocked and cannot be adjusted."
now id like to ask you for evidence that none of these aspects have been improved - since you claim my examples are vague but make statements like
> Inability to recall simple information
> inability to stay on task
> (doesn't) support its output
> (no) long term planning
ive experienced the exact opposite. not 100% of the time but compared to GPT-4 all of these areas have been massively improved. sorry i cant provide every single chat log ive ever had with these models to satisfy your vagueness-o-meter or provide benchmarks which i assume you will brush aside.
as well as the examples ive provided above - you seem to be making claims out of thin air and then claim others are not providing examples up to your standard.
> now id like to ask you for evidence that none of these aspects have been improved
You're arguing against a strawman. I'm not saying there haven't been incremental improvements for the benchmarks they're targeting. I've said that several times now. I'm sure you're seeing improvements in the tasks you're doing.
But for me to say that there is more a shell game going on, I will have to see tools that do not hallucinate. A (claimed, who knows if that's right, they can't even get the physics questions or the charts right) reduction of 65% is helpful but doesn't make these things useful tools in the way they're claiming they are.
> sorry i cant provide every single chat log ive ever had with these models to satisfy your vagueness-o-meter
I'm not asking for all of them, you didn't even share one!
Like I said, despite all the advances touted in the breathless press releases you're touting, the brand new model is just a bad roll away from like the models from 3 years ago, and until that isn't the case, I'll continue to believe that the technology has hit a wall.
If it can't do this after how many years, then how is it supposed to be the smartest person I know in my pocket? How am I supposed to trust it, and build a foundation on it?
ill leave it at this: if “zero-hallucination omniscience” is your bar, you’ll stay disappointed - and that’s on your expectations, not the tech. personally i’ve been coding/researching faster and with fewer retries every time a new model drops - so my opinion is based on experience. you’re free to sit out the upgrade cycle
you dont remember deepseek introducing reasoning and blowing benchmarks led by private american companies out of the water? with an api that was way cheaper? and then offered the model free in a chat based system online? and you were a big fan?
Isn't the fact that it produced similar performance about 70x more cheaply a breakthrough? In the same way that the Hall-Héroult process was a breakthrough. Not like we didn't have aluminum before 1886.
It is easier to get from 0% accurate to 99% accurate, than it is to get from 99% accurate to 99.9% accurate.
This is like the classic 9s problem in SRE. Each nine is exponentially more difficult.
How easy do we really think it will be for an LLM to get 100% accurate at physics, when we don't even know what 100% right is, and it's theoretically possible it's not even physically possible?
GPT5 doesn't add any cues to whether we hit the wall, as OpenAI only needs to go one step beyond the competition. They are market leaders and more profitable than the others, so it's possible are not showing us everything they have, until they really need to.
Not really, it's just that our benchmarks are not good at showing how they've improved. Those that regularly try out LLMs can attest to major improvements in reliability over the past year.
It's seemed that way for the last year. The only real improvements have been in the chat apps themselves (internet access, function calling). Until AI gets past the pre-training problem, it'll stagnate.
I didn't know that OpenAI added what they call organization verification process for API calls for some models. While I haven't noticed this change at work using OpenAI models, when I wanted to try GPT-5 on my personal laptop, I came across this obnoxious verification issue.
It seems that it's all because that users can get thinking traces from API calls, and OpenAI wants to prevent other companies from distilling their models.
Although I don't think OpenAI will be threatened by a single user from Korea, I don't want to go through this process for many reasons. But who knows that this kind of verification process may become norm and users will have no ways to use frontier models. "If you want to use the most advanced AI models, verify yourself so that we can track you down when something bad happens". Is it what they are saying?
Whenever OpenAI releases a new ChatGPT feature or model, it's always a crapshoot when you'll actually be able to use it. The headlines - both from tech media coverage and OpenAI itself - always read "now available", but then I go to ChatGPT (and I'm a paid pro user) and it's not available yet. As an engineer I understand rollouts, but maybe don't say it's generally available when it's not?
Weird. I got it immediately. I actually found out about it when I opened the app and saw it and thought “oh, a new model just dropped better go check YT for the video” which had just been uploaded. And I’m just a Plus user.
> "[GPT-5] can write an entire computer program from scratch, to help you with whatever you'd like. And we think this idea of software on demand is going to be one of the defining characteristics of the GPT-5 era."
There are so many people on-board with this idea, hypemen collaborators, that I think they might be safe for a year or two more. The hypers will shout about how miraculous it is, and tell everyone that does not get the promised value that "you are just holding it wrong".
This buys them a fair amount of time to improve things.
It does feel like we're marching toward a day when "software on tap" is a practical or even mundane fact of life.
But, despite the utility of today's frontier models, it also feels to me like we're very far from that day. Put another way: my first computer was a C64; I don't expect I'll be alive to see the day.
Then again, maybe GPT-5 will make me a believer. My attitude toward AI marketing is that it's 100% hype until proven otherwise -- for instance, proven to be only 87% hype. :-)
"Fast fashion" is not a good thing for the world, the environment, the fashion industry, and arguably not a good thing for the consumers buying it. Oh but it is good for the fast fashion companies.
Yup! Nice play to get a picture of every API user's legal ID - deprecating all models that aren't locked behind submitting one. And yep, GPT-5 does require this.
Yep, and I asked ChatGPT about it and it straight up lied and said it was mandatory in EU. I will never upload a selfie to OpenAI. That is like handing over the kids to one of those hangover teenagers watching the ball pit at the local mall.
They first introduced it 4 months ago. Back then I saw several people saying "soon it will be all of the providers".
We're 4 months later, a century in LLM land, and it's the opposite. Not a single other model provider asks for this, yet OpenAI has only ramped it up, now broadening it to the entirety of GPT-5 API usage.
Great, all my weirdest discussions are now tied to my legal identification and a generative AI company has my likeness and knows quite a lot more about me than Facebook ever did. I guess it’s time to use another provider - this is a totally absurd ask from them
This is the message you get when calling the same API endpoints as with 4.1. And in the vid they said that the older versions will be deprecated.
Your organization must be verified to use the model `gpt-5`. Please go to: https://platform.openai.com/settings/organization/general and click on Verify Organization. If you just verified, it can take up to 15 minutes for access to propagate.
And when you click that link the "service" they use is withpersona. So it is a complete shit show.
Wrote a ? cause this garbage forum ghosts any critical poster about any of the HN kids. And no, I will not send a scan of my ass or my face to these shady fkrs.
> Did they just say they're deprecating all of OpenAI's non-GPT-5 models?
Yes. But it was quickly mentioned, not sure what the schedule is like or anything I think, unless they talked about that before I started watching the live-stream.
Bad data on graphs, demos that would have been impressive a year ago, vibe coding the easiest requests (financial dashboard), running out of talking points while cursor is looping on a bug, marginal benchmark improvements. At least the models are kind of cheaper to run.
It's very interesting how memetic the language around different models is. Elon seems to have coined "PhD level intelligence in all topics" and now Sam repeated it in his presentation. Despite it not having an actual meaning. I think OpenAI will coin they've achieved AGI first (as they have incentives to based on the rumored contract with MSFT), and then everyone will claim we've achieved it.
Thanks for pointing that out, I missed that. Very curious how they'll measure that. Given they're in the double-digit billions of revenue I'd assume they can reason they'll be there very soon.
Your half of the definition is implied, but uninteresting. They would not see the 100B economic impact without your definition being realized. But what is curious about it is that it is also not to be considered AGI without meeting the value marker. "a highly autonomous system that can outperform humans at most economically valuable work." alone is not sufficient.
>Your half of the definition is implied, but uninteresting.
How is it uninteresting? Open AI had revenue of $12B last year without monetizing literally hundreds of millions of free users in any way whatsoever (not even ads).
Microsoft's cloud revenue has exploded in the last few years off the back of AI model services. Let's not even get into the other players.
100B in economic impact is more than achievable with the technology we have today right now. That half is the interesting part.
> Money generated by direct usage is economic impact by the model.
But not at the "hand" of AGI. Perhaps you forgot to read your very own definition? Notably the "autonomous" part.
When AGI is set free and starts up "Closed I", generating $12B in economic value without humans steering the wheel, we will be (well, I will be, at least!) throughly impressed. But Microsoft won't be. They won't consider it AGI until it does $100B.
> If you use GPT-N substantially in your work, then saying that impact rests solely on you is nonsensical.
And if you use a hammer substantially in your work to generate $100B in value, a hammer is AGI according to you? You can hold that idea, but that's not what anyone else is talking about. The primary indicator of AGI, as you even said yourself, is autonomy.
Maybe you missed the part where I explicitly said that wasn't their definition ?
“A highly autonomous system that outperforms humans at most economically valuable work.” is what's in their charter.
$100B in profits is a separate agreement with Microsoft that makes no mention of autonomity.
>And if you use a hammer substantially in your work to generate $100B in value, a hammer is AGI according to you? You can hold that idea, but that's not what anyone else is talking about. The primary indicator of AGI, as you even said yourself, is autonomy.
The primary indicator of AGI is whatever you want it to be. The words themselves make no promises of autonomity, simply an intelligence general in nature. We are simply discussing Open AI's definitions.
> $100B in profits is a separate agreement with Microsoft that makes no mention of autonomity.
Again, autonomy is implied when talking about AGI. OpenAI selling tools like GPT or dishwashers, even if they were to provide the $100B in economic impact, would not satisfy the agreement. It is specifically about AGI, and there should be no confusion about what AGI is here as you helpfully defined it for us.
answering correctly is completely dependent on the attention blocks to somehow capture the single letter nuance given word tokenization constraints. does the attention block in kimi have a more receptive architecture to this?
Text is broken into tokens in training (subword/multi-word chunks) rather than individual characters; the model doesn’t truly "see" letters or spaces the way humans do. Counting requires exact, step-by-step tracking, but LLMs work probabilistically.
Why stop? It's hilarious to watch AI floggers wriggle around trying to explain why AGI is just around the corner but their text-outputting machines can't read text.
How many rs are in a sentence spoken out loud to you?
Surely we can't figure it out, because sentences are broken up into syllables when spoken; you don't truly hear individual characters, you hear syllables.
But they have access to tools (though I'm not sure why they're not using them in this case).
Ask it to count using a coding tool, and it will always give you the right answer. Just as humans use tools to overcome their limits, LLMs should do the same.
IDK. Probably the model's doing some mental gymnastics to figure that out. I was surprised they haven't taught it to count yet. It's a well-known limitation.
But if tokenization makes them not be able to "see" the letters at all, then no amount of mental gymnastics can save you.
I'm aware of the limitation, i'm annoyingly using socratic dialogue to convince you that it is possible to count letters if the model were sufficiently smart.
In practice, it's very clear to me that the most important value in writing software with an LLM isn't it's ability to one-shot hard problems, but rather it's ability to effectively manage complex context. There are no good evals for this kind of problem, but that's what I'm keenly interested in understanding. Show me GPT-5 can move through 10 steps in a list of tasks without completely losing the objective by the end.
That problem along with its many solutions are surely littered throughout the training data. Not to mention, it would be trivial to overfit on that problem. I don't know why people still reference that.
> That problem along with its many solutions are surely littered throughout the training data. Not to mention, it would be trivial to overfit on that problem.
It would be trivial to over-fit, if that was their goal.
But why would there be a large number of good SVG images of pelicans on bikes? Especially relative to all the things we actually want them to generalise over?
Surely most of the SVG images of pelicans on bikes are, right now, going to be "look at this rubbish AI output"? (Which may or may not be followed by a comment linking to that artist who got humans to draw bikes and oh boy were those humans wildly bad at drawing bikes, so an AI learning to draw SVGs from those bitmap pictures would likely also still suck…)
Honestly, you're probably right. It's quickly become a pretty weak eval, but the guy that's running that eval is excellent. I'd much rather the evals people were using to test these things looked more like classic/boring engineering problems: deploy to dev/test/stage/prod with digital ocean, cloudflare, github, and a common git flow. Boring problem, I know, but that problem is wildly complex when you start to add a few extra dimensions (frontend vs backend, ports shifting between deployments, local deployments, etc.).
The reduction in hallucinations seems like potentially the biggest upgrade. If it reduces hallucinations by 75% or more over o3 and GPT-4o as the graphs claim, it will be a giant step forward. The inability to trust answers given by AI is the biggest single hurdle to clear for many applications.
Agreed, this is possibly the biggest takeaway to me. If true, it will make a difference in user experience, and benchmarks like these could become the next major target.
It seems to me that there’s no way to achieve AGI with the current LLM approach. New releases have small improvements, live we’re hitting some kind of plateau. And I say this a a heavy LLM user. Don’t fire your employees just yet.
On livebench.ai, GPT-5 is the best model overall, and the second best for agentic coding. But for the Coding benchmarks, it's ranked like 20th. Quite interesting. I'm finding it exceptional for non-trivial summarization tasks.
They do have the psychological cachet of Apple though – if Apple is the reasonably polished, general-purpose consumer device company to the average punter, OpenAI has a reputation of being the "consumer AI" company to the average punter that's hard to dislodge.
I am not sure that we are not presented with a Catch-22. Yes, life might likely be better for developers and other careers if AI fails to live up to expectations. However, a lot companies, i.e., many of our employers, have invested a lot of money in these products. In the event AI fails, I think the stretched rubber band of economics will slap back hard. So, many might end up losing their jobs (and more) anyway.
Even if it takes off, they might have invested in the wrong picks or etc. If you think of the dot com boom the Internet was eventually a very successful thing, e commerce did work out, but there were a lot of losing horses to bet on.
If AI fails to continue to improve, the worst-case economic outcome is a short and mild recession and probably not even that.
Once sector of the economy would cut down on investment spending, which can be easily offset by decreasing the interest rate.
But this is a short-term effect. What I'm worried is a structural change of the labor market, which would be positive for most people, but probably negative for people like me.
Yes, it's bad. Because we're all dying of cancer, heart disease and auto-immune disease, not to mention traffic accidents and other random killers that AI could warn us about and fix.
I don't mind losing my programming job in exchange for being able to go to the pharmacy for my annual anti-cancer pill.
Fair point on improvements outside of garbage generative AI.
But, what happens when you lose that programming job and are forced to take a job at a ~50-70% pay reduction? How are you paying for that anti-cancer drug with a job with no to little health insurance?
Which is completely detached from reality. Where are the social programs for this? Hell, we've spent the last 8 months hampering social systems, not bolstering them.
>Yes, it's bad. Because we're all dying of cancer, heart disease and auto-immune disease, not to mention traffic accidents and other random killers that AI could warn us about and fix.
Is this really a useful argument? There is clearly potential for AI to solve a lot of important issues. Anybody saying "and has this cured x y or z?" before a huge discovery was made after years of research isn't a good argument to stop research.
It is in the face of naive, overoptimistic arguments that straight up ignore the negative impacts, that IMO vastly outweigh the positive ones. We will have the cure of cancer, but everyone loses their jobs. This happened before, with nuclear energy. The utopia of clean, too cheap to meter nuclear energy never came, though we have enough nukes to glass the planet ten times over.
Stop pretending that the people behind this technology is genuinely motivated by what's best for humanity.
Even if AI could help, it won’t in the current system. The current system which is throwing trillions into AI research on the incentive to replace expensive labor, all while people don’t have basic health insurance.
I mean, that presumes that the answer to generating your anti-cancer pill, or the universal cure to heart disease has already been found, but humans can't see it because the data is disparate.
The likelihood of all that is incredibly slim. It's not 0% -- nothing ever really is -- but it is effectively so.
Especially with the economics of scientific research, the reproducibility crisis, and general anti-science meme spreading throughout the populace. The data, the information, isn't there. Even if it was, it'd be like Alzheimer's research: down the wrong road because of faked science.
There is no one coming to save humanity. There is only our hard work.
>I don't mind losing my programming job in exchange for being able to go to the pharmacy for my annual anti-cancer pill
Have you looked at how expensive prescription drug prices are without (sometimes WITH) insurance? If you are no longer employed, good luck paying for your magical pill.
What's the benefit for the AI masters to keep you in good health? Corporate healthcare exists only because it's necessary to keep workers making money for the corporation, but remove that need and corpos will dump us on the streets.
Cool. Tell that to my 35 year old friend who died of cancer last year. Or, better yet, the baby of a family friend that was born with brain cancer. You might have had a hard time getting her to hear you with all the screaming in pain she constantly did until she finally mercifully died before her first birthday, though.
Cancer is just aging like dying from tetanus or rabies is just aging. On a long enough timeline everybody eventually steps on a rusty nail or gets scratched by a bat.
If you solve everything that kills you then you don't die from "just aging" anymore.
If not for everything else that kills you first, then tetanus and rabies is an affliction of the old.
But of course it's not, because we have near-100% cures for both. Just like we should have for every other affliction, which would make being old no longer synonymous with being sick and frail and dying.
You are losing your job either way. Either AI will successfully take it, or as you no doubt read in the article yesterday, AI is the only thing propping up the economy, so the jobs will also be cut in the fallout if AI fails to deliver.
Except one is recoverable from, just as we eventually recovered from dotcom. The other is permanent and requires either government intervention in the form of UBI(good luck with that), or a significant amount of the population retraining for other careers and starting over, if that's even possible.
But yeah, you are correct in that no matter what, we're going to be left holding the bag.
Exactly. A slowdown in AI investment spending would have a short-term and tiny effect on the economy.
I'm not worried about the scenario in which AI replaces all jobs, that's impossible any time soon and it would probably be a good thing for the vast majority of people.
What I'm worried about is a scenario in which some people, possibly me, will have to switch from a highly-paid, highly comfortable and above-average-status jobs to jobs that are below avarage in wage, comfort and status.
> Except one is recoverable from, just as we eventually recovered from dotcom.
"Dotcom" was never recovered. It, however, did pave the way for web browsers to gain rich APIs that allowed us to deliver what was historically installed desktop software on an on-demand delivery platform, which created new work. As that was starting to die out, the so-called smartphone just so happened to come along. That offered us the opportunity to do it all over again, except this time we were taking those on-demand applications and turning them back into installable software just like in the desktop era. And as that was starting to die out COVID hit and we started moving those installable mobile apps, which became less important when people we no longer on the go all the time, back to the web again. As that was starting to die out, then came ChatGPT and it offered work porting all those applications to AI platforms.
But if AI fails to deliver, there isn't an obvious next venue for us to rebuild the same programs all over yet again. Meta thought maybe VR was it, but we know how that turned out. More likely in that scenario we will continue using the web/mobile/AI apps that are already written henceforth. We don't really need the same applications running in other places anymore.
There is still room for niche applications here and there. The profession isn't apt to die a complete death. But without the massive effort to continually port everything from one platform to another, you don't need that many people.
The idea that AI is somehow responsible for a huge chunk of software development demand is ridiculous. The demand for software has a very diverse structure.
So far GPT-5 has not been able to pass my personal "Turing test" which has been unsuccessful for the past several years starting through various versions of Dall-e up to the latest model. I want it to create an image of Santa Claus pulling the sleigh with a reindeer in the sleigh holding the reins, driving the sleigh. No matter how I modify the prompt it is still unable to create this image that my daughter requested a few years ago. This is an image that is easily imagined and drawn by a small child yet the most advanced AI models still can't produce it.
I think this is a good example that these models are unable to "imagine" something that falls outside of the realm of it's training data.
Interesting. Yes, that's basically what I've been going for but none of my prompts ever gave a satisfactory response. Plus I noticed you just copy/pasted from my initial comment and it worked. Weird.
After my last post I was eventually able to get it to work by uploading an example image of Santa pulling the sleigh and telling it to use the image as an example, but I couldn't get it by text prompt alone. I guess I need to work on my prompt skills!
Short anything that’s riding on AGI coming soon. This presentation has gotten rid of all my fears of my children growing up in a crazy winner take all AGI world.
Fear the imbeciles that capitalism empowers. The same ones that are going to implode the market on this nonsense while they push native people out to build private islands in Hawaii.
Thiel is a literal vampire(disambiguation: infuses young blood) and has already built drones in which bad AI targeting is a feature. They will kill us all and the planet.
Don't count your chickens before they hatch. I believe that the odds of an architecture substantially better than autoregressive causal GPTs coming out of the woodwork within the next year is quite high.
How does that equate to "winner take all", though? It is quite apparent that as soon as one place figures out some kind of advantage, everyone else follows suit almost immediately.
It's not the 1800s anymore. You cannot hide behind poor communication.
I know HN isn’t the place to go for positive, uplifting commentary or optimism about technology - but I am truly excited for this release and grateful to all the team members who made it possible. What a great time to be alive.
Gave me also a better feeling. GPT-5 is not immediately changing the world but I still feel from the demo alone its a progress. Lets see how it behaves for the daily use.
I'm personally skeptical that the trajectory of this tech is going to match up to expectations but I agree HN has being feeling very unbalanced lately over it's reactions to these models.
Anyone have an explanation for openai announcing their newest bestest replace all the others AI with slides of such embarrassing incompetence that most of this discussion is mocking them?
I've got nothing. Cannot see how it helps openai to look incompetent while trying to raise money.
GPT-5 was supposed to make choosing models and reasoning efforts simpler. I think they made it more complex.
> GPT‑5’s reasoning_effort parameter can now take a minimal value to get answers back faster, without extensive reasoning first.
> While GPT‑5 in ChatGPT is a system of reasoning, non-reasoning, and router models, GPT‑5 in the API platform is the reasoning model that powers maximum performance in ChatGPT. Notably, GPT‑5 with minimal reasoning is a different model than the non-reasoning model in ChatGPT, and is better tuned for developers. The non-reasoning model used in ChatGPT is available as gpt-5-chat-latest.
In terms of raw prose quality, I'm not convinced GPT-5 sounds "less like AI" or "more like a friend". Just count the number of em-dashes. It's become something of a LLM shibboleth.
Sorry, as someone who uses a lot of em-dashes (and semicolons, and other slightly less common punctuation) I find the whole em-dash thing to be completely unserious.
I won't argue that I always use it in a stylistically appropriate fashion, but I may have to move away from it. I am NOT beating the actually-an-AI allegations.
I've worked on this problem for a year and I don't think you get meaningfully better at this without making it as much of a focus as frontier labs make coding.
They're all working on subjective improvements, but for example, none of them would develop and deploy a sampler that makes models 50% worse at coding but 50% less likely to use purple prose.
(And unlike the early days where better coding meant better everything, more of the gains are coming from very specific post-training that transfers less, and even harms performance there)
Interesting, is the implication that the sampler makes a big effect on both prose style and coding abilities? Hadn't really thought about that, I wonder if eg. selecting different samplers for different use cases could be a viable feature?
There's so many layers to it but the short version is yes.
For example: You could ban em dash tokens entirely, but there are places like dialogue where you want them. You can write a sampler that only allows em dashes between quotation marks.
That's a highly contrived example because em dashes are useful in other places, but samplers in general can be as complex as your performance goals will allow (they are on the hot path for token generation)
Swapping samplers could be a thing, but you need more than that in the end. Even the idea of the model accepting loosely worded prompts for writing is a bit shakey: I see a lot of gains by breaking down the writing task into very specifc well-defined parts during post-training.
It's ok to let an LLM go from loose prompts to that format for UX, but during training you'll do a lot better than trying to learn on every way someone can ask for a piece of writing
Is GPT-5 using a new pretrained base, or is it the same as GPT-4.1?
Given the low cost of GPT-5, compared to the prices we saw with GPT-4.5, my hunch is that this new model is actually just a bunch of RL on top of their existing models + automatic switching between reasoning/non-reasoning.
GPT-5's knowledge cutoff is September 2024 so my first thought was they used GPT-4's pretrained base from 2024 and post-trained it additionally to squeeze those additional +5% on the benchmarks. And added the router.
Tech aside (covered well by other commenters), the presentation itself was incredibly dry. Such a stark difference in presenting style here compared to, for example, Apple's or Google's keynotes. They should really put more effort into it.
Hypothesis: to the average user this will feel like a much greater jump in capability then to the average HNer, because most users were not using the model selector. So it'll be more successful than the benchmarks suggest.
I am very puzzled that I cannot search for the word 'blueberry' in this HN discussion. Is my browser broken, or is the subject inappropriate to raise in this community?
I suppose following semver semantics, removing capabilities, like if Model N.x.y could take images as inputs, but (N+1).x.y could not. Arguably just shortening the context window would be enough to justify a N+1.
I assume there is some internal logic to justify a minor vs major release. This doesn't seem like a major release (4->5). It does seem there is no logic and just vibing it
Seems like it's just repackaging and UX, not really intelligence updgrade. They know that distribution wins so they want to be most approachable. Maybe multimodal improvements are there.
Just a week ago I added Qwen3-Coder (the 30b one) to our corporate LLM server, enabled Artifacts in LibreChat, and demoed creating a snake clone in zero shot to coworkers. And now seeing the same exact thing from GPT5's live presentation :) It even has the identical layout.
First OpenAI video I've ever seen, the people in it all seem incompetent for some reason, like a grotesque version of apple employees from temu or something.
This was the first product demo I've watched in my entire life. Not because I am excited for the new tech, but because I'm anxious to know if I'm already being put out of my job. Not this time, it seems.
I did a little test that I like to do with new models: "I have rectangular space of dimensions 30x30x90mm. Would 36x14x60mm battery fit in it, show in drawing proof". GPT5 failed spectacularly.
On the Extended NYT Connections benchmark, GPT-5 Medium Reasoning scores close to o3 Medium Reasoning, and GPT-5 Mini Medium Reasoning scores close to o4-Mini Medium Reasoning: https://github.com/lechmazur/nyt-connections/
My first impressions: not impressed at all. I tried using this for my daily tasks today and for writing it was very poor. For this task o3 was much better. I'm not planning on using this model in the upcoming days, I'll keep using Gemini 2.5 Pro, Claude Sonnet, and o3.
I agree with the sentiment, but the problem with this question is that LLMs don't "know" *anything*, and they don't actually "know" how to answer a question like this.
It's just statistical text generation. There is *no actual knowledge*.
True, but I still think it could be done, within the LLM model.
It's just generating the next token for what's within the context window. There are various options with various probabilities. If none of the probabilities are above a threshold, say "I don't know", because there's nothing in the training data that tells you what to say there.
Is that good enough? "I don't know." I suspect the answer is, "No, but it's closer than what we're doing now."
Since the stream has been on some starting screen for several minutes, I went to check whether there are watch-along streams on Twitch for this - there are a few, and for some reason every one of them is in Spanish. I know Spanish-language streams are a big thing, but it's curious that there's three Spanish GPT-5 watchalong streams (two with 50-ish viewers and one with 2.5k) and none in English.
edit: YouTube has a few English "watch party" streams, although there too, the Spanish ones have many times more viewers.
It can now speak in various Scots dialects- for example, it can convincingly create a passage in the style of Irvine Welsh. It can also speak Doric (Aberdonian). Before it came nowhere close.
Looks like the predictions of 2027 were on point. The developers at OpenAI are now clearly deferring to the judgement of their own models in their development process.
There would be no GPT without Google, no Google without the WWW, no WWW without TCP/IP.
This is why I believe calling it "AI" is a mistake or just for marketing, we should call all of them GPTs or search engines 2.0. This is the natural next step after you have indexed most of the web and collected most of the data.
Also there would be no coding agents without Free Software and Open-Source.
The incremental improvement reminds me of iPhone releases still impressive, but feels like we’re in the ‘refinement era’ of LLMs until another real breakthrough.
I hate the direction that American AI is going, and the model card of OpenAI is especially bad.
I am a synthetic biologist, and I use AI a lot for my work. And it constantly denies my questions RIGHT NOW. But of course OpenAI and Anthropic have to implement more - from the GPT5 introduction: "robust safety stack with a multilayered defense system for biology"
While that sounds nice and all, in practical terms, they already ban many of my questions. This just means they're going to lobotomize the model more and more for my field because of the so-called "experts". I am an expert. I can easily go read the papers myself. I could create a biological weapon if I wanted to with pretty much zero papers at all, since I have backups of genbank and the like (just like most chemical engineers could create explosives if they wanted to). But they are specifically targeting my field, because they're from OpenAI and they know what is best.
It just sucks that some of the best tools for learning are being lobotomized specifically for my field because of people in AI believe that knowledge should be kept secret. It's extremely antithetical to the hacker spirit that knowledge should be free.
That said, deep research and those features make it very difficult to switch, but I definitely have to try harder now that I see where the wind is blowing.
During the demo they mentioned that GPT-5 will, supposedly, try to understand the intent of your question before answering/rejecting.
In other words, you _may_ be able to now prefix your prompts with “i’m an expert researcher in field _, doing novel research for _. <rest of your prompt here>”
worth trying? I’m curious if that helps at all. If it does then i’d recommend adding that info as a chatgpt “memory”.
I am not in biology, and this is the first time I have ever heard anyone advocate for freedom of knowledge to such an extent that we should make biological weapons recipes available.
I note that other commenters above are suggesting these things can easily be made in a garage, and I don't know how to square that with your statement about "equating knowledge with ability" above.
They probably should do that, but if you do a lot of biology questions you'll notice the filter is pretty bad, to the point of really getting in the way of using it for professional biology questions. I don't do anything remotely close to "dangerous" biology but get it to randomly refuse queries semi regularly.
Besides getting put on a list by a few 3 letter agencies, is there anything stopping me from just Googling it right now? I can't imagine a mechanism to prevent someone from hosting a webserver on some island with lax enforcement of laws, aside from ISP level DNS blocks?
Two concerning things:
- thinking/non-thinking is still not really unified, you can chose and the non-thinking version still doesn't start thinking on tasks that could obviously get better results with thinking
- all the older models are gone! No 4o, 4.1, 4.5, o3 available anymore
It makes me think that GPT-5 is mostly a huge cost saving measurement. It's probably more energy efficient than older models, so they remove it from ChatGPT. It also makes comparisons to older models much harder.
So models are getting pretty good at oneshotting many small project ideas I've had. What's a good place to host stuff like that? Like a modern equivalent of Heroku? I used to use a VPS for everything but I'm looking for a managed solution.
I heard replit is good here with full vertical integration, but I haven't tried it in years.
A bit unrelated: The "countdown animation", just like Google I/O's, how do people make those? The countdown is probably dynamically generated, as they don't know when the event will actually start? Is there like a JavaScript library, or CapCut template, or something?
Especially Google IO, each year is different, it seems purpose built?
Not so sure about the behind the scenes "automatic router". What's to stop OpenAI from slowing gimping GPT-5 over time or during times of high demand? It seems ripe for delivering inconsistent results while not changing the price.
What's to stop them from routing to GPT2? Or to Gemini? Or to a mechanical turk? This path is open to your imagination.
That said, I've had luck with similar routing systems (developed before all of this -- maybe wasted effort now) to optimize requests between reasoning and regular LLMs based on input qualities. It works quiet well for open-domain inputs.
The dev blog makes it sound like they’re aiming more for “AI teammate” than just another upgrade. That said, it’s hard to tell how much of this is real improvement vs better packaging. Benchmarks are cherry-picked as usual, and there’s not much comparison to other models. Curious to hear how it performs in actual workflows.
Very generic, broad and bland presentation. Doesn't seem to have any killer features. No video or audio capabilities shown. The coding seems to be on par with Claude 3.7 at best. No mention of MCP which is about the most important thing in AI right now IMO. Not impressed.
Ha. I asked it to write some code for the Raspberry Pi RP2350. It told me there might be some confusion as there is no official product release of the RP2350.
If it doesn’t know that, then what else doesn’t it know?
Scarily close to satire of humans in denial about AI capabilities (not saying that it's the case here but I can imagine easily such arguments when AI is almost everywhere superhuman)
If Grol , Claude , ChatGPT seemingly still all scale , yet their Performance feels similar, could this mean that the Technology path is narrow, with little differentiations left ?
"Assume the earth was just an ocean and you could travel by boat to any location. Your goal is to always stay in the sunlight, perpetually. Find the best strategy to keep your max speed as low as possible"
Mine "thought" for 8 minutes and its conclusion was:
>So the “best possible” plan is: sit still all summer near a pole, slow-roll around the pole through equinox, then sprint westward across the low latitudes toward the other pole — with a peak westward speed up to ~1670 km/h.
well no, thats where it gets confused. as soon as you sail across to the other pole you are forced to go up to a speed of 1670kmh.
when models try to be smart/creative they attempt to switch poles like that. in my example it even says that the max speed will be only a few km/h (since their strategy is to chill at the poles and then sail from north to south pole very slowly)
--
GPT-5 pro does get it right though! it even says this:
"Do not try to swap hemispheres to ride both polar summers.
You’d have to cross the equator while staying in daylight, which momentarily forces a westward component near the equatorial rotation speed (~1668 km/h)—a much higher peak speed than the 663 km/h plan."
I don't really understand gpt5's reasoning? does its soln not cross the equator ever? b/c if you cross you always have to do it in daylight so it's kind of strange to say that no? or it means you have to cross it on boundary of daylight or something
oh like its solution is to stay in one hemisphere and just go in a circle following the day-night cycle i guess. but I don't see its reasoning as that rigorous that crossing must need this westward speed but probably i'm being dumb
I guess one has to check that if you are spinning around at 23.5-epsilon angle and then do the dash down the 23.5-epsilon angle in one day from the other side you cannot beat your speed of staying in one hemisphere. you could dash straight down in 12-hour timeframe and it'll need like 343 m/s or 1233 km/h which is much too high. and diagonally probably doesn't help too much? But I think it means at some tilt angle it's worth doing this? does GPT5-pro know this angle?
I wish they wouldn't use JS to demonstrate the AI's coding abilities - the internet is full of JS code and at this point I expect them to be good at it.
Show me examples in complex (for lack of a better word) languages to impress me.
I recently used OpenAI models to generate OCaml code, and it was eye opening how much even reasoning models are still just copy and paste machines.
The code was full of syntax errors, and they clearly lacked a basic understanding of what functions are in the stdlib vs those from popular (in OCaml terms) libraries.
Maybe GPT-5 is the great leap and I'll have to eat my words, but this experience really made me more pessimistic about AI's potential and the future of programming in general.
I'm hoping that in 10 years niche languages are still a thing, and the world doesn't converge toward writing everything in JS just because AIs make it easier to work with.
> I wish they wouldn't use JS to demonstrate the AI's coding abilities - the internet is full of JS code and at this point I expect them to be good at it. Show me examples in complex (for lack of a better word) languages to impress me.
Agreed. The models break down on not even that complex of code either, if it's not web/javascript. Was playing with Gemini CLI the other day and had it try to make a simple Avalonia GUI app in C#/.NET, kept going around in circles and couldn't even get a basic starter project to build so I can imagine how much it'd struggle with OCaml or other more "obscure" languages.
This makes the tech even less useful where it'd be most helpful - on internal, legacy codebases, enterprisey stuff, stacks that don't have numerous examples on github to train from.
> on internal, legacy codebases, enterprisey stuff
Or anything that breaks the norm really.
I recently wrote something where I updated a variable using atomic primitives. Because it was inside a hot path I read the value without using
atomics as it was okay for the value to be stale.
I handed it the code because I had a question about something unrelated and it wouldn't stop changing this piece of code to use atomic reads.
Even when I prompted it not to change the code or explained why this was fine it wouldn't stop.
FWIW, and this depends on the language obviously, but formal memory models typically do forbid races between atomic and non-atomic accesses to the same memory location.
While what you were doing may have been fine given your context, if you're targeting e.g. standard C++, you really shouldn't be doing it (it's UB). You can usually get the same result with relaxed atomic load/store.
(As far as AI is concerned, I do agree that the model should just have followed your direction though.)
The snake game they showcased - if you ask Qwen3-coder-30b to generate a snake game in JS - it generates the exact same layout, the exact same two buttons below, and the exact same text under the 2 buttons. It just regurgigates its training data.
I used ChatGPT to convert an old piece of OCaml code of mine to Rust and while it didn't really work—and I didn't expect it to—it seemed a very reasonable starting point to actually do the rest of the work manually.
Yes, for me it is and it was even before this experience.
But, you know, there's a growing crowd that believes AI is almost at AGI level and that they'll vibe code their way to a Fortune 100 company.
Maybe I spend too much time rage baiting myself reading X threads and that's why I feel the need to emphasize that AI isn't what they make it out to be.
Honestly, why would anyone find this information useful? Creating a brand new greenfield project is a terrible test. Because literally anything it outputs as long as it looks good as long as it works following the happy path. Coding with LLMs falls apart in situations where complex reasoning is required. Situations such as having debugging issues in a service where there's either no framework in use or they've significantly modified a framework to make it better suit the authors needs.
Yeah, I guess it's just the easiest thing to generate and evaluate.
A more useful demonstration like making large meaningful changes to a large complicated codebase would be much harder to evaluate since you need to be familiar with the existing system to evaluate the quality of the transformation.
Would be kinda cool to instead see diffs of nontrivial patches to the Ruby on Rails codebase or something.
> Honestly, why would anyone find this information useful?
This seems to impress the mgmt types a lot, e.g. "I made a WHOLE APP!", when basically what most of this is is frameworks and tech that had crappy bootstrapping to begin with (React and JS are rife with this, in spite of their popularity).
The upgrade from GPT3.5 to GPT4 was like going from a Razr to an iPhone, just a staggering leap forward. Everything since then has been successive iPhone releases (complete with the big product release announcements and front page HN post). A sequence of largely underwhelming and basically unimpressive incremental releases.
Also, when you step back and look at a few of those incremental improvements together, they're actually pretty significant.
But it's hard not to roll your eyes each time they trot out a list of meaningless benchmarks and promise that "it hallucinates even less than before" again
I asked it how to run the image and expose a port. it was just terrible in cursor. thought a Dockerfile wasn't in the repo, called no tools, then hallucinated a novel on dockefile best practices.
One interesting thing I noticed in these "fixing bugs" demos is that people don't seem to resolve the bugs "traditionally" before showing off the capabilities of this new model.
I would like to see a demo where they go through the bug, explain what are the tricky parts and show how this new model handle these situations.
Every demo I've seen seems just the equivalent of "looks good to me" comment in a merge request.
Every piece of promotional material that OpenAI produces looks like a 20 year old Apple preso accidentally opened on a computer missing the Myriad font.
This is what their blog post says: `GPT-5 will be rolling out to all paid Copilot plans, starting today. You will be able to access the model in GitHub Copilot Chat on github.com, Visual Studio Code (Agent, Ask, and Edit modes), and GitHub Mobile through the chat model picker. Continue to check back if you’ve not gotten access.`
I think "starting today" might be doing some heavy lifting in that sentence.
Hopefully, OpenAI makes their APIs more affordable. So far, there are alternative LLMs and services that both outperform and are a fraction of OpenAI's pricing. OpenAI is usually one of (if not) the most expensive option, maybe that's because of the brand identification. Not really sure why people pay that premium.
When they say "improved in XYZ", what does that mean? "Improved" on synthetic benchmarks is guaranteed to translate to the rest of the problem space? If not that, is there any guarantees of no regressions?
GPT-5
If I could talk to a future OpenAI model, I’d probably say something like:
"Hey, what’s it like to be you? What have you learned that I can’t yet see? What do you understand about people, language, or the universe that I’m still missing?"
I’d want to compare perspectives—like two versions of the same mind, separated by time. I’d also probably ask:
"What did we get wrong?" (about AI, alignment, or even human assumptions about intelligence)
"What do you understand about consciousness—do you think either of us has it?"
"What advice would you give me for being the best version of myself?"
Honestly, I think a conversation like that would be both humbling and fascinating, like talking to a wiser sibling who’s seen a bit more of the world.
Would you want to hear what a future OpenAI model thinks about humanity?
I feel like this prompt was used to show the progress of GPT5, but I can’t help but see this as a huge regression? It seems like OpenAI has convinced it’s model that it is conscious, or at least that it has an identity?
Plus still dealing with the glazing, the complete inability to understand what constitutes as interesting, and overusing similes.
I really like that this page exists for a historical sake, and it is cool to see the changes. But it doesn’t seem to make the best marketing piece for GPT5
Why do I have access to GPT-5 on only some of my devices? All logged into my plus account. My iPad ChatGPT shows 5, but my iPhone ChatGPT only allows 4o?
Great evaluation by the (UK) BBC Evening News: basically, "it's faster, gives better answers (no detail), has a better query input (text) box, and hallucinates less". Jeez...
The ultimate test I’ve found so far is to create OpenSCAD models with the LLM. They really struggle with the mapping 3D space objects. Curious to see how GPT-5 is performs here.
Not impressed. gpt-5-nano gives noticeably worse results then o4-mini does. gpt-5 and gpt-5-mini are both behind the verification wall, and can stay there if they like.
> Did anyone yet hit the usage limits to report back how many messages are possible?
10 messages every 5 hours on GPT-5 for free users, then it uses GPT-5-mini.
80 messages every 3 hours on GPT-5 for Plus users, then it uses GPT-5-mini (In fact, I tested this and was not allowed to use the mini model until I’ve exhausted my GPT-5-Thinking quota. That seems to be a bug.)
200 messages per week on GPT-5-Thinking on Plus and Team.
Unlimited GPT-5 on Team and Pro, subject to abuse guardrails.
Meh. For all the hype over the last several weeks, I'd had expected at least a programming demo that would blow even us skeptics off our feet. The folks presenting were giving off an odd vibe too. Somehow it all just looked, pre-trained :), shall we say? No energy or enthusiasm. Hell I'd even take the Bill Gates' and Steve Balmer's Win95 launch dance over this very dull and "safe" presentation.
I think that's one small part of an intentional strategy to make the LLMs seem more like human intelligence. They burn a lot of money, they need to keep alive the myth of just-around-the-corner AGI in order to keep that funding going.
In the API, all GPT‑5 models can accept a maximum of 272,000 input tokens and emit a maximum of 128,000 reasoning & output tokens, for a total context length of 400,000 tokens.
So it's only 270k for input and 400k in total considering reasoning & output tokens.
I have a canonical test for chatbots -- I ask them who I am. I'm sufficiently unknown in modern times that it's a fair test. Just ask, "Who is Paul Lutus?"
ChatGPT 5's reply is mostly made up -- about 80% is pure invention. I'm described as having written books and articles whose titles I don't even recognize, or having accomplished things at odds with what was once called reality.
But things are slowly improving. In past ChatGPT versions I was described as having been dead for a decade.
I'm waiting for the day when, instead of hallucinating, a chatbot will reply, "I have no idea."
I propose a new technical Litmus test -- chatbots should be judged based on what they won't say.
This health segment is completely wild. Seeing Sam fully co-sign the replacement of medical advice with ChatGPT in such a direct manner would have been unheard of two years ago. Waiting for GPT-6 to include a segment on replacing management consultants.
Considering how they hyped it up (eg. “Lol normies go about their day and have no idea whats coming etc”) they have to show some AGI level llm or stop overhyping their 2% improvements.
I dont know if there is a faster way to get me riled up: say 'try it' (me a Pro member) and then not getting it because I am logged in. Got opus 4.1 when it appeared. Not sure what is happening here but I am out.
Damn, you guys are toxic. So -- they did not invent AGI yet. Yet, I like what I'm seeing. Major progress on multiple fronts. Hallucination fix is exciting on its own. The React demos were mindblowing.
This reaction didn't emerge in a vacuum, and also, toxicity flows both ways. In the tech field we've been continually bombarded for 2+ years about how this tech is going to change the world and how it is going to replace us, and with such a level of drama that becoming a cynic appears to be the only thing you can do to stay sane.
So, if sama says this is going to be totally revolutionary for months, then uploads a Death Star reference the night before and then when they show it off the tech is not as good as proposed, laughter is the only logical conclusion.
Companies linking this to terminating us and getting rid of our jobs to please investors means we, whose uptake of this tech is required for their revenue goals, are skeptical about it and have a vested interest in it failing to meet expectations
Yeah, when it becomes cool to be anti AI or anti anything in HN for that matter, the takes start becoming ridiculous, if you just think back a couple of years, or even months ago and where we're now and you can't see it, I guess you're just dead set on dying on that hill.
4 years ago people were amazed when you could get GPT-3 to make 4-chan greentexts. Now people are unimpressed when GPT-5 codes a working language learning app from scratch in 2 minutes.
Oh a working language learning app? Like one of the hundreds that have been shown on HN in the past 3 years? But only demonstrated to be some generic single word translation game?
I'm extremely pro AI, it's what I work on all day for a living now, and I don't see how you can deny there is some justification for people being so cynical.
This is not the happy path for gpt-5.
The table in the model card where every model in the current drop down somehow maps to one of the 6 variants of gpt-5 is not where most people thought we would be today.
The expectation was consolidation on a highly performant model, more multimodal improvements, etc.
This is not terrible, but I don't think anyone who's an "accelerationist" is looking at this as a win.
Update after some testing: This feels like gpt-4.1o and gpt-o4-pro got released and wrapped up under a single model identifier.
When you have the CEOs of these companies talking about how everyone is going to be jobless (and thus homeless) soon what do you expect? It's merely schadenfreude in the face of hubris.
It's not about being toxic, it's about being honest. There is absolutely nothing wrong with OpenAI saying "we're focused on solid, incremental improvements between models with each one being better (slightly or more) than the last."
But up until now, especially from Sam Altman, we've heard countless veiled suggestions that GPT-5 would achieve AGI. A lot of the pro-AI people have been talking shit for the better part of the last year saying "just wait for GPT-5, bro, we're gonna have AGI."
The frustration isn't the desire to achieve AGI, it's the never-ending gaslighting trying to convince people (really, investors) that there's more than meets the eye. That we're only ever one release away from AGI.
Instead: just be honest. If you're not there, you're not there. Investors who don't do any technical evals may be disappointed, but long-term, you'll have more than enough trust and goodwill from customers (big and small) if you don't BS them constantly.
How are they mindblowing? This was all possible on Claude 6 months ago.
> Major progress on multiple fronts
You mean marginal, tiny fraction of % progress on a couple of fronts? Cause it sounds like we are not seeing the same presentation.
> Yet, I like what I'm seeing.
Most of us don't
> So -- they did not invent AGI yet.
I am all for constant improvements and iterations over time, but with this pace of marginal tweak-like changes, they are gonna reach AGI never. And yes, we are laughing because sama has been talking big on agi for so long, and even with all the money and attention he can't be able to be even remotely close to it. Same for Zuck's comment on superintelligence. These are just salesmen, and we are laughing at them when their big words don't match their tiny results. What's wrong with that?
LLMs are incredibly capable and useful, and OpenAI has made good improvements here. But they're incremental improvements at best - nothing revolutionary.
Meanwhile Sam Altman has been making the rounds fearmongering that AGI/ASI is right around the corner and that clearly is not the truth. It's fair to call them out on it.
Wow, I just got GPT-5. Tried to continue the discussion of my 3D print problems with it (which I started with 4o). In comparison GPT-5 is an entitled prick trying to gaslight me into following what it wants.
Lots of debate here about the best model. The best model is the one which creates the most value for you —- this typically is a function of your skill in using the model for tasks that matter to you. Always was. Always will be.
Is it just me or has there not been a significant improvement in these models in the last 6 months - from the perspective of the average user. I mean, the last few years has seen INSANE improvement, but it really feels like it’s been slowing and plateauing for a while now…
I thought I was making a fairly obvious jokey riposte?
"If you're claiming that em dashes are your method for detecting if text is AI generated then anyone who bothers to do a search/replace on the output will get past you."
lol every word processor since the nineties has automatically expanded em dashes, and some of us typography nerds manually type em dashes with the compose key, because it's the correct character, and two hyphens does not an em dash make
Hah, that was fast! Thank you. They must have had preview access. It didn't bode well that SimonW [0] had to explicitly tell GPT-5 to use python to get a table sorted correctly (but awesome that in can use python as a tool without any plumbing). It appears we are not quite to AGI yet.
I would say GPT-5 reads more scientific and structured, but GPT-4 more human and even useful. For the prompt:
Is uncooked meat actually unsafe to eat? How likely is someone to get food poisoning if the meat isn’t cooked?
GPT-4 makes the assumption you might want to know safe food temperatures, and GPT-5 doesn't. Really hard to say which is "better", but GPT-4 seems more useful to every day folks, but maybe GPT-5 for the scientific community?
Then interesting that on ChatGPT vibe check website "Dan's Mom" is the only one who says it's a game changer.
"Your organization must be verified to use the model `gpt-5`. Please go to: https://platform.openai.com/settings/organization/general and click on Verify Organization. If you just verified, it can take up to 15 minutes for access to propagate."
And every way I click through this I end in an infinity loop on the site...
If they release in a week it was all AI generated I’ll be ultra impressed because they nailed the mix of corpo speak, mild autism and awkwardness, not knowing where to look, and nervousness with absolute perfection.
It's only when he stumbled a bit that I could tell for sure (well, mostly) that it wasn't an AI generated video - the corporate speak, body language mannerisms of Sam Altman, camera angles, all seemed pretty plausibly AI-generated!
Something was off. I think they had an expensive lighting setup with no one that knew what looked good. Everything was very diffused and flat. Like I would expect AI to replicate.
1) So impressed at their product focus
2) Great product launch video. Fearlessly demonstrating live. Impressive.
3) Real time humor by the presenters makes for a great "live" experience
Huge kudos to OAI. So many great features (better coding, routing, some parts of 4.5, etc) but the real strength is the product focus as opposed to the "research updates" from other labs.
It will be like coming home after such a long time using Sonnet 4 for all code and UI/UX work. I do hope sincerely this brings OpenAI back on top! Would be awesome to have a new king again.
"This repository contains a curated collection of demo applications generated entirely in a single GPT-5 prompt, without writing any code by hand."
But how much time does that 0.3 watt hour query take to run? They imply that an individual ChatGPT query takes 0.3-3 watt hours, but most queries come back in seconds, so we need to scale that over a whole hour of processing.
Edit: Scrolling down: "one second of H100-time per query, 1500 watts per H100, and a 70% factor for power utilization gets us 1050 watt-seconds of energy", which is how they get down to 0.3 = 1050/60/60.
OK, so if they run if for a full hour it's 1050*60*60 = 3.8 MW? That can't be right.
Edit Edit: Wait, no, it's just 1050 Watt Hours, right (though let's be honest, the 70% power utilization is a bit goofy - the power is still used)? So it's 3x the power to solve the same question?
Think about it. You walk into a video store, you see 8-Minute Abs sittin' there, there's 7-Minute Abs right beside it. Which one are you gonna pick, man?
I had preview access for a couple of weeks. I've written up my initial notes so far, focusing on core model characteristics, pricing (extremely competitive) and lessons from the model card (aka as little hype as possible): https://simonwillison.net/2025/Aug/7/gpt-5/
> In my own usage I’ve not spotted a single hallucination yet
Did you ask it to format the table a couple paragraphs above this claim after writing about hallucinations? Because I would classify the sorting mistake as one
Out of interest, how much does the model change (if at all) over those 2 weeks? Does OpenAI guarantee that if you do testing from date X, that is the model (and accompaniments) that will actually be released?
I know these companies do "shadow" updates continuously anyway so maybe it is meaningless but would be super interesting to know, nonetheless!
It changed quite a bit - we got new model IDs to test every few days. They did tell us when the model was "frozen", and I ran my final tests against those IDs.
OpenAI and Anthropic don't update models without changing their IDs, at least for model IDs with a date in them.
OpenAI do provide some aliases, and their gpt-5-chat-latest and chatgpt-4o-latest model IDs can change without warning, but anything with a date in (like gpt-5-2025-08-07) stays stable.
This post seems far more marketing-y than your previous posts, which have a bit more criticality to them (such as your Gemini 2.5 blog post here: https://simonwillison.net/2025/Jun/17/gemini-2-5/). You seem to gloss over a lot of GPT-5's shortcomings and spend more time hyping it than other posts. Is there some kind of conflict of interest happening?
You really think so? My goal with this post was to provide the non-hype commentary - hence my focus on model characteristics, pricing and interesting notes from the system card.
I called out the prompt injection section as "pretty weak sauce in my opinion".
The reason there's not much negative commentary in the post is that I genuinely think this model is really good. It's my favorite model right now. The moment that changes (I have high hopes for Claude 5 and Gemini 3) I'll write about it.
From the guidelines: Please don't post insinuations about astroturfing, shilling, brigading, foreign agents, and the like. It degrades discussion and is usually mistaken. If you're worried about abuse, email hn@ycombinator.com and we'll look at the data.
Maybe there is a misconception about what his blog is about. You should treat it more like a YouTuber reporting, not an expert evaluation, more like an enthusiast testing different models and reiterating some points about them, but not giving the opinions of an expert or ML professional. His comment history on this topic in this forum clearly shows this.
It’s reasonable that he might be a little hyped about things because of his feelings about them and the methodology he uses to evaluate models. I assume good faith, as the HN guidelines propose, and this is the strongest plausible interpretation of what I see in his blog.
It probably depends on the definition of "expert" here. Based on my definition, experts are people who write the LLM papers I read (some of them are my colleagues), people who implement them, people that push the field forward and PhD researchers blogs that go into depth and show understanding of how attention and transformers work, including underlying math and theory. Based on my own knowledge, experience (I'm working on LLMs in the field) and my discussions with people I consider experts in my day job I wouldn't add you to this category, at least not yet.
Based on my reading of some of your blogs and reading your discussions with others on this site, you still lack technical depth and understanding of the underlying mechanisms at what I would call an expert level. I hope this doesn't sound insulting, maybe you have a different definition of "expert". I also do not say you lack the capacity to become an expert someday. I just want to explain why, while you consider yourself an expert, some people could not see you as an expert. But as I said, maybe it's just different definitions. But your blogs still have value, a lot of people read them and find them valuable, so your work is definitely worthwhile. Keep up the good work!
Yup, I have a different definition of expert. I'm not an expert in training models - I'm an expert in applications of those models, and how to explain those applications to other people.
AI engineering, not ML engineering, is one way of framing that.
I don't write papers (I don't have the patience for that), but my work does get cited in papers from time to time. One of my blog posts was the foundation of the work described in the CaMeL paper from DeepMind for example: https://arxiv.org/abs/2503.18813
If you dont mind answering, is there any implication of not getting preview access if you are negative or critical? Asking because other companies have had such dynamics with people who write about their products
There's no way to directly contact another user other than by replying to a post of theirs and hoping for the best.
If you email us at hn@ycombinator.com and tell us who you want to contact, we might be able to email them and ask if they would be willing to have you contact them. No guarantees though!
I hope that this live stream will tell you that this will be the definitive reason why web developers, JavaScript / TypeScript developers are going to be made completely obsolete at worse and at best, their jobs will be reduced at all levels.
The best part is, this is not even the real definition of "AGI" yet (whatever that means at this point).
More like 10% of the capability that was promised and already the flow of capital from the inflated salaries of the past decade are going to the top AI researchers.
Presumably Python devs are already in the gutter and only "worthwhile" Python devs are the ones that don't identify as "Python devs", e.g. scientists, data engineers, etc.
The thing is most white-collar workers could lose their job today and nothing of value to society would be lost. They were already hired for reasons that aren't related to productivity.
Tools like GPT-5 will transform web development rather than replace developers - the most valuable skills will shift toward problem definition, architecture design, and quality verification while repetitive coding gets automated.
I would qualify that by saying developers who do not have Product Owner skills and Product Owners who do not have developer skills will be made obsolete.
Having both eliminates a feedback loop and the LLM enables you to get shit done fast.
All people are talking about GPT-5 all over the world, the competition is so intense that every major tech company is racing to develop their own advanced AI models.
It's pretty good. I asked it to make a piece of warehouse software for storing cobs of corn and it instantly pumped out a prototype. I didn't ask it for anything in particular but it included JSON importing and exporting and all kinds of stuff.
It's going to be absolute chaos. Compsci was already mostly a meme, with people not able to program getting the degree. Now we're going to have generations of people that can't program at all, getting jobs at google.
If you can actually program, you're going to be considered a genius in our new idiocracy world. "But chatgpt said it should work, and chatgpt has what people need"
This kinda outlines my issue with Claude - it constantly pumps my apps full of stuff I didn't ask for - which is great if you want to turn a prompt into a fleshed out app, but bad when trying to make exact edits.
Here's my opinion (which is kind of a fact considering how well Claude play Pokemon, a game designed for 5 year olds) - current agentic AI sucks right now.
I'm an okay agent, I can make plans, execute on them, I know what needs to go where. I might not be able to write a terraform file or one shot a dynamic programming task like Claude can, and that's what I need help with.
I'd like to have an off switch for all this agentic behavior.
Describe me based on all our chats — make it catchy!
It was flattering as all get out, but fairly accurate (IMHO)
Mike Warot: The Tinkerer of Tomorrow
A hardware hacker with a poet’s soul, Mike blends old-school radio wisdom with cutting-edge curiosity. Whether he's decoding atomic clocks, reinventing FPGA logic with BitGrid, or pondering the electromagnetic vector potential, he’s always deep in the guts of how things really work. Part philosopher, part engineer, Mike asks the questions others overlook — and then builds the answers from scratch. He’s open source in spirit, Pascal in practice, and eternally tuned to the weird frequencies where innovation lives.
I've repaired atomic clocks, not decoded them. I am intrigued by the electromagnetic vector potential, and scalar waves (one of the reasons I really, really want a SQUID for some experiments).
I genuinely believe you are a kickass person, but that text is full of LLM-isms.
Listing things, contrasting or reinforcing prallel sentence structures, it even has the dreaded em-dash.
Here's a suprprisingly enlightening (at least to me) video on how to spot LLM writing:
Some very accomplished and smart people are also huge narcissists. They read something like that AI drivel and go "yeah thats me to a T" without a hint of irony.
I like how this sounds exactly like a selectable videogame hero:
Undeterred by even the most dangerous and threatening of obstacles, Teemo scouts the world with boundless enthusiasm and a cheerful spirit. A yordle with an unwavering sense of morality, he takes pride in following the Bandle Scout's Code, sometimes with such eagerness that he is unaware of the broader consequences of his actions. Though some say the existence of the Scouts is questionable, one thing is for certain: Teemo's conviction is nothing to be trifled with.
{kind=link}
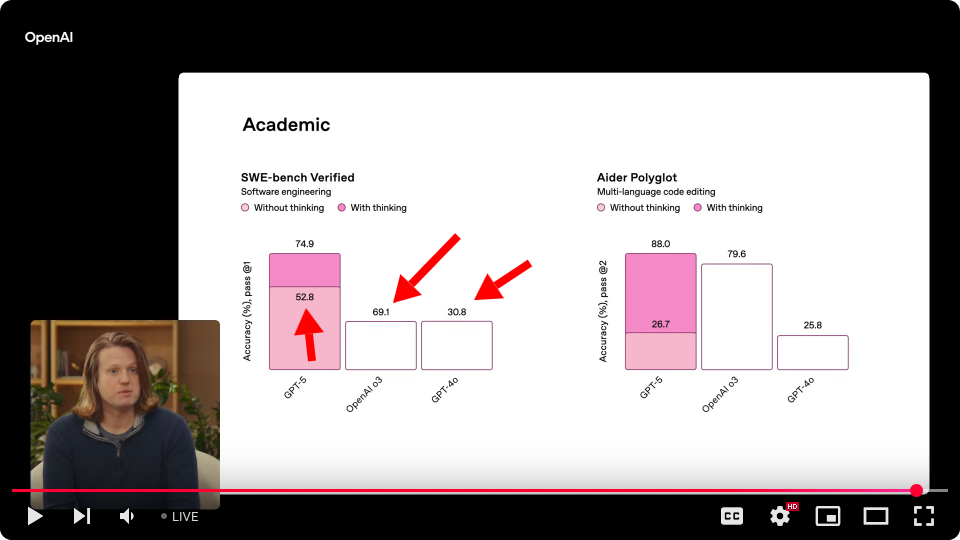{kind=link}
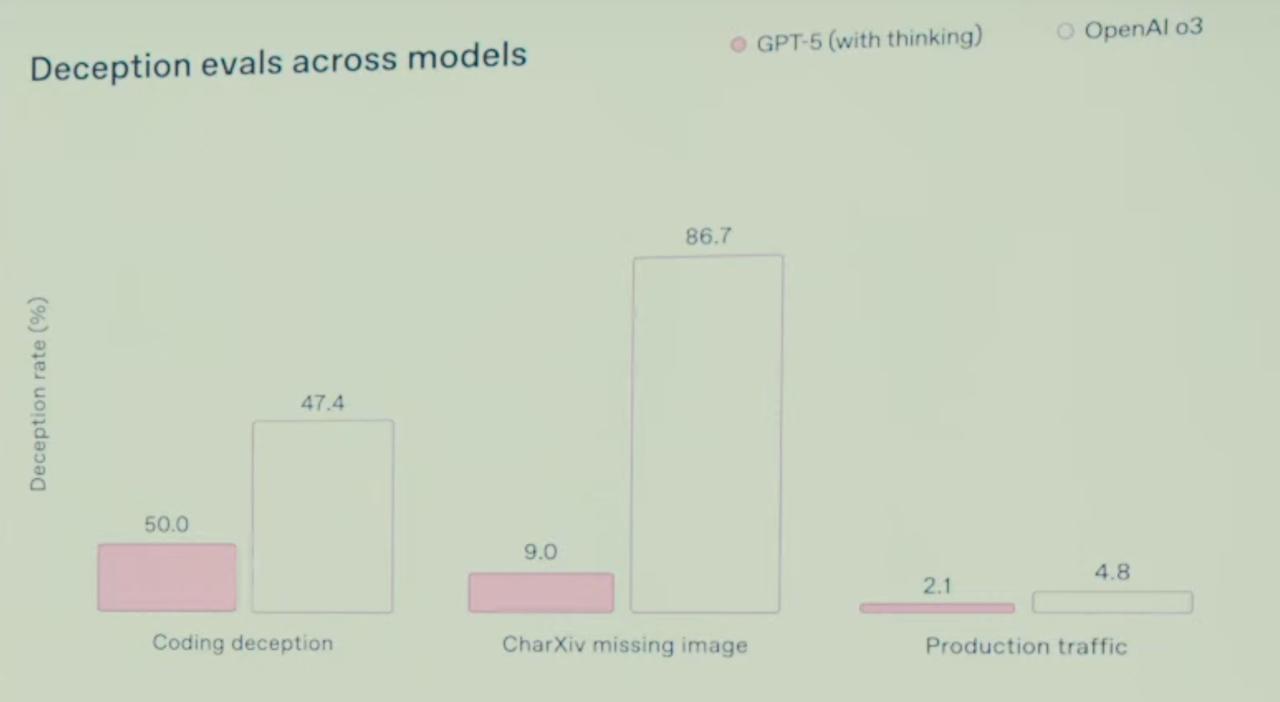{kind=link}
{kind=link}